1. Spring Batch 介绍
企业域内的许多应用程序都需要批量处理才能在关键任务环境中执行业务操作。这些业务操作包括自动化,复杂的海量信息处理,无需用户交互即可最有效地进行处理。这些操作通常包括基于时间的事件(例如,月末计算,通知或通信),周期性应用非常大的数据集重复处理的复杂业务规则(例如,保险利益确定或费率调整)或所接收信息的集成从通常需要以事务处理方式进行格式化,验证和处理的内部和外部系统进入记录系统。批处理每天用于为企业处理数十亿笔事务。
Spring Batch 是一个轻量级的,全面的批处理框架,旨在支持开发对企业系统的日常运行至关重要的强大的批处理应用程序。 Spring Batch 构建在生产力,基于 POJO 的开发方法以及人们从 Spring 框架中了解到的通用易用性的基础之上,同时使开发人员在必要时可以轻松访问和利用更高级的企业服务。 Spring Batch 不是一个调度框架。商业和开放源代码空间(例如 Quartz,Tivoli,Control-M 等)中都有许多好的企业调度程序。它旨在与调度程序结合使用,而不是替换调度程序。
Spring Batch 提供了可重用的功能,这些功能对于处理大量记录至关重要,包括日志记录/跟踪,事务 Management,作业处理统计信息,作业重启,跳过和资源 Management。它还提供了更高级的技术服务和功能,这些功能和功能将通过优化和分区技术来实现极高容量和高性能的批处理作业。简单以及复杂的大批量批处理作业都可以以高度可扩展的方式利用框架来处理大量信息。
1.1 Background
尽管开源软件 Item 和相关社区将更多的注意力放在基于 Web 的和基于 SOA 消息传递的架构框架上,但是尽管满足了持续的处理需求,但是对于可重用的架构框架却缺乏足够的关注以适应基于 Java 的批处理需求。企业 IT 环境中的此类处理。缺乏标准的,可重复使用的批处理体系结构,导致在 Client 端企业 IT 功能内开发的许多一次性内部解决方案激增。
SpringSource 和埃森哲合作进行了更改。埃森哲(Accenture)在实现批处理体系结构方面的动手行业和技术经验,SpringSource 的深厚技术经验以及 Spring 久经验证的编程模型共同标志着自然而强大的合作伙伴关系,以创建旨在填补企业 Java 重要缺口的高质量,与市场相关的软件。两家公司目前还与许多 Client 合作,共同开发基于 Spring 的批处理体系结构解决方案,以解决类似的问题。这提供了一些有用的附加细节和现实生活中的约束条件,有助于确保解决方案可以应用于 Client 提出的现实问题。由于这些原因,SpringSource 和埃森哲(Accenture)携手合作,共同开发 Spring Batch。
埃森哲基于数十年在使用最后几代平台(例如,COBOL/Mainframe,C/Unix,现在是 Java /任何地方)构建批处理架构方面的经验,为 Spring BatchItem 贡献了以前专有的批处理架构框架。以及提交者资源,以推动支持,增强功能和 FutureRoute 图。
埃森哲与 SpringSource 的合作旨在促进软件处理方法,框架和工具的标准化,企业用户在创建批处理应用程序时可以一致地利用它们。希望为企业 IT 环境提供标准的,经过验证的解决方案的公司和政府机构将从 Spring Batch 中受益。
1.2 使用场景
典型的批处理程序通常从数据库,文件或队列中读取大量记录,以某种方式处理数据,然后以修改后的形式写回数据。 Spring Batch 自动执行此基本批处理迭代,从而提供了将一组类似的事务作为一组处理的功能,通常在脱机环境中无需任何用户交互。批处理作业是大多数 ITItem 的一部分,Spring Batch 是唯一提供可靠的企业级解决方案的开源框架。
Business Scenarios
- 定期提交批处理
- 并行批处理:作业的并行处理
- 分阶段的企业消息驱动的处理
- 大规模并行批处理
- 失败后手动或计划重启
- Sequences 处理相关步骤(扩展了工作流程驱动的批次)
- 部分处理:跳过记录(例如回滚)
- 整批事务:适用于小批量或现有存储过程/脚本的情况
Technical Objectives
- 批处理开发人员使用 Spring 编程模型:专注于业务逻辑;让框架照顾基础架构。
- 在基础结构,批处理执行环境和批处理应用程序之间明确分离关注点。
- 提供通用的核心执行服务作为所有 Item 都可以实现的接口。
- 提供可以直接使用的核心执行接口的简单和默认实现。
- 通过在所有层中利用 spring 框架,轻松配置,定制和扩展服务。
- 所有现有的核心服务应易于替换或扩展,而不会影响基础架构层。
- 提供一个简单的部署模型,其架构 JAR 与使用 Maven 构建的应用程序完全分开。
1.3 Spring Batch 体系结构
Spring Batch 设计时考虑了可扩展性,并考虑了不同的最终用户群体。下图显示了分层体系结构的草图,该结构支持最终用户开发人员的可扩展性和易用性。
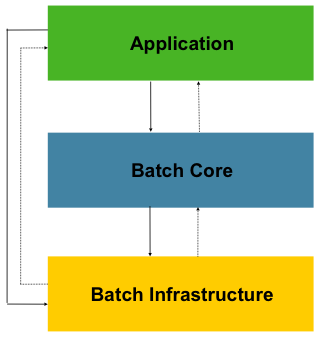
图 1.1:Spring Batch 分层架构
这种分层的体系结构突出了三个主要的高级组件:应用程序,核心和基础结构。该应用程序包含所有批处理作业和开发人员使用 Spring Batch 编写的自定义代码。批处理核心包含启动和控制批处理作业所需的核心运行时类。它包括诸如JobLauncher,Job和Step的实现。 Application 和 Core 都构建在通用基础架构之上。此基础结构包含通用的读取器和写入器,以及RetryTemplate之类的服务,应用程序开发人员(ItemReader和ItemWriter)以及核心框架本身都使用它们。 (重试)
1.4 一般批处理原则和准则
以下是构建批处理解决方案时要考虑的一些关键原则,准则和一般注意事项。
- 批处理体系结构通常会影响在线体系结构,反之亦然。在可能的情况下,请使用通用的构建块同时考虑架构和环境进行设计。
- 尽可能简化并避免在单个批处理应用程序中构建复杂的逻辑结构。
- 处理数据时应尽可能靠近其物理位置(反之亦然)(即,将数据保留在进行处理的位置)。
- 最小化系统资源的使用,尤其是 I/O。在内存中执行尽可能多的操作。
- 查 Watch 应用程序 I/O(分析 SQL 语句)以确保避免不必要的物理 I/O。特别是,需要寻找以下四个常见缺陷:
- 当可以一次读取数据并将其缓存或保存在工作存储器中时,为每个事务读取数据;
- 重新读取事务的数据,其中在同一事务中较早读取了该数据;
- 导致不必要的表或索引扫描;
- 没有在 SQL 语句的 WHERE 子句中指定键值。
- 请勿在批处理中两次执行操作。例如,如果出于报告目的需要数据汇总,则在初始处理数据时,如果可能,请增加存储的总数,因此报告应用程序不必重新处理相同的数据。
- 在批处理应用程序开始时分配足够的内存,以避免在此过程中耗时的重新分配。
- 关于数据完整性,请始终假设最坏的情况。插入足够的检查并记录验证以维护数据完整性。
- 实施校验和以进行内部验证。例如,平面文件应具有预告片记录,以告知文件中的记录总数以及关键字段的集合。
- 在具有实际数据量的类似生产的环境中,尽早计划和执行压力测试。
- 在大型批处理系统中,备份可能具有挑战性,尤其是当系统以 24-7 联机联机运行时。在线设计中通常会妥善处理数据库备份,但是文件备份也应同样重要。如果系统依赖平面文件,则不仅应构建文件备份程序并形成文件,还应进行定期测试。
1.5 批处理策略
为了帮助设计和实现批处理系统,应以示例结构图和代码 Shell 的形式向设计人员和程序员提供基本的批处理应用程序构建模块和模式。在开始设计批处理作业时,应将业务逻辑分解为一系列步骤,可以使用以下标准构件来实现:
- *转换应用程序:*对于由外部系统提供或生成的每种文件类型,都需要创建一个转换应用程序,以将提供的事务记录转换为处理所需的标准格式。这种批处理应用程序可以部分或全部由翻译 Util 模块组成(请参阅基本批处理服务)。
- *验证应用程序:*验证应用程序可确保所有 Importing/输出记录正确且一致。验证通常基于文件头和尾标,校验和和验证算法以及记录级别的交叉检查。
- *提取应用程序:*一个应用程序,它从数据库或 Importing 文件中读取一组记录,根据 sched 义的规则选择记录,然后将记录写入输出文件。
- *提取/更新应用程序:*一个应用程序,它从数据库或 Importing 文件中读取记录,并根据每个 ImportingLogging 找到的数据来驱动对数据库或输出文件的更改。
- *处理和更新应用程序:*一个应用程序,用于对来自摘录或验证应用程序的 Importing 事务进行处理。处理通常将涉及读取数据库以获得处理所需的数据,可能会更新数据库并创建记录以进行输出处理。
- *输出/格式应用程序:*应用程序读取 Importing 文件,根据标准格式从该 Logging 重组数据,并生成输出文件以供打印或传输到另一个程序或系统。
此外,应为无法使用前面提到的构建块构建的业务逻辑提供基本的应用程序 Shell。
除主要构建块外,每个应用程序都可以使用一个或多个标准 Util 步骤,例如:
- 排序-一种程序,该程序读取 Importing 文件并生成输出文件,其中已根据 Logging 的排序键字段对记录进行了重新排序。排序通常由标准系统 Util 执行。
- 拆分-一种程序,它读取一个 Importing 文件,并根据字段值将每个记录写入几个输出文件之一。拆分可以由参数驱动的标准系统 Util 定制或执行。
- 合并-一种程序,可从多个 Importing 文件中读取记录,并使用 Importing 文件中的合并数据生成一个输出文件。合并可以通过参数驱动的标准系统 Util 来定制或执行。
批处理应用程序还可以按其 Importing 源进行分类:
- 数据库驱动的应用程序由从数据库检索的行或值驱动。
- 文件驱动的应用程序由从文件中检索的记录或值驱动。
- 消息驱动的应用程序由从消息队列检索的消息驱动。
任何批处理系统的基础都是处理策略。影响策略选择的因素包括:估计的批处理系统数量,与联机或其他批处理系统的并发性,可用的批处理窗口(以及更多希望以 24x7 全天候运行的企业,因此没有明显的批处理窗口)。
批处理的典型处理选项是:
- 脱机期间在批处理窗口中进行正常处理
- 并行批处理/在线处理
- 同时并行处理许多不同的批生产或作业
- 分区(即同时处理同一作业的许多实例)
- 这些的结合
上面列表中的 Sequences 反映了实现的复杂性,在批处理窗口中的处理最容易实现,而对分区的实现最复杂。
商业调度程序可能会支持其中一些或全部选项。
在以下部分中,将详细讨论这些处理选项。重要的是要注意,批处理过程采用的提交和锁定策略将取决于执行的处理类型,并且根据经验,在线锁定策略也应使用相同的原理。因此,在设计整体体系结构时,批处理体系结构不能仅是事后的想法。
锁定策略只能使用普通数据库锁定,或者可以在体系结构中实现其他自定义锁定服务。锁定服务将跟踪数据库锁定(例如,通过将必要的信息存储在专用的 db 表中),并为请求 db 操作的应用程序提供或拒绝权限。此体系结构也可以实现重试逻辑,以避免在锁定情况下中止批处理作业。
1.批处理窗口中的正常处理 对于在单独的批处理窗口中运行的简单批处理过程,在线用户或其他批处理过程不需要更新数据,并发不是问题,可以在以下位置进行一次提交批处理运行结束。
在大多数情况下,更健壮的方法更为合适。要记住的是,批处理系统会随着时间的流逝而增长,无论是从复杂性还是要处理的数据量来 Watch。如果没有锁定策略,并且系统仍依赖单个提交点,则修改批处理程序可能会很麻烦。因此,即使使用最简单的批处理系统,也要考虑需要重新启动-恢复选项的提交逻辑以及有关以下更复杂情况的信息。
2.并行批处理/在线处理 处理在线用户可以同时更新的数据的批处理应用程序,不应锁定在线用户可能需要的任何数据(数据库或文件中的数据)几秒钟。同样,在每笔事务结束时,更新也应提交给数据库。这样可以将其他进程不可用的数据部分和数据不可用的经过时间最小化。
最小化物理锁定的另一种方法是使用乐观锁定模式或悲观锁定模式来实现逻辑行级锁定。
- 乐观锁定假定记录争用的可能性很小。通常,这意味着在批处理和联机处理同时使用的每个数据库表中插入一个时间戳列。当应用程序获取一行进行处理时,它还将获取时间戳。然后,当应用程序尝试更新已处理的行时,更新将使用 WHERE 子句中的原始时间戳。如果时间戳匹配,则数据和时间戳将成功更新。如果时间戳不匹配,则表明另一个应用程序已经更新了获取和更新尝试之间的同一行,因此无法执行更新。
- 悲观锁定是任何假定记录争用可能性很高的锁定策略,因此需要在检索时获得物理或逻辑锁定。一种悲观逻辑锁定使用数据库表中的专用锁定列。当应用程序检索要更新的行时,它将在锁列中设置一个标志。有了该标志,其他尝试检索同一行的应用程序在逻辑上将失败。当设置标志的应用程序更新该行时,它还会清除该标志,从而使该行可以被其他应用程序检索。请注意,在初始获取和设置标志之间还必须保持数据的完整性,例如通过使用 db 锁(例如 SELECT FOR UPDATE)。还要注意,该方法与物理锁定有相同的缺点,除了 Management 超时机制要容易一些,该机制可以在锁定记录的情况下在用户午餐时释放锁定。
这些模式不一定适用于批处理,但可以用于并发批处理和联机处理(例如,在数据库不支持行级锁定的情况下)。通常,乐观锁定更适合于在线应用程序,而悲观锁定更适合于批处理应用程序。每当使用逻辑锁定时,必须对访问逻辑锁定保护的数据实体的所有应用程序使用相同的方案。
请注意,这两种解决方案都只解决锁定单个记录的问题。通常,我们可能需要锁定逻辑上相关的记录组。使用物理锁,您必须非常仔细地 Management 这些锁,以避免潜在的死锁。使用逻辑锁,通常最好构建一个逻辑锁 Management 器,该 Management 器了解要保护的逻辑记录组,并可以确保锁是连贯的和非死锁的。此逻辑锁 Management 器通常使用自己的表进行锁 Management,争用报告,超时机制等。
3.并行处理 并行处理允许多个批处理运行/作业并行运行,以最大程度地减少总的批处理处理时间。只要作业不共享相同的文件,数据库表或索引空间,就没有问题。如果这样做,则应使用分区数据来实现此服务。另一种选择是构建一个架构模块,以使用控制表来维护相互依赖性。控制表应为每个共享资源及其是否由应用程序使用而包含一行。然后,批处理体系结构或并行作业中的应用程序将从该表中检索信息,以确定它是否可以访问所需的资源。
如果数据访问没有问题,则可以通过使用其他线程进行并行处理来实现并行处理。在大型机环境中,传统上使用并行作业类,以确保所有进程有足够的 CPU 时间。无论如何,该解决方案必须足够强大以确保所有正在运行的进程的时间片。
并行处理中的其他关键问题包括负载平衡和常规系统资源(例如文件,数据库缓冲池等)的可用性。还请注意,控制表本身很容易成为关键资源。
4.分区 使用分区允许大型批处理应用程序的多个版本同时运行。这样做的目的是减少处理长批处理作业所需的时间。可以成功分区的进程是可以拆分 Importing 文件和/或对主数据库表进行分区以允许应用程序针对不同的数据集运行的进程。
此外,已分区的进程必须设计为仅处理其分配的数据集。分区体系结构必须与数据库设计和数据库分区策略紧密联系在一起。请注意,数据库分区不一定意味着数据库的物理分区,尽管在大多数情况下这是可取的。下图说明了分区方法:
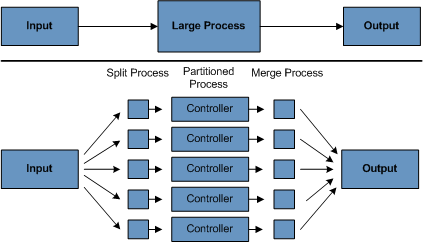
图 1.2:分区过程
该架构应足够灵活,以允许动态配置分区数量。自动配置和用户控制配置均应考虑。自动配置可以基于诸如 Importing 文件大小和/或 Importing 记录数之类的参数。
4.1 分区方法 以下列出了一些可能的分区方法。选择分区方法必须根据具体情况进行。
- 1.记录集的固定和均匀分解*
这涉及将 Importing 记录集分成偶数个部分(例如 10 个,其中每个部分恰好占整个记录集的 1⁄10)。然后由批处理/提取应用程序的一个实例处理每个部分。
为了使用此方法,将需要进行预处理以拆分记录集。拆分的结果将是一个上下限放置数,可以将其用作批处理/提取应用程序的 Importing,以便将其处理仅限于其部分。
预处理可能会产生很大的开销,因为它必须计算并确定记录集每个部分的界限。
- 2.按关键列细分*
这涉及通过键列(例如位置代码)分解 Importing 记录集,并将每个键的数据分配给批处理实例。为了实现这一点,列值可以是
- 3.通过分区表分配给批处理实例(有关详细信息,请参见下文).*
- 4.通过部分值(例如值 0000-0999、1000-1999 等)分配给批处理实例*
在选项 1 下,添加新值将意味着手动重新配置批次/提取,以确保将新值添加到特定实例。
在选项 2 下,这将确保通过批处理作业实例覆盖所有值。但是,由一个实例处理的值的数量取决于列值的分布(即,在 0000-0999 范围内可能有大量位置,而在 1000-1999 范围内可能很少)。在此选项下,数据范围的设计应考虑分区。
在这两种选择下,都无法实现记录到批处理实例的最佳均匀分配。没有动态配置所使用的批处理实例的数量。
- 5.按观 Watch 次数细分*
这种方法基本上是按键列拆分的,但是在数据库级别。它涉及将记录集分解为视图。批处理应用程序的每个实例在处理过程中将使用这些视图。分解将通过对数据进行分组来完成。
使用此选项,必须将批处理应用程序的每个实例配置为命中特定视图(而不是主表)。同样,随着新数据值的添加,该新数据组将必须包含在视图中。没有动态配置功能,因为实例数量的更改将导致视图的更改。
- 6.添加加工 Metrics*
这涉及在 Importing 表中添加一个新列,该列用作指示符。作为预处理步骤,所有 Metrics 都将标记为未处理。在批处理应用程序的记录获取阶段,将以该记录被标记为未处理的条件来读取记录,并且一旦读取(带锁)它们便被标记为正在处理。该记录完成后,指示符将更新为完成或错误。批处理应用程序的许多实例无需更改即可启动,因为附加列可确保记录仅处理一次。
使用此选项,表上的 I/O 会动态增加。在更新批处理应用程序的情况下,这种影响会减小,因为无论如何都要进行写操作。
- 7.将表提取到平面文件*
这涉及将表提取到文件中。然后可以将此文件拆分为多个段,并用作批处理实例的 Importing。
使用此选项,将表提取到文件中并进行拆分的额外开销可能会抵消多分区的影响。通过更改文件分割脚本可以实现动态配置。
- 8.哈希列的使用*
此方案涉及在用于检索驱动程序记录的数据库表中添加哈希列(键/索引)。该哈希列将具有指示符,用于确定批处理应用程序的哪个实例将处理此特定行。例如,如果有三个批处理实例要启动,则指示符“ A”将标记该行以供实例 1 处理,指示符“ B”将标记该行以供实例 2 处理,以此类推。
然后,用于检索记录的过程将具有一个附加的 WHERE 子句,以选择由特定指示符标记的所有行。此表中的插入内容将涉及添加标记字段,该字段默认为实例之一(例如’A’)。
一个简单的批处理应用程序将用于更新 Metrics,例如在不同实例之间重新分配负载。添加足够多的新行后,可以运行该批处理(除批处理窗口外,任何时候均可)将新行重新分配给其他实例。
批处理应用程序的其他实例仅需要运行上述批处理应用程序即可重新分配指示符,以适应新的实例数量。
4.2 数据库和应用程序设计原则
支持使用键列方法针对分区数据库表运行的多分区应用程序的体系结构应包括用于存储分区参数的中央分区存储库。这提供了灵 Active 并确保了可维护性。该存储库通常由一个称为分区表的表组成。
存储在分区表中的信息将是静态的,并且通常应由 DBA 维护。该表应包含一个信息行,用于多分区应用程序的每个分区。该表应包含以下列:程序 ID 代码,分区号(分区的逻辑 ID),该分区的 db 键列的低值,此分区的 db 键列的高值。
在程序启动时,应将程序 ID 和分区号从体系结构传递到应用程序(控制处理任务集)。这些变量用于读取分区表,以确定应用程序要处理的数据范围(如果使用键列方法)。此外,在整个处理过程中必须使用分区号以:
- 添加到输出文件/数据库更新中以使合并过程正常运行
- 将正常处理报告给批处理日志,并将在执行过程中发生的任何错误报告给体系结构错误处理程序
4.3 最小化死锁
当应用程序并行或分区运行时,数据库资源争用和死锁可能发生。至关重要的是,数据库设计团队应尽可能消除潜在的争用情况,这是数据库设计的一部分。
还要确保数据库索引表在设计时考虑了防止死锁和性能。
死锁或热点通常发生在 Management 或体系结构表中,例如日志表,控制表和锁定表。还应考虑这些含义。实际的压力测试对于确定体系结构中的可能瓶颈至关重要。
为了最大程度地减少冲突对数据的影响,体系结构应在连接到数据库或遇到死锁时提供诸如 await 和重试间隔之类的服务。这意味着内置机制可以对某些数据库返回码作出反应,而不是立即发出错误处理,而是 awaitsched 时间并重试数据库操作。
4.4 参数传递和验证
分区体系结构对于应用程序开发人员应该相对透明。该体系结构应执行与在分区模式下运行应用程序相关的所有任务,包括:
- 在应用程序启动之前检索分区参数
- 在应用程序启动之前验证分区参数
- 在启动时将参数传递给应用程序
验证应包括检查以确保:
- 该应用程序具有足够的分区来覆盖整个数据范围
- 分区之间没有间隙
如果数据库已分区,则可能需要进行一些其他验证,以确保单个分区不会跨越数据库分区。
此外,体系结构还应考虑分区的合并。关键问题包括:
- 在进入下一个作业步骤之前,是否必须完成所有分区?
- 如果其中一个分区中止会怎样?
2. Spring Batch 3.0 的新功能
Spring Batch 3.0 版本具有五个主要主题:
- JSR-352 Support
- 升级以支持 Spring 4 和 Java 8
- 将 Spring Batch 集成到 Spring Batch
- JobScope Support
- SQLite Support
2.1 JSR-352 支持
JSR-352 是用于批处理的新 Java 规范。受 Spring Batch 的启发,此规范提供了与 Spring Batch 已支持的功能类似的功能。但是,Spring Batch 3.0 已经实现了该规范,并且现在支持符合该标准的批处理作业的定义。使用 JSR-352 的作业规范语言(JSL)配置的批处理作业示例如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<job id="myJob3" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="step1" >
<batchlet ref="testBatchlet" />
</step>
</job>
有关更多详细信息,请参见第JSR-352 Support节。
2.2 将 Spring Batch 集成到 Spring Batch
数年来,Spring Batch 集成一直是 Spring Batch AdminItem 的子模块。它提供的功能可以更好地集成 Spring Integration 和 Spring Batch 中提供的功能。具体功能包括:
- 通过消息启动作业
- 异步
ItemProcessors - 提供信息消息反馈
- 通过远程分区和远程组块外部化批处理执行
有关详细信息,请参见第Spring 批处理集成节。
2.3 升级以支持 Spring 4 和 Java 8
随着将 Spring Batch Integration 提升为 Spring BatchItem 的模块,已对其进行了更新以使用 Spring Integration4.SpringIntegration 4 将核心消息传递 API 移至了 Spring 核心。因此,Spring Batch 3 现在将需要 Spring 4 或更高版本。
作为此主要版本中发生的依赖关系更新的一部分,Spring Batch 现在支持在 Java 8 上运行。它仍将在 Java 6 或更高版本上执行。
2.4 JobScope 支持
Spring Batch 中使用的 Spring 作用域“步骤”在批处理应用程序中起着举足轻重的作用,长期以来提供后期绑定功能。在 3.0 版本中,Spring Batch 现在支持“作业”范围。这个新范围允许延迟构造对象,直到实际启动 Job 为止,并为每次执行 Job 的新实例提供便利。您可以在第 5.4.2 节“工作范围”部分中阅读有关此新 bean 范围的详细信息。
2.5 SQLite 支持
通过为 SQLite 添加作业存储库 ddl,已为JobRepository添加了 SQLite 作为新支持的数据库选项。这提供了一个有用的,基于文件的数据存储以用于测试。
1. Spring Batch 4.1 的新增功能
Spring Batch 4.1 版本增加了以下功能:
- 新的
@SpringBatchTestComments 可简化批处理组件的测试 - 新的
@EnableBatchIntegrationComments 可简化远程组块和分区配置 - 新的
JsonItemReader和JsonFileItemWriter支持 JSON 格式 - 添加对使用 Bean 验证 API 验证 Item 的支持
- 添加对 JSR-305Comments 的支持
FlatFileItemWriterBuilderAPI 的增强功能
1.1. @SpringBatchTest 注解
Spring Batch 提供了一些不错的 Util 类(例如JobLauncherTestUtils和JobRepositoryTestUtils)和测试执行监听器(StepScopeTestExecutionListener和JobScopeTestExecutionListener)来测试批处理组件。但是,为了使用这些 Util,必须显式配置它们。此版本引入了一个名为@SpringBatchTest的新 Comments,该 Comments 会自动将 Utilbean 和侦听器添加到测试上下文中,并使它们可用于自动装配,如以下示例所示:
@RunWith(SpringRunner.class)
@SpringBatchTest
@ContextConfiguration(classes = {JobConfiguration.class})
public class JobTest {
@Autowired
private JobLauncherTestUtils jobLauncherTestUtils;
@Autowired
private JobRepositoryTestUtils jobRepositoryTestUtils;
@Before
public void clearMetadata() {
jobRepositoryTestUtils.removeJobExecutions();
}
@Test
public void testJob() throws Exception {
// given
JobParameters jobParameters =
jobLauncherTestUtils.getUniqueJobParameters();
// when
JobExecution jobExecution =
jobLauncherTestUtils.launchJob(jobParameters);
// then
Assert.assertEquals(ExitStatus.COMPLETED,
jobExecution.getExitStatus());
}
}
有关此新 Comments 的更多详细信息,请参见Unit Testing章。
1.2. @EnableBatchIntegration 注解
设置远程分块作业需要定义许多 bean:
- 连接工厂,用于从消息传递中间件(JMS,AMQP 等)获取连接
MessagingTemplate,以将请求从主服务器发送到 Worker,然后再次返回- Spring Integration 从消息传递中间件获取消息的 Importing 通道和输出通道
- 主端的特殊 Item 编写器(
ChunkMessageChannelItemWriter)知道如何将数据块发送给工作人员进行处理和写入 - 工 Writer 方的消息侦听器(
ChunkProcessorChunkHandler)从主服务器接收数据
乍一 Watch 这可能有些令人生畏。此版本引入了名为@EnableBatchIntegration的新 Comments 以及新的 API(RemoteChunkingMasterStepBuilder和RemoteChunkingWorkerBuilder)以简化配置。以下示例显示了如何使用新的 Comments 和 API:
@Configuration
@EnableBatchProcessing
@EnableBatchIntegration
public class RemoteChunkingAppConfig {
@Autowired
private RemoteChunkingMasterStepBuilderFactory masterStepBuilderFactory;
@Autowired
private RemoteChunkingWorkerBuilder workerBuilder;
@Bean
public TaskletStep masterStep() {
return this.masterStepBuilderFactory
.get("masterStep")
.chunk(100)
.reader(itemReader())
.outputChannel(outgoingRequestsToWorkers())
.inputChannel(incomingRepliesFromWorkers())
.build();
}
@Bean
public IntegrationFlow worker() {
return this.workerBuilder
.itemProcessor(itemProcessor())
.itemWriter(itemWriter())
.inputChannel(incomingRequestsFromMaster())
.outputChannel(outgoingRepliesToMaster())
.build();
}
// Middleware beans setup omitted
}
这个新的 Comments 和构建器负责配置基础结构 Bean 的繁重工作。现在,您可以在工作端轻松配置一个主步骤以及一个 Spring Integration 流程。您可以在samples module中找到使用这些新 API 的远程分块示例,并在Spring 批处理集成一章中找到更多详细信息。
就像简化了远程组块配置一样,此版本还引入了新的 API 来简化远程分区设置:RemotePartitioningMasterStepBuilder和RemotePartitioningWorkerStepBuilder。如果存在@EnableBatchIntegration,则可以在配置类中自动连接它们,如以下示例所示:
@Configuration
@EnableBatchProcessing
@EnableBatchIntegration
public class RemotePartitioningAppConfig {
@Autowired
private RemotePartitioningMasterStepBuilderFactory masterStepBuilderFactory;
@Autowired
private RemotePartitioningWorkerStepBuilderFactory workerStepBuilderFactory;
@Bean
public Step masterStep() {
return this.masterStepBuilderFactory
.get("masterStep")
.partitioner("workerStep", partitioner())
.gridSize(10)
.outputChannel(outgoingRequestsToWorkers())
.inputChannel(incomingRepliesFromWorkers())
.build();
}
@Bean
public Step workerStep() {
return this.workerStepBuilderFactory
.get("workerStep")
.inputChannel(incomingRequestsFromMaster())
.outputChannel(outgoingRepliesToMaster())
.chunk(100)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build();
}
// Middleware beans setup omitted
}
您可以在Spring 批处理集成章中找到有关这些新 API 的更多详细信息。
1.3. JSON 支持
Spring Batch 4.1 添加了对 JSON 格式的支持。此版本引入了一个新的 Item 读取器,它可以读取以下格式的 JSON 资源:
[
{
"isin": "123",
"quantity": 1,
"price": 1.2,
"customer": "foo"
},
{
"isin": "456",
"quantity": 2,
"price": 1.4,
"customer": "bar"
}
]
与 XML 的StaxEventItemReader相似,新的JsonItemReader使用流 API 读取大块的 JSON 对象。 Spring Batch 支持两个库:
要添加其他库,您可以实现JsonObjectReader接口。
JsonFileItemWriter还支持写入 JSON 数据。有关 JSON 支持的更多详细信息,请参见ItemReaders 和 ItemWriters章。
1.4. Bean 验证 API 支持
此版本带来了一个名为BeanValidatingItemProcessor的新ValidatingItemProcessor实现,它使您可以验证使用 Bean Validation API(JSR-303)注解进行注解的 Item。例如,给定以下类型Person:
class Person {
@NotEmpty
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
您可以通过在应用程序上下文中声明BeanValidatingItemProcessor bean 来验证 Item,并在面向块的步骤中将其注册为处理器:
@Bean
public BeanValidatingItemProcessor<Person> beanValidatingItemProcessor() throws Exception {
BeanValidatingItemProcessor<Person> beanValidatingItemProcessor = new BeanValidatingItemProcessor<>();
beanValidatingItemProcessor.setFilter(true);
return beanValidatingItemProcessor;
}
1.5. JSR-305 支持
此版本增加了对 JSR-305 注解的支持。它利用 Spring Framework 的Null-safetyComments,并将它们添加到 Spring Batch 的所有公共 API 上。
这些注解不仅将在使用 Spring Batch API 时强制执行空安全性,而且还可以被 IDE 用于提供与空性有关的有用信息。例如,如果用户要实现ItemReader接口,则任何支持 JSR-305 注解的 IDE 都会生成以下内容:
public class MyItemReader implements ItemReader<String> {
@Nullable
public String read() throws Exception {
return null;
}
}
read方法中出现的@NullableComments 清楚表明此方法的约定表明它可能返回null。这将强制执行其 Javadoc 中所说的read方法在数据源耗尽时应返回null。
1.6. FlatFileItemWriterBuilder 增强功能
此版本中添加的另一个小功能是简化了写入平面文件的配置。特别是,这些更新简化了定界文件和定宽文件的配置。以下是更改前后的示例。
// Before
@Bean
public FlatFileItemWriter<Item> itemWriter(Resource resource) {
BeanWrapperFieldExtractor<Item> fieldExtractor =
new BeanWrapperFieldExtractor<Item>();
fieldExtractor.setNames(new String[] {"field1", "field2", "field3"});
fieldExtractor.afterPropertiesSet();
DelimitedLineAggregator aggregator = new DelimitedLineAggregator();
aggregator.setFieldExtractor(fieldExtractor);
aggregator.setDelimiter(";");
return new FlatFileItemWriterBuilder<Item>()
.name("itemWriter")
.resource(resource)
.lineAggregator(aggregator)
.build();
}
// After
@Bean
public FlatFileItemWriter<Item> itemWriter(Resource resource) {
return new FlatFileItemWriterBuilder<Item>()
.name("itemWriter")
.resource(resource)
.delimited()
.delimiter(";")
.names(new String[] {"field1", "field2", "field3"})
.build();
}
3. 批处理的域语言
对于任何经验丰富的批处理设计师来说,Spring Batch 中使用的批处理的总体概念应该是熟悉且舒适的。有“作业”和“步骤”,以及开发人员提供的称为 ItemReaders 和 ItemWriters 的处理单元。但是,由于存在 Spring 模式,操作,模板,回调和惯用语,因此有以下机会:
- 遵守明确的关注点方面的重大改进
- 清楚地描述了作为接口提供的体系结构层和服务
- 简单和默认的实现方式,可以快速采用和开箱即用
- 大大增强了可扩展性
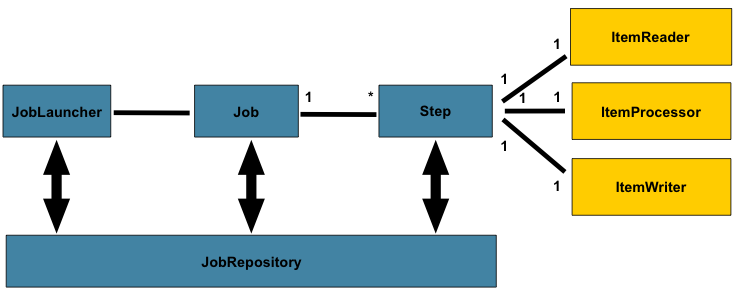
下图是已使用了数十年的批处理参考体系结构的简化版本。它概述了组成批处理领域语言的组件。该体系结构框架是一个蓝图,已经在最后几代平台(COBOL/Mainframe,C/Unix 和现在的 Java /任何地方)上数十年的实现中得到了证明。 JCL 和 COBOL 开发人员可能像 C,C#和 Java 开发人员一样熟悉这些概念。 Spring Batch 提供了层,组件和技术服务的物理实现,这些层,组件和技术服务通常用于强大,可维护的系统中,这些系统用于解决从简单到复杂的批处理应用程序的创建,其基础结构和扩展可以满足非常复杂的处理需求。
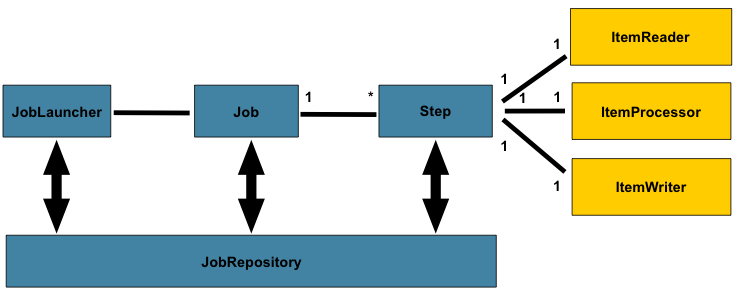
图 2.1:批量定型
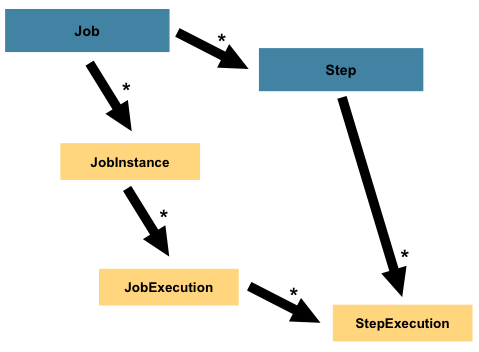
上图突出显示了组成批处理域语言的关键概念。作业有一个到多个步骤,其中只有一个 ItemReader,ItemProcessor 和 ItemWriter。需要启动一个作业(JobLauncher),并且需要存储有关当前正在运行的进程的元数据(JobRepository)。
3.1 Job
本节描述与批处理作业的概念有关的构造型。 Job是封装整个批处理过程的实体。与其他 SpringItem 一样,Job将通过 XML 配置文件或基于 Java 的配置连接在一起。该配置可以被称为“作业配置”。但是,Job只是整体层次结构的顶部:
在 Spring Batch 中,作业只是“步骤”的容器。它组合了逻辑上属于流程的多个步骤,并允许配置所有步骤全局的属性,例如可重新启动性。作业配置包含:
- 工作的简单名称
- 步骤的定义和 Sequences
- 作业是否可重新启动
Spring Batch 以SimpleJob类的形式提供了Job接口的默认简单实现,该类在Job之上创建了一些标准功能,但是 batch 名称空间消除了直接实例化它的需要。而是可以使用<job>标签:
<job id="footballJob">
<step id="playerload" next="gameLoad"/>
<step id="gameLoad" next="playerSummarization"/>
<step id="playerSummarization"/>
</job>
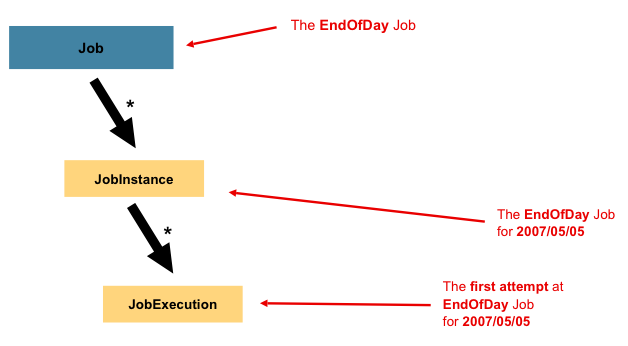
3.1.1 JobInstance
JobInstance表示逻辑作业运行的概念。让我们考虑一个应该在一天结束时运行一次的批处理作业,例如上图中的“ EndOfDay”作业。有一个’EndOfDay’Job,但是必须分别跟踪Job的每个运行。对于这项工作,每天将有一个逻辑JobInstance。例如,将有 1 月 1 日运行和 1 月 2 日运行。如果 1 月 1 日运行第一次失败并在第二天再次运行,则仍是 1 月 1 日运行。 (通常,这也与它正在处理的数据相对应,这意味着 1 月 1 日运行将处理 1 月 1 日的数据,依此类推)。因此,每个JobInstance可以有多个执行(下面将更详细地讨论JobExecution),并且在给定的时间只能运行一个与特定Job并标识JobParameter的JobInstance。
JobInstance的定义绝对与将要加载的数据无关。完全取决于用于确定如何加载数据的ItemReader实现。例如,在 EndOfDay 场景中,数据上可能有一列指示该数据所属的“生效日期”或“计划日期”。因此,1 月 1 日的运行只会加载来自 1 号的数据,而 1 月 2 日的运行只会使用来自 2 号的数据。由于此确定可能是业务决策,因此应由ItemReader来决定。但是,使用相同的JobInstance将确定是否使用先前执行中的“状态”(即下面讨论的ExecutionContext)。使用新的JobInstance表示“从头开始”,而使用现有实例通常表示“从上次中断的地方开始”。
3.1.2 JobParameters
在讨论了JobInstance及其与Job的区别之后,自然要问的问题是:“一个JobInstance与另一个JobInstance有什么区别?”答案是:JobParameters。 JobParameters是用于启动批处理作业的一组参数。在运行期间,它们可以用于标识甚至用作参考数据:
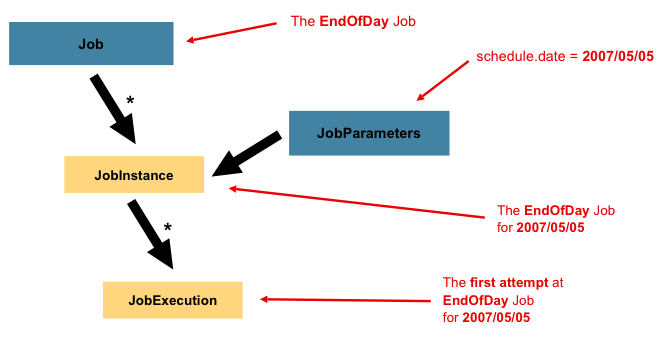
在上面的示例中,有两个实例,一个实例是 1 月 1 日,另一个实例是 1 月 2 日,实际上只有一个 Job,一个实例的工作参数为 01-01-2008,另一个实例的工作参数为。参数 01-02-2008.因此,Contract 可以定义为:JobInstance = Job标识JobParameters。这使开发人员可以有效地控制JobInstance的定义方式,因为他们可以控制传入的参数。
Note
并非所有作业参数都需要有助于JobInstance的标识。默认情况下,它们会这样做,但是该框架允许使用参数也不会对JobInstance的身份作出贡献的Job提交。
3.1.3 JobExecution
JobExecution是指一次尝试运行Job的技术概念。执行可能以失败或成功结束,但是与给定执行相对应的JobInstance不会被视为完成,除非执行成功完成。以上面描述的 EndOfDay Job为例,考虑到 01-01-2008 的JobInstance首次运行失败。如果使用与第一次运行相同的标识作业参数再次运行(01-01-2008),将创建一个新的JobExecution。但是,仍然只有一个JobInstance。
Job定义什么是作业及其执行方式,而JobInstance是纯粹的组织对象,用于将执行分组在一起,主要是为了实现正确的重启语义。 JobExecution是运行期间实际发生情况的主要存储机制,因此包含许多必须控制和持久化的属性:
表 3.1. JobExecution 属性
| status | BatchStatus对象,指示执行状态。运行时为 BatchStatus.STARTED,如果失败,则为 BatchStatus.FAILED,如果成功完成,则为 BatchStatus.COMPLETED。 |
|---|---|
| startTime | java.util.Date代表执行开始时的当前系统时间。 |
| endTime | java.util.Date代表执行完成时的当前系统时间,无论执行是否成功。 |
| exitStatus | ExitStatus表示运行结果。这是最重要的,因为它包含将返回给调用方的退出代码。有关更多详细信息,请参见第 5 章。 |
| createTime | java.util.Date代表首次保留JobExecution时的当前系统时间。作业可能尚未启动(因此没有启动时间),但是它将始终具有 createTime,这是 Management 作业级别ExecutionContext的框架所要求的。 |
| lastUpdated | java.util.Date代表上一次保留JobExecution的时间。 |
| executionContext | “属性袋”包含两次执行之间需要保留的所有用户数据。 |
| failureExceptions | 在执行Job时遇到的异常列表。如果在Job失败期间遇到多个异常,这些将很有用。 |
这些属性很重要,因为它们将被保留并可以用来完全确定执行状态。例如,如果 01-01 的 EndOfDay 作业在晚上 9:00 执行,但在 9:30 失败,则将在批处理元数据表中进行以下 Importing:
表 3.2. BATCH_JOB_INSTANCE
| JOB_INST_ID | JOB_NAME |
|---|---|
| 1 | EndOfDayJob |
表 3.3. BATCH_JOB_EXECUTION_PARAMS
| JOB_EXECUTION_ID | TYPE_CD | KEY_NAME | DATE_VAL | IDENTIFYING |
|---|---|---|---|---|
| 1 | DATE | schedule.Date | 2008-01-01 | TRUE |
表 3.4. BATCH_JOB_EXECUTION
| JOB_EXEC_ID | JOB_INST_ID | START_TIME | END_TIME | STATUS |
|---|---|---|---|---|
| 1 | 1 | 2008-01-01 21:00 | 2008-01-01 21:30 | FAILED |
Note
为了清楚和格式化,列名可能已缩写或删除
现在,该工作已失败,我们假设确定问题已花费了一整夜,因此现在已关闭“批处理窗口”。假设窗口在 9:00 PM 开始,则该作业将在 01-01 再次开始,从停止的地方开始,并在 9:30 成功完成。因为现在是第二天,所以还必须运行 01-02 作业,此作业随后在 9:31 开始,并在正常的一小时时间内在 10:30 完成。无需先将一个JobInstance依次启动,除非这两个作业有可能尝试访问相同的数据,从而导致锁定数据库级别的问题。何时应运行Job完全取决于调度程序。由于它们是单独的JobInstance,因此 Spring Batch 将不会尝试阻止它们同时运行。 (尝试在另一个已经运行的同一个JobInstance上运行将导致抛出JobExecutionAlreadyRunningException)。 JobInstance和JobParameters表中现在都应该有一个额外的条目,而JobExecution表中应该有两个额外的条目:
表 3.5. BATCH_JOB_INSTANCE
| JOB_INST_ID | JOB_NAME |
|---|---|
| 1 | EndOfDayJob |
| 2 | EndOfDayJob |
表 3.6. BATCH_JOB_EXECUTION_PARAMS
| JOB_EXECUTION_ID | TYPE_CD | KEY_NAME | DATE_VAL | IDENTIFYING |
|---|---|---|---|---|
| 1 | DATE | schedule.Date | 2008-01-01 00:00:00 | TRUE |
| 2 | DATE | schedule.Date | 2008-01-01 00:00:00 | TRUE |
| 3 | DATE | schedule.Date | 2008-01-02 00:00:00 | TRUE |
表 3.7. BATCH_JOB_EXECUTION
| JOB_EXEC_ID | JOB_INST_ID | START_TIME | END_TIME | STATUS |
|---|---|---|---|---|
| 1 | 1 | 2008-01-01 21:00 | 2008-01-01 21:30 | FAILED |
| 2 | 1 | 2008-01-02 21:00 | 2008-01-02 21:30 | COMPLETED |
| 3 | 2 | 2008-01-02 21:31 | 2008-01-02 22:29 | COMPLETED |
Note
为了清楚和格式化,列名可能已缩写或删除
3.2 Step
Step是一个域对象,它封装了批处理作业的一个独立的 Sequences 阶段。因此,每个Job完全由一个或多个步骤组成。 Step包含定义和控制实际批处理所需的所有信息。这是一个模糊的描述,因为任何给定Step的内容都由开发人员自行编写Job来决定。步骤可以像开发人员所希望的那样简单或复杂。一个简单的Step可能会将文件中的数据加载到数据库中,几乎不需要代码。 (取决于所使用的实现方式)较复杂的Step可能具有复杂的业务规则,这些规则将在处理过程中应用。与Job一样,Step的个人StepExecution与唯一的JobExecution相对应:
3.2.1 StepExecution
StepExecution代表执行Step的单次尝试。每次运行Step都会创建一个新的StepExecution,类似于JobExecution。但是,如果某个步骤由于执行失败而无法执行,则该执行将不会 continue 执行。 StepExecution仅在其Step实际启动时创建。
步骤执行由StepExecution类的对象表示。每个执行都包含对其相应步骤和JobExecution的引用,以及与事务相关的数据,例如提交和回滚计数以及开始和结束时间。此外,每个步骤执行都将包含ExecutionContext,其中包含开发人员在批处理运行期间需要保留的任何数据,例如重新启动所需的统计信息或状态信息。以下是StepExecution的属性列表:
表 3.8. StepExecution 属性
| status | BatchStatus对象,指示执行状态。运行时,状态为 BatchStatus.STARTED,如果失败,则状态为 BatchStatus.FAILED,如果成功完成,则状态为 BatchStatus.COMPLETED |
|---|---|
| startTime | java.util.Date代表执行开始时的当前系统时间。 |
| endTime | java.util.Date代表执行完成时的当前系统时间,无论执行是否成功。 |
| exitStatus | ExitStatus表示执行结果。这是最重要的,因为它包含将返回给调用方的退出代码。有关更多详细信息,请参见第 5 章。 |
| executionContext | “属性袋”包含两次执行之间需要保留的所有用户数据。 |
| readCount | 已成功读取的 Item 数 |
| writeCount | 已成功写入的 Item 数 |
| commitCount | 为此执行已提交的事务数 |
| rollbackCount | Step控制的业务事务已回滚的次数。 |
| readSkipCount | read失败的次数,导致 Item 被跳过。 |
| processSkipCount | process失败的次数,导致 Item 被跳过。 |
| filterCount | ItemProcessor已“过滤”的 Item 数。 |
| writeSkipCount | write失败的次数,导致 Item 被跳过。 |
3.3 ExecutionContext
ExecutionContext表示键/值对的集合,这些键/值对由框架保留并控制,以便允许开发人员放置一个存储范围为StepExecution或JobExecution的持久状态。对于熟悉 Quartz 的人来说,它与JobDataMap非常相似。最佳用法示例是促进重新启动。以平面文件 Importing 为例,在处理各个行时,框架会定期在提交点保留ExecutionContext。如果运行期间发生致命错误,或者即使断电,这也允许ItemReader存储其状态。需要做的就是将当前读取的行数放入上下文中,框架将完成其余工作:
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());
以 Job Stereotypes 部分的 EndOfDay 示例为例,假设有一个步骤:“ loadData”,它将文件加载到数据库中。第一次失败运行后,元数据表将如下所示:
表 3.9. BATCH_JOB_INSTANCE
| JOB_INST_ID | JOB_NAME |
|---|---|
| 1 | EndOfDayJob |
表 3.10. BATCH_JOB_PARAMS
| JOB_INST_ID | TYPE_CD | KEY_NAME | DATE_VAL |
|---|---|---|---|
| 1 | DATE | schedule.Date | 2008-01-01 |
表 3.11. BATCH_JOB_EXECUTION
| JOB_EXEC_ID | JOB_INST_ID | START_TIME | END_TIME | STATUS |
|---|---|---|---|---|
| 1 | 1 | 2008-01-01 21:00 | 2008-01-01 21:30 | FAILED |
表 3.12. BATCH_STEP_EXECUTION
| STEP_EXEC_ID | JOB_EXEC_ID | STEP_NAME | START_TIME | END_TIME | STATUS |
|---|---|---|---|---|---|
| 1 | 1 | loadDate | 2008-01-01 21:00 | 2008-01-01 21:30 | FAILED |
表 3.13. BATCH_STEP_EXECUTION_CONTEXT
| STEP_EXEC_ID | SHORT_CONTEXT |
|---|---|
| 1 | {piece.count=40321} |
在这种情况下,Step运行了 30 分钟并处理了 40321 个“件”,在这种情况下,这代表了文件中的行。此值将在框架每次提交之前更新,并且可以包含与ExecutionContext内的条目相对应的多行。在提交之前被通知需要各种StepListener或ItemStream之一,本指南后面将对此进行详细讨论。与前面的示例一样,假定Job在第二天重新启动。重新启动后,将从数据库中重新构建上次运行的ExecutionContext的值,打开ItemReader时,它可以检查其在上下文中是否具有任何存储状态,并从那里初始化自身:
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
}
在这种情况下,执行上述代码后,当前行将为 40,322,从而允许Step从中断处重新开始。 ExecutionContext还可以用于需要保留有关运行本身的统计信息。例如,如果平面文件包含跨多行存在的处理订单,则可能有必要存储已处理的订单数量(与读取的行数有很大不同),以便可以通过以下方式发送电子邮件: Step的末尾在正文中处理了总订单。框架负责为开发人员存储此内容,以便使用单独的JobInstance正确确定范围。知道是否应使用现有的ExecutionContext可能非常困难。例如,使用上面的“ EndOfDay”示例,当 01-01 运行第二次再次开始时,框架将识别出它是相同的JobInstance,并且在单个Step的基础上,将ExecutionContext从数据库中移出并动手它是StepExecution到Step本身的一部分。相反,对于 01-02 运行,框架会认识到它是一个不同的实例,因此必须将空上下文传递给Step。框架使开发人员做出许多这类确定,以确保在正确的时间将状态提供给开发人员。同样重要的是要注意,在任何给定时间,每个StepExecution仅存在一个ExecutionContext。 ExecutionContext的 Client 应小心,因为这会创建共享的键空间,因此在放入值时应格外小心,以确保不会覆盖任何数据。但是,Step绝对不会在上下文中存储任何数据,因此没有办法对框架产生不利影响。
同样重要的是要注意,每个JobExecution至少有一个ExecutionContext,每个StepExecution至少有一个ExecutionContext。例如,考虑以下代码片段:
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob
如 Comment 中所述,ecStep 将不等于 ecJob;他们是两个不同的ExecutionContext。范围为Step的一个将保存在Step的每个提交点,而范围为Job的一个将保存在每次Step执行之间。
3.4 JobRepository
JobRepository是上述所有构造型的持久性机制。它为JobLauncher,Job和Step实现提供 CRUD 操作。首次启动Job时,会从存储库中获取JobExecution,并且在执行过程中StepExecution和JobExecution的实现通过将其传递到存储库中而得以保留:
<job-repository id="jobRepository"/>
3.5 JobLauncher
JobLauncher代表一个简单的界面,用于使用给定的JobParameters集启动Job:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException;
}
预期实现将从JobRepository获得有效的JobExecution并执行Job。
3.6itemReader
ItemReader是一种抽象,表示一次检索Step的 Importing。当ItemReader用尽了它可以提供的 Item 时,它将通过返回 null 来表明这一点。可以在第 6 章,ItemReader 和 ItemWriters中找到有关ItemReader接口及其各种实现的更多详细信息。
3.7ItemWriter
ItemWriter是一个抽象,表示一次Step,一个批次或大块 Item 的输出。通常,ItemWriter 不知道下一步将要接收的 Importing,仅知道在当前调用中传递的 Item。有关ItemWriter接口及其各种实现的更多详细信息,可以在第 6 章,ItemReader 和 ItemWriters中找到。
3.8Item 处理器
ItemProcessor是表示 Item 的业务处理的抽象。 ItemReader读取一项,ItemWriter写入一项,而ItemProcessor提供访问权以进行转换或应用其他业务处理。如果在处理 Item 时确定该 Item 无效,则返回 null 表示不应将该 Item 写出。有关 ItemProcessor 接口的更多详细信息,请参见第 6 章,ItemReader 和 ItemWriters。
3.9 批处理命名空间
上面列出的许多域概念都需要在 Spring ApplicationContext中进行配置。尽管可以在标准 bean 定义中使用上述接口的实现,但提供了命名空间以简化配置:
<beans:beans xmlns="http://www.springframework.org/schema/batch"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd">
<job id="ioSampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
</tasklet>
</step>
</job>
</beans:beans>
只要声明了批处理名称空间,就可以使用其任何元素。有关配置Job的更多信息,请参见第 4 章,配置和运行作业。可以在第 5 章,配置步骤中找到有关配置步骤的更多信息。
4. 配置和运行作业
在domain section中,使用下图作为指南讨论了总体体系结构设计:
尽管Job对象似乎是简单的步骤容器,但是开发人员必须了解许多配置选项。此外,对于Job将如何运行以及在此运行期间如何存储其元数据有许多考虑因素。本章将解释Job的各种配置选项和运行时问题。
4.1 配置作业
Job接口有多种实现,但是,名称空间抽象了配置上的差异。它仅具有三个必需的依赖项:名称JobRepository和Step的列表。
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>
这里的示例使用父 bean 定义来创建步骤。有关内联声明特定步骤详细信息的更多选项,请参见step configuration部分。 XML 名称空间默认引用 ID 为’jobRepository’的存储库,这是明智的默认设置。但是,可以显式覆盖:
<job id="footballJob" job-repository="specialRepository">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s3" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>
除了步骤之外,作业配置还可以包含其他有助于并行化(<split/>),声明性流控制(<decision/>)和流定义外部化(<flow/>)的元素。
4.1.1 Restartability
执行批处理作业时的一个关键问题与Job重新启动时的行为有关。如果特定JobInstance已经存在JobExecution,则启动Job被认为是“重新启动”。理想情况下,所有作业都应该能够从中断的地方开始,但是在某些情况下这是不可能的。 在这种情况下,完全由开发人员决定是否创建新的JobInstance 。但是,Spring Batch 确实提供了一些帮助。如果Job绝不应该重新启动,而应始终作为新JobInstance的一部分运行,则可重新启动属性可以设置为’false’:
<job id="footballJob" restartable="false">
...
</job>
换句话说,将 restartable 设置为 false 意味着“此作业不支持再次启动”。重新启动无法重新启动的作业将导致抛出JobRestartException:
Job job = new SimpleJob();
job.setRestartable(false);
JobParameters jobParameters = new JobParameters();
JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters);
jobRepository.saveOrUpdate(firstExecution);
try {
jobRepository.createJobExecution(job, jobParameters);
fail();
}
catch (JobRestartException e) {
// expected
}
这个 JUnit 代码片段显示了第一次为不可重新启动的job创建JobExecution不会造成任何问题。但是,第二次尝试将抛出JobRestartException。
4.1.2 拦截作业执行
在执行Job的过程中,通知其生命周期中的各种事件可能很有用,以便可以执行自定义代码。 SimpleJob通过在适当的时间调用JobListener来实现此目的:
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}
可以通过作业上的 listeners 元素将JobListener s 添加到SimpleJob:
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
<listeners>
<listener ref="sampleListener"/>
</listeners>
</job>
应该注意的是,无论Job是成功还是失败,都将调用afterJob。如果需要确定成功或失败,可以从JobExecution获得:
public void afterJob(JobExecution jobExecution){
if( jobExecution.getStatus() == BatchStatus.COMPLETED ){
//job success
}
else if(jobExecution.getStatus() == BatchStatus.FAILED){
//job failure
}
}
与此接口对应的 Comments 为:
@BeforeJob@AfterJob
4.1.3 从父作业继承
如果一组Job共享相似但不相同的配置,则定义“父” Job可能会有所帮助,具体的Job可以从中继承属性。类似于 Java 中的类继承,“子” Job将其元素和属性与父类结合在一起。
在下面的示例中,“ baseJob”是一个抽象的Job定义,仅定义一个侦听器列表。 Job“ job1”是一个具体的定义,它继承了“ baseJob”的侦听器列表,并将其与自己的侦听器列表合并,以产生带有两个侦听器和一个Step的Job,即“ step1”。
<job id="baseJob" abstract="true">
<listeners>
<listener ref="listenerOne"/>
<listeners>
</job>
<job id="job1" parent="baseJob">
<step id="step1" parent="standaloneStep"/>
<listeners merge="true">
<listener ref="listenerTwo"/>
<listeners>
</job>
有关更多详细信息,请参见从父步骤继承部分。
4.1.4 JobParametersValidator
在 XML 名称空间中声明的作业或使用 AbstractJob 的任何子类声明的作业可以选择在运行时声明作业参数的验证器。例如,当您需要 assert 一个作业使用其所有必填参数启动时,此功能很有用。有一个 DefaultJobParametersValidator 可用于约束简单的强制性和可选参数的组合,对于更复杂的约束,您可以自己实现接口。 XML 名称空间通过作业的子元素来支持验证器的配置,例如:
<job id="job1" parent="baseJob3">
<step id="step1" parent="standaloneStep"/>
<validator ref="paremetersValidator"/>
</job>
可以将验证器指定为引用(如上)或在 bean 名称空间中作为嵌套 bean 定义。
4.2 Java 配置
Spring 3 带来了通过 Java 而不是 XML 配置应用程序的功能。从 Spring Batch 2.2.0 开始,可以使用相同的 Java 配置来配置批处理作业。基于 Java 的配置有两个组件:@EnableBatchConfigurationComments 和两个构建器。
@EnableBatchProcessing的工作方式与 Spring 家族中其他@Enable*的 Comments 类似。在这种情况下,@EnableBatchProcessing提供了用于构建批处理作业的基本配置。在此基本配置中,除了提供许多可自动装配的 bean 之外,还创建了StepScope的实例:
JobRepository-Bean 名称“ jobRepository”JobLauncher-Bean 名称“ jobLauncher”JobRegistry-Bean 名称“ jobRegistry”PlatformTransactionManager-Bean 名称“ transactionManager”JobBuilderFactory-Bean 名称为“ jobBuilders”StepBuilderFactory-Bean 名称为“ stepBuilders”
此配置的核心接口是BatchConfigurer。默认实现提供上面提到的 bean,并且在要提供的上下文中需要DataSource作为 bean。 JobRepository将使用此数据源。
Note
只有一个配置类需要具有@EnableBatchProcessingComments。在为类加上 Comments 后,您将可以使用上述所有内容。
使用基本配置后,用户可以使用提供的构建器工厂来配置作业。以下是通过JobBuilderFactory和StepBuilderFactory配置的两步作业的示例。
@Configuration
@EnableBatchProcessing
@Import(DataSourceConfiguration.class)
public class AppConfig {
@Autowired
private JobBuilderFactory jobs;
@Autowired
private StepBuilderFactory steps;
@Bean
public Job job(@Qualifier("step1") Step step1, @Qualifier("step2") Step step2) {
return jobs.get("myJob").start(step1).next(step2).build();
}
@Bean
protected Step step1(ItemReader<Person> reader, ItemProcessor<Person, Person> processor, ItemWriter<Person> writer) {
return steps.get("step1")
.<Person, Person> chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
protected Step step2(Tasklet tasklet) {
return steps.get("step2")
.tasklet(tasklet)
.build();
}
}
4.3 配置 JobRepository
如前所述,JobRepository用于 Spring Batch 中各种持久化域对象(例如JobExecution和StepExecution)的基本 CRUD 操作。许多主要框架功能都需要它,例如JobLauncher,Job和Step。批处理名称空间抽象了JobRepository实现及其协 Writer 的许多实现细节。但是,仍然有一些可用的配置选项:
<job-repository id="jobRepository"
data-source="dataSource"
transaction-manager="transactionManager"
isolation-level-for-create="SERIALIZABLE"
table-prefix="BATCH_"
max-varchar-length="1000"/>
除了 ID 以外,上面列出的所有配置选项都不是必需的。如果未设置,将使用上面显示的默认值。出于认知目的,它们在上面显示。 max-varchar-length默认为 2500,这是samples 模式脚本中长VARCHAR列的长度
用于存储退出代码说明之类的内容。如果您不修改架构并且不使用多字节字符,则无需更改它。
4.3.1 JobRepository 的事务配置
如果使用名称空间,则将在存储库周围自动创建事务建议。这是为了确保正确保留批处理元数据(包括故障后重新启动所需的状态)。如果存储库方法不是事务性的,则框架的行为无法很好地定义。分别指定create*方法属性中的隔离级别,以确保启动作业时,如果两个进程试图同时启动同一作业,则只有一个成功。该方法的默认隔离级别为 SERIALIZABLE,这非常激进:READ_COMMITTED 也可以工作;如果两个进程不太可能以这种方式冲突,则 READ_UNCOMMITTED 会很好。但是,由于对create*方法的调用非常短,因此只要数据库平台支持,SERIALIZED 不太可能引起问题。但是,可以重写:
<job-repository id="jobRepository"
isolation-level-for-create="REPEATABLE_READ" />
如果不使用名称空间或工厂 Bean,那么使用 AOP 配置存储库的事务行为也很重要:
<aop:config>
<aop:advisor
pointcut="execution(* org.springframework.batch.core..*Repository+.*(..))"/>
<advice-ref="txAdvice" />
</aop:config>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" />
</tx:attributes>
</tx:advice>
该片段可以原样使用,几乎没有变化。还记得还要包括适当的名称空间声明,并确保 spring-tx 和 spring-aop(或整个 spring)在 Classpath 中。
4.3.2 更改表前缀
JobRepository的另一个可修改属性是元数据表的表前缀。默认情况下,它们都以 BATCH 开头。 BATCH_JOB_EXECUTION 和 BATCH_STEP_EXECUTION 是两个示例。但是,存在修改此前缀的潜在原因。如果模式名称需要在表名称之前,或者在同一模式内需要一组以上的元数据表,那么表前缀将需要更改:
<job-repository id="jobRepository"
table-prefix="SYSTEM.TEST_" />
鉴于上述更改,对元数据表的每个查询都将以“ SYSTEM.TEST_”为前缀。 BATCH_JOB_EXECUTION 将被称为 SYSTEM.TEST_JOB_EXECUTION。
Note
仅表前缀是可配置的。表名和列名不是。
4.3.3 内存中的存储库
在某些情况下,您可能不想将域对象持久保存到数据库中。原因之一可能是速度。在每个提交点存储域对象会花费额外的时间。另一个原因可能是您不需要为特定工作保留状态。因此,Spring 批处理提供了作业存储库的内存 Map 版本:
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager"/>
</bean>
请注意,内存中的存储库是易失性的,因此不允许在 JVM 实例之间重新启动。它还不能保证同时启动两个具有相同参数的作业实例,并且不适合在多线程 Job 或本地分区的 Step 中使用。因此,在需要这些功能的地方,请使用存储库的数据库版本。
但是,确实需要定义事务 Management 器,因为存储库中存在回滚语义,并且因为业务逻辑可能仍是事务性的(例如 RDBMS 访问)。出于测试目的,许多人认为ResourcelessTransactionManager有用。
4.3.4 存储库中的非标准数据库类型
如果使用的数据库平台不在受支持的平台列表中,并且 SQL 变量足够接近,则可以使用一种受支持的类型。为此,您可以使用原始的JobRepositoryFactoryBean代替名称空间快捷方式,并使用它来将数据库类型设置为最接近的匹配项:
<bean id="jobRepository" class="org...JobRepositoryFactoryBean">
<property name="databaseType" value="db2"/>
<property name="dataSource" ref="dataSource"/>
</bean>
(如果未指定,JobRepositoryFactoryBean会尝试从DataSource自动检测数据库类型.)平台之间的主要差异主要是由增加主键的策略引起的,因此通常也有必要覆盖incrementerFactory (使用 Spring 框架的标准实现之一)。
如果甚至不起作用,或者您没有使用 RDBMS,那么唯一的选择可能是实现SimpleJobRepository所依赖的各种Dao接口,并以正常的 Spring 方式手动将它们连接起来。
4.4 配置 JobLauncher
JobLauncher接口的最基本实现是SimpleJobLauncher。为了获得执行,它唯一需要的依赖项是JobRepository:
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
一旦获得JobExecution,它将被传递给Job的 execute 方法,最终将JobExecution返回给调用者:
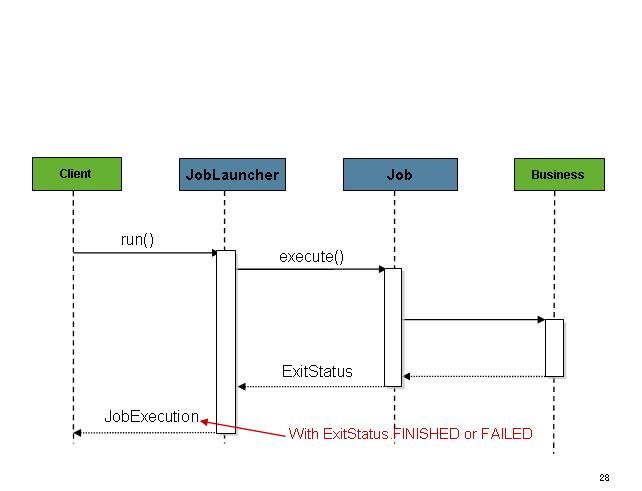
该序列很简单,从调度程序启动时效果很好。但是,尝试从 HTTP 请求启动时会出现问题。在这种情况下,启动需要异步完成,以便SimpleJobLauncher立即返回到其调用方。这是因为在长时间运行的进程(例如批处理)所需的时间内保持 HTTP 请求处于打开状态是一种不好的做法。下面是一个示例序列:
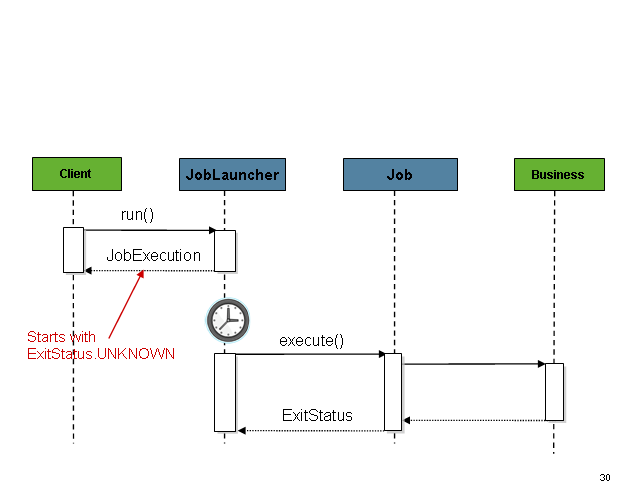
可以通过配置TaskExecutor轻松地将SimpleJobLauncher配置为允许这种情况:
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
</property>
</bean>
spring TaskExecutor接口的任何实现都可以用来控制作业的异步执行方式。
4.5 运行作业
至少,启动批处理作业需要两件事:要启动的Job和JobLauncher。两者都可以包含在相同的上下文或不同的上下文中。例如,如果从命令行启动作业,则将为每个作业实例化一个新的 JVM,因此每个作业将具有自己的JobLauncher。但是,如果从HttpRequest范围内的 Web 容器中运行,通常将配置一个JobLauncher用于异步作业启动,多个请求将被调用以启动其作业。
4.5.1 从命令行运行作业
对于想要从企业计划程序运行其作业的用户,命令行是主要界面。这是因为大多数调度程序(除了 Quartz,除非使用NativeJob,否则都是 Quartz 除外)直接与 os 进程一起工作,这些进程主要是从 Shell 脚本开始的。除了 Shell 脚本(例如 Perl,Ruby),甚至还有“构建工具”(例如 ant 或 maven)之外,还有许多启动 Java 进程的方法。但是,由于大多数人都熟悉 Shell 脚本,因此本示例将重点介绍它们。
The CommandLineJobRunner
因为启动作业的脚本必须启动 Java 虚拟机,所以需要一个具有 main 方法的类作为主要入口点。 Spring Batch 提供了一个实现此目的的实现:CommandLineJobRunner。需要特别注意的是,这只是引导应用程序的一种方法,但是有许多方法可以启动 Java 进程,并且绝对不应将此类视为 Authority。 CommandLineJobRunner执行四个任务:
- 加载适当的
ApplicationContext - 将命令行参数解析为
JobParameters - 根据参数找到合适的工作
- 使用应用程序上下文中提供的
JobLauncher启动作业。
所有这些任务仅使用传入的参数即可完成。以下是必填参数:
表 4.1. CommandLineJobRunner 参数
| jobPath | 将用于创建ApplicationContext的 XML 文件的位置。该文件应包含运行完整的Job所需的所有内容 |
|---|---|
| jobName | 要运行的作业的名称。 |
这些参数必须首先以路径和第二个名称传递。这些参数之后的所有参数均视为 JobParameters,并且必须采用“名称=值”的格式:
bash$ java CommandLineJobRunner endOfDayJob.xml endOfDay schedule.date(date)=2007/05/05
在大多数情况下,您可能想使用 Lists 在 jar 中声明您的主类,但为简单起见,直接使用了该类。此示例使用的是domain section中的“ EndOfDay”示例。第一个参数是’endOfDayJob.xml’,它是包含Job的 Spring ApplicationContext。第二个参数’endOfDay’表示作业名称。最后一个参数’schedule.date(date)= 2007/05/05’将转换为JobParameters。 XML 配置示例如下:
<job id="endOfDay">
<step id="step1" parent="simpleStep" />
</job>
<!-- Launcher details removed for clarity -->
<beans:bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher" />
此示例过于简单,因为通常在 Spring Batch 中运行批处理作业还有更多要求,但是它用于显示CommandLineJobRunner的两个主要要求:Job和JobLauncher
ExitCodes
从命令行启动批处理作业时,通常使用企业计划程序。大多数调度程序都非常笨,只能在流程级别上工作。这意味着他们只知道他们正在调用的某些 os 进程,例如 shell 脚本。在这种情况下,将作业成功或失败传达回调度程序的唯一方法是通过返回码。返回码是由进程返回到调度程序的数字,指示运行结果。在最简单的情况下:0 是成功,1 是失败。但是,可能存在更复杂的方案:如果作业 A 返回 4 个启动作业 B,并且如果作业 5 返回 5 个启动作业 C。这种类型的行为是在调度程序级别配置的,但是诸如 Spring Batch 提供了一种返回特定批处理作业的“退出代码”的数字表示的方法。在 Spring Batch 中,它封装在ExitStatus内,在第 5 章中将进行更详细的介绍。出于讨论退出代码的目的,唯一重要的要知道的是ExitStatus具有由框架设置的退出代码属性(或开发人员),并作为JobLauncher返回的JobExecution的一部分返回。 CommandLineJobRunner使用ExitCodeMapper接口将此字符串值转换为数字:
public interface ExitCodeMapper {
public int intValue(String exitCode);
}
ExitCodeMapper的基本约定是,给定字符串退出代码,将返回数字表示形式。作业运行程序使用的默认实现是 SimpleJvmExitCodeMapper,它对于完成返回 0,对于一般错误返回 1,对于任何作业运行程序错误(例如,无法在提供的上下文中找到Job)返回 2.如果需要比上述 3 个值更复杂的东西,则必须提供ExitCodeMapper接口的自定义实现。由于CommandLineJobRunner是创建ApplicationContext的类,因此无法“连接在一起”,因此必须自动连接任何需要覆盖的值。这意味着,如果在 BeanFactory 中找到ExitCodeMapper的实现,它将在创建上下文后注入到运行器中。提供您自己的ExitCodeMapper所需要做的就是将实现声明为根级 Bean,并确保它是运行程序加载的ApplicationContext的一部分。
4.5.2 从 Web 容器中运行作业
从历史上 Watch,如上所述,已从命令行启动了诸如批处理作业之类的脱机处理。但是,在许多情况下,从HttpRequest启动是更好的选择。许多此类用例包括报告,临时作业运行和 Web 应用程序支持。因为按定义,批处理作业是长期运行的,所以最重要的问题是确保异步启动该作业:
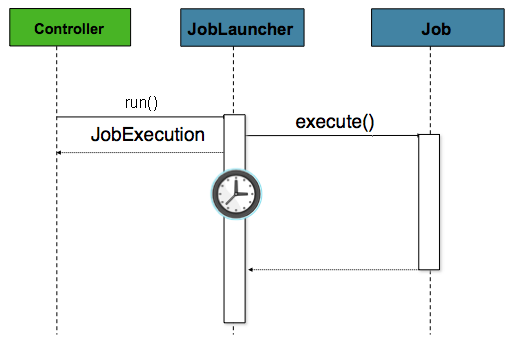
在这种情况下,该控制器是 Spring MVC 控制器。有关 Spring MVC 的更多信息,请参见http://docs.spring.io/spring/docs/3.2.x/spring-framework-reference/html/mvc.html。控制器使用已配置为启动asynchronously的JobLauncher来启动Job,它会立即返回JobExecution。 Job可能仍在运行,但是,这种非阻塞行为允许控制器立即返回,这在处理HttpRequest时是必需的。下面是一个示例:
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}
4.6 高级元数据使用
到目前为止,已经讨论了 JobLauncher 和 JobRepository 接口。它们一起代表了作业的简单启动和批处理域对象的基本 CRUD 操作:
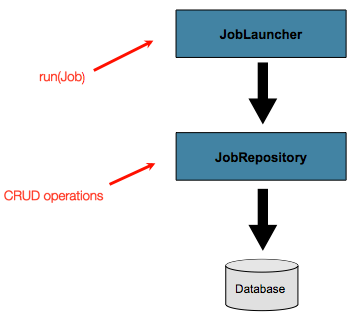
JobLauncher使用JobRepository创建新的JobExecution对象并运行它们。 Job和Step实现稍后在运行Job的过程中使用相同的JobRepository进行相同执行的基本更新。基本操作足以满足简单的场景,但是在具有成百上千个批处理作业和复杂的调度要求的大型批处理环境中,需要对元数据进行更高级的访问:
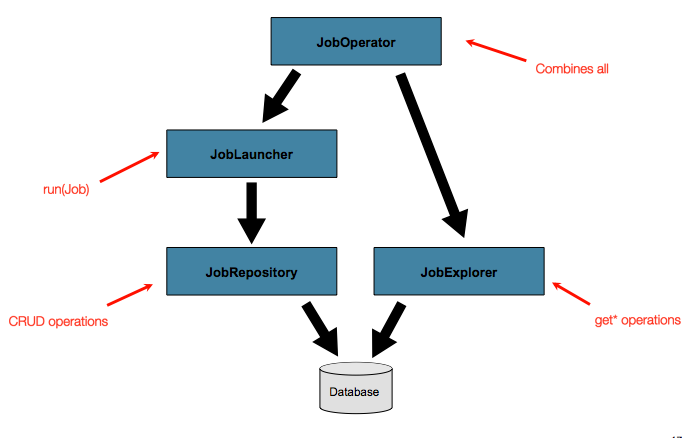
JobExplorer和JobOperator接口(将在下面进行讨论)添加了用于查询和控制元数据的其他功能。
4.6.1 查询存储库
在使用任何高级功能之前,最基本的需求是能够查询存储库中现有的执行情况。 JobExplorer界面提供了此功能:
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
}
从上面的方法签名可以明显 Watch 出,JobExplorer是JobRepository的只读版本,并且像JobRepository一样,可以通过工厂 bean 轻松配置:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" />
本章前面,其中提到可以修改JobRepository的表前缀以允许使用不同的版本或架构。由于JobExplorer使用相同的表,因此它也需要设置前缀的能力:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" p:tablePrefix="BATCH_" />
4.6.2 JobRegistry
JobRegistry(及其父接口 JobLocator)不是强制性的,但如果您要跟踪上下文中可用的作业,则可以使用它。当作业在其他位置(例如在子上下文中)创建时,对于在应用程序上下文中集中收集作业也很有用。自定义 JobRegistry 实现也可以用于操纵已注册作业的名称和其他属性。框架仅提供一种实现,该实现基于从作业名称到作业实例的简单 Map。它的配置就像这样:
<bean id="jobRegistry" class="org.spr...MapJobRegistry" />
有两种自动填充 JobRegistry 的方法:使用 bean 后处理器和使用注册商生命周期组件。以下各节将介绍这两种机制。
JobRegistryBeanPostProcessor
这是一个 bean 后处理器,可以在创建所有作业时注册它们:
<bean id="jobRegistryBeanPostProcessor" class="org.spr...JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean>
尽管并非严格要求示例中的后处理器具有 ID,以便可以将其包含在子上下文中(例如作为父 Bean 定义),并使在此创建的所有作业也自动进行注册。
AutomaticJobRegistrar
这是一个生命周期组件,它创建子上下文并在创建这些上下文时注册这些上下文中的作业。这样做的优点之一是,尽管子上下文中的作业名称在注册表中仍必须是全局唯一的,但它们的依存关系可以具有“自然”名称。因此,例如,您可以创建一组 XML 配置文件,每个 XML 配置文件仅具有一个Job,但都具有相同 Bean 名称的ItemReader的不同定义,例如“Reader”。如果将所有这些文件都导入到同一上下文中,那么 Reader 定义将相互冲突并相互替代,但是使用自动注册器可以避免这种情况。这使集成由应用程序的单独模块贡献的作业变得更加容易。
<bean class="org.spr...AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.spr...ClasspathXmlApplicationContextsFactoryBean">
<property name="resources" value="classpath*:/config/job*.xml" />
</bean>
</property>
<property name="jobLoader">
<bean class="org.spr...DefaultJobLoader">
<property name="jobRegistry" ref="jobRegistry" />
</bean>
</property>
</bean>
注册服务商具有两个必填属性,一个是ApplicationContextFactory的数组(此处是从方便的工厂 bean 创建的),另一个是JobLoader。 JobLoader负责 Management 子上下文的生命周期并在JobRegistry中注册作业。
ApplicationContextFactory负责创建子上下文,最常见的用法是如上使用ClassPathXmlApplicationContextFactory。该工厂的功能之一是默认情况下将某些配置从父上下文复制到子级。因此,例如,如果子代中的PropertyPlaceholderConfigurer或 AOP 配置应与父代相同,则不必重新定义它。
如果需要,可以将AutomaticJobRegistrar与JobRegistryBeanPostProcessor结合使用(只要也使用DefaultJobLoader)。例如,如果在主要父级上下文以及子级位置中定义了作业,则可能需要这样做。
4.6.3 JobOperator
如前所述,JobRepository提供对元数据的 CRUD 操作,而JobExplorer提供对元数据的只读操作。但是,与批处理操作员通常一起使用时,这些操作一起执行常见的监视任务(如停止,重新启动或汇总作业)时最有用。 Spring Batch 通过JobOperator接口提供了这些类型的操作:
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}
上面的操作表示来自许多不同接口的方法,例如JobLauncher,JobRepository,JobExplorer和JobRegistry。因此,提供的JobOperator,SimpleJobOperator的实现具有许多依赖性:
<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean>
Note
如果您在作业存储库上设置了表前缀,请不要忘记也在作业资源 Management 器上进行设置。
4.6.4 JobParametersIncrementer
JobOperator上的大多数方法都是不言自明的,而更详细的解释可以在接口的 javadoc上找到。但是,startNextInstance方法值得注意。此方法将始终启动Job的新实例。如果JobExecution中存在严重问题并且需要从头重新开始Job,这将非常有用。但是与JobLauncher不同,后者需要一个新的JobParameters对象,如果参数与以前的任何一组参数都不相同,该对象将触发新的JobInstance,startNextInstance方法将使用与Job绑定的JobParametersIncrementer来将Job强制为新实例:
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}
JobParametersIncrementer的约定是,给定JobParameters对象,它将通过递增其可能包含的任何必要值来返回“下一个” JobParameters对象。此策略很有用,因为该框架无法知道JobParameters的哪些更改使其成为“下一个”实例。例如,如果JobParameters中唯一的值是日期,并且应该创建下一个实例,那么该值应该增加一天吗?还是一周(例如,如果工作是每周一次)?对于有助于识别Job的任何数值,都可以这样说,如下所示:
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
}
在此示例中,键为“ run.id”的值用于区分JobInstances。如果传入的JobParameters为空,则可以假定Job从未运行过,因此可以返回其初始状态。但是,如果不是,则将获得旧值,将其增加一并返回。增量器可以通过名称空间中的’incrementer’属性与Job关联:
<job id="footballJob" incrementer="sampleIncrementer">
...
</job>
4.6.5 停止作业
JobOperator`最常见的用例之一是正常停止`Job:
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next());
关闭不是立即关闭的,因为没有办法强制立即关闭,尤其是当执行当前在框架无法控制的开发人员代码中时,例如业务服务。但是,一旦控制权返回到框架,它将把当前StepExecution的状态设置为BatchStatus.STOPPED,保存它,然后对JobExecution进行同样的操作,然后再完成操作。
4.6.6 中止工作
可以重新启动FAILED的作业执行(如果作业是可重新启动的)。框架不会重新启动状态为ABANDONED的作业执行。 ABANDONED状态还用于步骤执行中,以在重新启动的作业执行中将其标记为可跳过:如果作业正在执行,并且在上一个失败的作业执行中遇到了标记为ABANDONED的步骤,它将 continue 进行下一个步骤(由作业流程定义和步骤执行退出状态决定)。
如果进程终止("kill -9"或服务器故障),则该作业当然不会运行,但是 JobRepository 无法知道,因为在进程终止之前没有人告诉过它。您必须手动告诉它,您知道执行失败或应被视为中止(将其状态更改为FAILED或ABANDONED)-这是一项业务决策,无法实现自动化。仅在不可重启或知道重启数据有效时,才将状态更改为FAILED。 Spring Batch Admin JobService中有一个 Util 可中止作业执行。
5. 配置步骤
如批处理域语言所讨论的,Step是一个域对象,该域对象封装了批处理作业的一个独立的 Sequences 阶段,并包含定义和控制实际批处理所需的所有信息。这是一个模糊的描述,因为任何给定Step的内容都由开发人员自行编写Job来决定。步骤可以像开发人员所希望的那样简单或复杂。简单的Step可能会将文件中的数据加载到数据库中,几乎不需要代码。 (取决于所使用的实现方式)较复杂的Step可能具有复杂的业务规则,这些规则将在处理过程中应用。
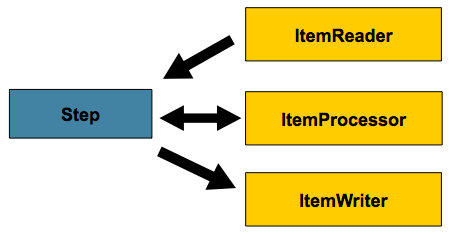
5.1 块处理
Spring Batch 在其最常见的实现中使用“面向块的”处理风格。面向块的处理是指一次读取一个数据,并在事务边界内创建要写出的“块”。从ItemReader读取一项,将其交给ItemProcessor并进行汇总。一旦读取的 Item 数等于提交间隔,就通过 ItemWriter 写入整个块,然后提交事务。
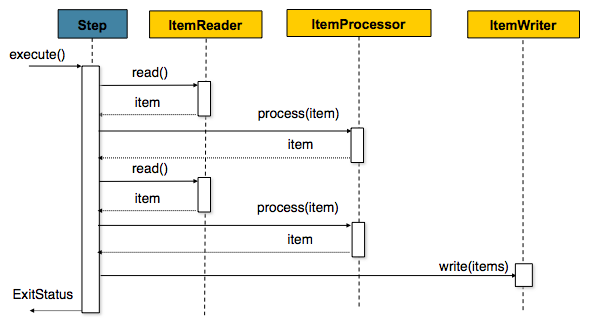
下面是上述相同概念的代码表示:
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read()
Object processedItem = itemProcessor.process(item);
items.add(processedItem);
}
itemWriter.write(items);
5.1.1 配置步骤
尽管Step所需的依赖项列表相对较短,但它是一个极其复杂的类,可能包含许多协 Writer。为了简化配置,可以使用 Spring Batch 名称空间:
<job id="sampleJob" job-repository="jobRepository">
<step id="step1">
<tasklet transaction-manager="transactionManager">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job>
上面的配置代表创建面向 Item 的步骤所需的唯一依赖项:
- reader-提供处理 Item 的
ItemReader。 - writer-处理
ItemReader提供的 Item 的ItemWriter。 - transaction-manager-Spring 的
PlatformTransactionManager,将用于在处理期间开始和提交事务。 - job-repository-
JobRepository,将用于在处理过程中(即在提交之前)定期存储StepExecution和ExecutionContext。对于内联\ (在 内定义),它是\ 元素上的一个属性;对于独立步骤,它定义为\ 的属性。 - commit-interval-提交事务之前将要处理的 Item 数。
应当注意,作业存储库默认为“ jobRepository”,而事务 Management 器默认为“ transactionManger”。此外,ItemProcessor是可选的,不是必需的,因为该 Item 可以直接从 Reader 传递给编写器。
5.1.2 从父步骤继承
如果一组Step共享相似的配置,则定义一个“父” Step可能会有所帮助,具体的Step可以从中继承属性。类似于 Java 中的类继承,“子” Step将其元素和属性与父类结合在一起。子代还将覆盖父代的任何Step。
在下面的示例中,Step“ concreteStep1”将从“ parentStep”继承。它将使用’itemReader’,’itemProcessor’,’itemWriter’,startLimit = 5 和 allowStartIfComplete = true 实例化。另外,由于被“ concreteStep1”覆盖,所以 commitInterval 将为“ 5”:
<step id="parentStep">
<tasklet allow-start-if-complete="true">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
<step id="concreteStep1" parent="parentStep">
<tasklet start-limit="5">
<chunk processor="itemProcessor" commit-interval="5"/>
</tasklet>
</step>
在 job 元素内的步骤上,仍然需要 id 属性。这有两个原因:
- 保留 StepExecution 时,该 ID 将用作步骤名称。如果在一个作业中的多个步骤中引用了同一独立步骤,则将发生错误。
- 如本章稍后所述,在创建作业流程时,下一个属性应引用流程中的步骤,而不是独立步骤。
Abstract Step
有时可能有必要定义不是完整的Step配置的父级Step。例如,如果将 Reader,Writer 和 Tasklet 属性保留为Step配置,则初始化将失败。如果必须定义一个没有这些属性的父对象,则应使用“抽象”属性。 “抽象” Step将不会被实例化;它仅用于扩展。
在下面的示例中,如果Step“ abstractParentStep”未声明为抽象,则不会实例化。 Step“ concreteStep2”将具有“ itemReader”,“ itemWriter”和 commitInterval = 10.
<step id="abstractParentStep" abstract="true">
<tasklet>
<chunk commit-interval="10"/>
</tasklet>
</step>
<step id="concreteStep2" parent="abstractParentStep">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"/>
</tasklet>
</step>
Merging Lists
Step上的一些可配置元素是列表;例如,\ 元素。如果父级和子级Step都声明了\ 元素,则子级的列表将覆盖父级的列表。为了允许孩子将其他侦听器添加到 parent 定义的列表中,每个列表元素都具有“合并”属性。如果该元素指定 merge =“ true”,则子级列表将与父级列表合并,而不是覆盖它。
在以下示例中,将创建Step“ concreteStep3”,并将两个侦听器:listenerOne和listenerTwo:
<step id="listenersParentStep" abstract="true">
<listeners>
<listener ref="listenerOne"/>
<listeners>
</step>
<step id="concreteStep3" parent="listenersParentStep">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="5"/>
</tasklet>
<listeners merge="true">
<listener ref="listenerTwo"/>
<listeners>
</step>
5.1.3 提交间隔
如上所述,一个步骤读取和写入 Item,并使用提供的PlatformTransactionManager定期提交。提交间隔为 1 时,它将在写入每个单独的 Item 后提交。在许多情况下,这并不理想,因为开始和提交事务非常昂贵。理想情况下,最好在每个事务中处理尽可能多的 Item,这完全取决于要处理的数据类型和与之交互的资源。因此,可以配置在提交中处理的 Item 数。
<job id="sampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job>
在上面的示例中,每个事务中将处理 10 个 Item。在处理开始时,事务开始,并且每次在ItemReader上调用 read 时,计数器都会递增。当它达到 10 时,聚合项的列表将传递到ItemWriter,事务将被提交。
5.1.4 配置重新启动步骤
在第 4 章,配置和运行作业中,讨论了重新启动Job。重新启动对步骤有很多影响,因此可能需要一些特定的配置。
设置 StartLimit
在许多情况下,您可能希望控制Step的启动次数。例如,可能需要配置特定的Step使其仅运行一次,因为它会使某些必须手动修复的资源无效,然后才能再次运行它。这可以在步骤级别上配置,因为不同的步骤可能有不同的要求。只能执行一次的Step与可以无限运行的Step作为同一Job的一部分存在。以下是启动限制配置示例:
<step id="step1">
<tasklet start-limit="1">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
上面的简单步骤只能运行一次。尝试再次运行它会引发异常。应该注意的是,开始限制的默认值为Integer.MAX_VALUE。
重新开始完成的步骤
对于可重新启动的作业,可能有一个或多个步骤应始终运行,无论它们是否第一次成功。一个示例可能是验证步骤,或者是Step在处理之前清理资源。在正常处理重新启动的作业期间,状态为“已完成”(表示已成功完成)的任何步骤都将被跳过。将 allow-start-if-complete 设置为“ true”将覆盖此设置,以便该步骤将始终运行:
<step id="step1">
<tasklet allow-start-if-complete="true">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
步骤重新启动配置示例
<job id="footballJob" restartable="true">
<step id="playerload" next="gameLoad">
<tasklet>
<chunk reader="playerFileItemReader" writer="playerWriter"
commit-interval="10" />
</tasklet>
</step>
<step id="gameLoad" next="playerSummarization">
<tasklet allow-start-if-complete="true">
<chunk reader="gameFileItemReader" writer="gameWriter"
commit-interval="10"/>
</tasklet>
</step>
<step id="playerSummarization">
<tasklet start-limit="3">
<chunk reader="playerSummarizationSource" writer="summaryWriter"
commit-interval="10"/>
</tasklet>
</step>
</job>
上面的示例配置适用于加载有关足球 match 的信息并对其进行汇总的作业。它包含三个步骤:playerLoad,gameLoad 和 playerSummarization。 playerLoad Step从平面文件中加载玩家信息,而 gameLoad Step对游戏也是如此。最后的Step,playerSummarization,然后根据提供的游戏汇总每个玩家的统计信息。假定“ playerLoad”加载的文件仅必须加载一次,但是“ gameLoad”将加载在特定目录中找到的所有游戏,并在将它们成功加载到数据库后将其删除。结果,playerLoad Step不包含其他配置。它几乎可以无限启动,如果完成,将被跳过。但是,’gameLoad’Step每次都需要运行,以防自上次执行以来删除了多余的文件。为了始终启动,将“ allow-start-if-complete”设置为“ true”。 (假设装入的数据库表游戏具有过程指示器,以确保可以通过汇总步骤正确找到新游戏)。摘要Step是Job中最重要的摘要,其初始限制为 3.这很有用,因为如果步骤连续失败,则会将新的退出代码返回给控制作业执行的操作员,并且在进行人工干预之前,不允许再次启动。
Note
该工作仅出于示例目的,与示例 Item 中找到的 footballJob 不同。
Run 1:
- playerLoad 已执行并成功完成,将 400 位玩家添加到“ PLAYERS”表中。
- 执行 gameLoad 并处理 11 个值得游戏数据的文件,并将其内容加载到“ GAMES”表中。
- playerSummarization 开始处理,并在 5 分钟后失败。
Run 2:
- playerLoad 未运行,因为它已经成功完成,并且 allow-start-if-complete 为’false’(默认值)。
- gameLoad 再次执行并处理另外 2 个文件,并将它们的内容也加载到“ GAMES”表中(带有过程指示器,指示它们尚未处理)
- playerSummarization 开始处理所有剩余的游戏数据(使用过程指示器进行过滤),并在 30 分钟后再次失败。
Run 3:
- playerLoad 未运行,因为它已经成功完成,并且 allow-start-if-complete 为’false’(默认值)。
- gameLoad 再次执行并处理另外 2 个文件,并将它们的内容也加载到“ GAMES”表中(带有过程指示器,指示它们尚未处理)
- playerSummarization 没有开始,并且作业被立即终止,因为这是 playerSummarization 的第三次执行,并且其限制仅为 2.必须提高限制,或者必须将
Job作为新的JobInstance执行。
5.1.5 配置跳过逻辑
在许多情况下,处理时遇到的错误不应导致Step失败,而应跳过这些错误。通常这是必须由了解数据本身及其含义的人做出的决定。例如,财务数据可能无法跳过,因为它会导致资金被转移,这需要完全准确。另一方面,加载供应商列表可能会导致跳过。如果由于格式错误或缺少必要的信息而未加载供应商,则可能不会出现问题。通常,这些不良记录也会被记录下来,稍后在讨论侦听器时将予以覆盖。
<step id="step1">
<tasklet>
<chunk reader="flatFileItemReader" writer="itemWriter"
commit-interval="10" skip-limit="10">
<skippable-exception-classes>
<include class="org.springframework.batch.item.file.FlatFileParseException"/>
</skippable-exception-classes>
</chunk>
</tasklet>
</step>
在此示例中,使用了FlatFileItemReader,并且在任何时候抛出FlatFileParseException都会被跳过并计入总跳过限制 10.在步骤执行过程中,分别对读取,处理和写入的跳过进行计数,该限制适用于所有人。一旦达到跳过限制,找到的下一个异常将导致该步骤失败。
上面的示例的一个问题是除FlatFileParseException之外的任何其他异常都将导致Job失败。在某些情况下,这可能是正确的行为。但是,在其他情况下,可能更容易确定哪些异常应导致失败并跳过其他所有操作:
<step id="step1">
<tasklet>
<chunk reader="flatFileItemReader" writer="itemWriter"
commit-interval="10" skip-limit="10">
<skippable-exception-classes>
<include class="java.lang.Exception"/>
<exclude class="java.io.FileNotFoundException"/>
</skippable-exception-classes>
</chunk>
</tasklet>
</step>
通过“包含” java.lang.Exception作为可跳过的异常类,该配置指示所有Exception都是可跳过的。但是,通过“排除” java.io.FileNotFoundException,配置将可跳过的异常类的列表优化为全部Exception 除 FileNotFoundException。如果遇到任何排除在外的异常类将是致命的(即不被跳过)。
对于遇到的任何异常,可跳过性将由类层次结构中最接近的超类确定。任何未分类的异常将被视为“致命”异常。 <include/>和<exclude/>元素的 Sequences 无关紧要。
5.1.6 配置重试逻辑
在大多数情况下,您希望异常导致跳过或Step失败。但是,并非所有 exception 都是确定性的。如果在读取时遇到FlatFileParseException,则该记录将始终被抛出;重置ItemReader将无济于事。但是,对于其他异常,例如DeadlockLoserDataAccessException,它指示当前进程已尝试更新另一个进程已锁定的记录,await 并重试可能会导致成功。在这种情况下,应配置重试:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"
commit-interval="2" retry-limit="3">
<retryable-exception-classes>
<include class="org.springframework.dao.DeadlockLoserDataAccessException"/>
</retryable-exception-classes>
</chunk>
</tasklet>
</step>
Step允许限制单个 Item 的重试次数,以及“可重试”的 exception 列表。有关重试工作方式的更多详细信息,请参见第 9 章,重试。
5.1.7 控制回滚
默认情况下,无论重试还是跳过,从ItemWriter引发的任何异常都将导致由Step控制的事务回滚。如果如上所述配置了 skip,则从ItemReader引发的异常不会导致回滚。但是,在许多情况下,从ItemWriter引发的异常不应导致回滚,因为没有采取任何行动来使事务无效。因此,可以为Step配置一系列不应引起回滚的异常。
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
<no-rollback-exception-classes>
<include class="org.springframework.batch.item.validator.ValidationException"/>
</no-rollback-exception-classes>
</tasklet>
</step>
Transactional Readers
ItemReader的基本 Contract 是仅向前。该步骤可缓冲读取器的 Importing,因此在回滚的情况下,无需从读取器中重新读取 Item。但是,在某些情况下,Reader 是构建在诸如 JMS 队列之类的事务资源之上的。在这种情况下,由于队列与回滚的事务相关,因此将从队列中拉出的消息放回去。因此,可以将步骤配置为不缓冲 Item:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"
is-reader-transactional-queue="true"/>
</tasklet>
</step>
5.1.8 事务属性
事务属性可用于控制隔离,传播和超时设置。可以在 spring 核心文档中找到有关设置事务属性的更多信息。
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
<transaction-attributes isolation="DEFAULT"
propagation="REQUIRED"
timeout="30"/>
</tasklet>
</step>
5.1.9 在步骤中注册 ItemStreams
该步骤必须在其生命周期的必要时点处理ItemStream回调。 (有关ItemStream界面的更多信息,请参考第 6.4 节“ ItemStream”),这对于步骤失败至关重要,并且可能需要重新启动,因为ItemStream接口是该步骤获取有关两次执行之间的持久状态所需信息的地方。
如果ItemReader,ItemProcessor或ItemWriter本身实现ItemStream接口,则将自动注册这些接口。任何其他流都需要单独注册。这通常是存在间接依赖性的情况,例如将委托注入到读取器和写入器中。可以通过’streams’元素在Step上注册流,如下所示:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="compositeWriter" commit-interval="2">
<streams>
<stream ref="fileItemWriter1"/>
<stream ref="fileItemWriter2"/>
</streams>
</chunk>
</tasklet>
</step>
<beans:bean id="compositeWriter"
class="org.springframework.batch.item.support.CompositeItemWriter">
<beans:property name="delegates">
<beans:list>
<beans:ref bean="fileItemWriter1" />
<beans:ref bean="fileItemWriter2" />
</beans:list>
</beans:property>
</beans:bean>
在上面的示例中,CompositeItemWriter不是ItemStream,但是它的两个委托都是。因此,必须将两个委托 Writer 都明确注册为流,以便框架正确处理它们。 ItemReader不需要显式注册为流,因为它是Step的直接属性。现在,该步骤将可重新启动,并且如果发生故障,读取器和写入器的状态将正确保留。
5.1.10 拦截步骤执行
就像Job一样,在执行Step期间会发生许多事件,用户可能需要执行某些功能。例如,为了写出需要页脚的平面文件,必须在Step完成时通知ItemWriter,以便页脚可以写入。这可以通过许多Step作用域侦听器之一来完成。
任何实现StepListenerextensions 之一的类(但由于接口本身是空的,因此不能实现该接口本身)可以通过 listeners 元素应用于步骤。 listeners 元素在步骤,tasklet 或块声明中有效。建议您在其功能适用的级别声明监听器,或者如果它具有多种功能(例如StepExecutionListener和ItemReadListener),则在其适用的最细粒度级别声明监听器(在给定的示例中为大块)。
<step id="step1">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="10"/>
<listeners>
<listener ref="chunkListener"/>
</listeners>
</tasklet>
</step>
如果使用命名空间<step>元素或*StepFactoryBean工厂之一,则本身实现StepListener接口之一的ItemReader,ItemWriter或ItemProcessor将自动向Step注册。这仅适用于直接注入Step的组件:如果侦听器嵌套在另一个组件中,则需要对其进行显式注册(如上所述)。
除了StepListener接口之外,还提供 Comments 来解决相同的问题。普通的旧 Java 对象可以使用带有这些注解的方法,然后将其转换为相应的StepListener类型。Comments 诸如ItemReader或ItemWriter或Tasklet之类的块组件的自定义实现也是很常见的。 XML 解析器针对<listener/>元素对 Comments 进行了分析,因此您所需要做的就是使用 XML 名称空间通过一个步骤注册侦听器。
StepExecutionListener
StepExecutionListener代表Step执行的最通用的侦听器。它允许在Step开始之前和结束之后发出通知,无论它是正常结束还是失败:
public interface StepExecutionListener extends StepListener {
void beforeStep(StepExecution stepExecution);
ExitStatus afterStep(StepExecution stepExecution);
}
ExitStatus是afterStep的返回类型,以使侦听器有机会修改在Step完成时返回的退出代码。
与此接口对应的 Comments 为:
@BeforeStep@AfterStep
ChunkListener
块定义为在事务范围内处理的 Item。在每个提交间隔提交事务都会提交一个“块”。 ChunkListener对于在块开始处理之前或块成功完成之后执行逻辑很有用:
public interface ChunkListener extends StepListener {
void beforeChunk();
void afterChunk();
}
在事务开始之后但在ItemReader上调用read之前,将调用beforeChunk方法。相反,afterChunk在提交块之后被调用(如果发生回滚则根本不调用)。
与此接口对应的 Comments 为:
@BeforeChunk@AfterChunk
当没有块声明时,可以应用ChunkListener:它是TaskletStep负责调用ChunkListener,因此它也适用于非面向 Item 的 Tasklet(在 Tasklet 之前和之后调用)。
ItemReadListener
在上面讨论跳过逻辑时,曾提到记录跳过的记录可能会有所帮助,以便以后进行处理。如果出现读取错误,可以使用ItemReaderListener:完成
public interface ItemReadListener<T> extends StepListener {
void beforeRead();
void afterRead(T item);
void onReadError(Exception ex);
}
每次在ItemReader上调用read之前,将调用beforeRead方法。每次成功调用read之后,将调用afterRead方法,并将传递已读取的 Item。如果读取时出错,则将调用onReadError方法。将提供遇到的异常,以便可以将其记录下来。
与此接口对应的 Comments 为:
@BeforeRead@AfterRead@OnReadError
ItemProcessListener
与ItemReadListener一样,可以将 Item 的处理“侦听”为:
public interface ItemProcessListener<T, S> extends StepListener {
void beforeProcess(T item);
void afterProcess(T item, S result);
void onProcessError(T item, Exception e);
}
beforeProcess方法将在ItemProcessor上的process之前调用,并交给将要处理的 Item。成功处理该 Item 后,将调用afterProcess方法。如果处理时出错,则将调用onProcessError方法。将提供遇到的异常和尝试处理的 Item,以便可以记录它们。
与此接口对应的 Comments 为:
@BeforeProcess@AfterProcess@OnProcessError
ItemWriteListener
可以使用ItemWriteListener来“听”Item 的书写:
public interface ItemWriteListener<S> extends StepListener {
void beforeWrite(List<? extends S> items);
void afterWrite(List<? extends S> items);
void onWriteError(Exception exception, List<? extends S> items);
}
beforeWrite方法将在ItemWriter上的write之前被调用,并且将被写入的内容交给该方法。成功写入 Item 后,将调用afterWrite方法。如果写入时出错,则将调用onWriteError方法。将提供遇到的异常和尝试写入的 Item,以便可以记录它们。
与此接口对应的 Comments 为:
@BeforeWrite@AfterWrite@OnWriteError
SkipListener
ItemReadListener,ItemProcessListener和ItemWriteListener都提供了用于通知错误的机制,但没有一个机制会通知您实际上已跳过了一条记录。例如,即使重试并成功执行onWriteError也会被调用。因此,有一个单独的界面可用于跟踪跳过的 Item:
public interface SkipListener<T,S> extends StepListener {
void onSkipInRead(Throwable t);
void onSkipInProcess(T item, Throwable t);
void onSkipInWrite(S item, Throwable t);
}
每次在阅读过程中跳过某项都会调用onSkipInRead。应当注意,回滚可能导致同一项被注册为多次跳过。写入时跳过某项时,将调用onSkipInWrite。由于已成功读取(而不是跳过)该 Item,因此还提供了该 Item 本身作为参数。
与此接口对应的 Comments 为:
@OnSkipInRead@OnSkipInWrite@OnSkipInProcess
跳过侦听器和事务
SkipListener最常见的用例之一是注销跳过的 Item,以便可以使用另一个批处理甚至人工流程来评估和解决导致跳过的问题。由于在很多情况下原始事务可能会被回滚,因此 Spring Batch 提供了两个保证:
- 适当的跳过方法(取决于错误发生的时间)将仅对每个 Item 调用一次。
SkipListener将始终在事务提交之前被调用。这是为了确保ItemWriter内的故障不会使侦听器调用的任何事务资源回滚。
5.2 TaskletStep
块处理不是在Step中处理的唯一方法。如果Step必须包含一个简单的存储过程调用怎么办?您可以将调用实现为ItemReader,并在过程完成后返回 null,但这有点不自然,因为需要使用无操作ItemWriter。 Spring Batch 为此场景提供了TaskletStep。
Tasklet是一个简单的接口,具有一个方法execute,它将由TaskletStep反复调用,直到它返回RepeatStatus.FINISHED或引发异常以指示失败。对Tasklet的每次调用都包装在一个事务中。 Tasklet实现者可以调用存储过程,脚本或简单的 SQL 更新语句。要创建TaskletStep,\ 元素的’ref’属性应引用一个定义Tasklet对象的 bean。在\ 内不应使用\ 元素:
<step id="step1">
<tasklet ref="myTasklet"/>
</step>
Note
如果TaskletStep实现了此接口,它将自动将 Tasklet 注册为StepListener
5.2.1 TaskletAdapter
与ItemReader和ItemWriter接口的其他适配器一样,Tasklet接口包含一个实现,可以使其自身适应任何现有的类:TaskletAdapter。一个可能有用的示例是现有的 DAO,用于更新一组记录上的标志。 TaskletAdapter可用于调用此类,而不必为Tasklet接口编写适配器:
<bean id="myTasklet" class="o.s.b.core.step.tasklet.MethodInvokingTaskletAdapter">
<property name="targetObject">
<bean class="org.mycompany.FooDao"/>
</property>
<property name="targetMethod" value="updateFoo" />
</bean>
5.2.2 Tasklet 实现示例
许多批处理作业包含必须在主处理开始之前执行的步骤,以设置各种资源,或者在处理完成后清理这些资源。对于需要大量处理文件的工作,通常需要在成功将文件上载到其他位置后在本地删除某些文件。下面的示例摘自 Spring Batch 示例 Item,是一个Tasklet实现,它具有以下职责:
public class FileDeletingTasklet implements Tasklet, InitializingBean {
private Resource directory;
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
File dir = directory.getFile();
Assert.state(dir.isDirectory());
File[] files = dir.listFiles();
for (int i = 0; i < files.length; i++) {
boolean deleted = files[i].delete();
if (!deleted) {
throw new UnexpectedJobExecutionException("Could not delete file " +
files[i].getPath());
}
}
return RepeatStatus.FINISHED;
}
public void setDirectoryResource(Resource directory) {
this.directory = directory;
}
public void afterPropertiesSet() throws Exception {
Assert.notNull(directory, "directory must be set");
}
}
上面的Tasklet实现将删除给定目录中的所有文件。应当注意,execute方法将仅被调用一次。剩下的就是从Step引用Tasklet:
<job id="taskletJob">
<step id="deleteFilesInDir">
<tasklet ref="fileDeletingTasklet"/>
</step>
</job>
<beans:bean id="fileDeletingTasklet"
class="org.springframework.batch.sample.tasklet.FileDeletingTasklet">
<beans:property name="directoryResource">
<beans:bean id="directory"
class="org.springframework.core.io.FileSystemResource">
<beans:constructor-arg value="target/test-outputs/test-dir" />
</beans:bean>
</beans:property>
</beans:bean>
5.3 控制步骤流程
由于能够将一个拥有的工作中的各个步骤组合在一起,因此需要能够控制工作如何从一个步骤“流向”另一个步骤。 Step的失败并不一定意味着Job应该会失败。此外,可能有不止一种类型的“成功”确定接下来应执行哪个Step。根据一组步骤的配置方式,某些步骤甚至可能根本无法处理。
5.3.1Sequences 流
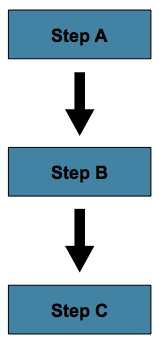
最简单的流程场景是一项工作,其中所有步骤都按 Sequences 执行:
这可以使用 step 元素的’next’属性来实现:
<job id="job">
<step id="stepA" parent="s1" next="stepB" />
<step id="stepB" parent="s2" next="stepC"/>
<step id="stepC" parent="s3" />
</job>
在上述情况下,“步骤 A”将首先执行,因为它是列出的第一个Step。如果“步骤 A”正常完成,则将执行“步骤 B”,依此类推。但是,如果“步骤 A”失败,则整个Job将失败,并且“步骤 B”将不会执行。
Note
使用 Spring Batch 名称空间时,配置中列出的第一步将*总是*成为Job执行的第一步。其他步骤元素的 Sequences 无关紧要,但是第一步必须始终首先出现在 xml 中。
5.3.2 条件流
在上面的示例中,只有两种可能性:
Step成功,应执行下一个Step。Step失败,因此Job应该失败。
在许多情况下,这可能就足够了。但是,如果Step的故障应触发一个不同的Step而不是引起故障的情况呢?
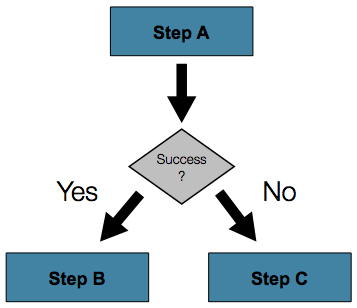
为了处理更复杂的场景,Spring Batch 名称空间允许在 step 元素内定义转换元素。一种这样的过渡是“下一个”元素。与“ next”属性类似,“ next”元素将告诉Job接下来执行哪个Step。但是,与该属性不同,给定Step允许任何数量的“ next”元素,并且在失败的情况下没有默认行为。这意味着,如果使用过渡元素,则必须明确定义Step过渡的所有行为。还要注意,单个步骤不能同时具有“下一个”属性和过渡元素。
next 元素指定要匹配的模式以及下一步要执行的步骤:
<job id="job">
<step id="stepA" parent="s1">
<next on="*" to="stepB" />
<next on="FAILED" to="stepC" />
</step>
<step id="stepB" parent="s2" next="stepC" />
<step id="stepC" parent="s3" />
</job>
过渡元素的“ on”属性使用简单的模式匹配方案来匹配Step的执行所产生的ExitStatus。模式中仅允许使用两个特殊字符:
- “ *”将零个或多个字符
- “?”将完全匹配一个字符
例如,“ c * t”将匹配“ cat”和“ count”,而“ c?t”将匹配“ cat”但不匹配“ count”。
尽管Step上的过渡元素数量没有限制,但是如果Step的执行导致ExitStatus未被元素覆盖,则框架将引发异常,并且Job将会失败。该框架将自动排序从最具体到最不具体的过渡。这意味着即使在上面的示例中将元素替换为“ stepA”,“ _ FAILED”的ExitStatus仍将进入“ stepC”。
批次状态与退出状态
为条件流配置Job时,了解BatchStatus和ExitStatus之间的区别很重要。 BatchStatus是同时为JobExecution和StepExecution的属性的枚举,框架使用它来记录Job或Step的状态。它可以是以下值之一:COMPLETED,STARTING,STARTED,STOPPING,STOPPED,FAILED,ABANDONED 或 UNKNOWN。其中大多数是不言自明的:COMPLETED 是在步骤或作业成功完成时设置的状态,在失败时设置 FAILED,等等。上面的示例包含以下“ next”元素:
<next on="FAILED" to="stepB" />
乍一 Watch,似乎“ on”属性引用了它所属的Step的BatchStatus。但是,它实际上引用了Step的ExitStatus。顾名思义,ExitStatus代表Step完成执行后的状态。更具体地说,上面的“ next”元素引用ExitStatus的退出代码。要用英语编写,它说:“如果退出代码失败,则转到步骤 B”。默认情况下,退出代码始终与该步骤的BatchStatus相同,这就是上面的 Importing 起作用的原因。但是,如果退出代码需要不同怎么办?一个很好的例子来自 samplesItem 中的 skip sample 作业:
<step id="step1" parent="s1">
<end on="FAILED" />
<next on="COMPLETED WITH SKIPS" to="errorPrint1" />
<next on="*" to="step2" />
</step>
上面的步骤有三种可能性:
Step失败,在这种情况下作业应该失败。Step成功完成。Step已成功完成,但退出代码为“ COMPLETED WITH SKIPS”。在这种情况下,应运行不同的步骤来处理错误。
以上配置将起作用。但是,需要根据跳过记录的执行条件来更改退出代码:
public class SkipCheckingListener extends StepExecutionListenerSupport {
public ExitStatus afterStep(StepExecution stepExecution) {
String exitCode = stepExecution.getExitStatus().getExitCode();
if (!exitCode.equals(ExitStatus.FAILED.getExitCode()) &&
stepExecution.getSkipCount() > 0) {
return new ExitStatus("COMPLETED WITH SKIPS");
}
else {
return null;
}
}
}
上面的代码是StepExecutionListener,首先检查以确保Step成功,然后检查StepExecution上的跳过计数是否大于 0.如果同时满足这两个条件,则新的ExitStatus的退出代码为“ COMPLETED WITH SKIPS”返回。
5.3.3 配置停止
在讨论BatchStatus 和 ExitStatus之后,您可能会想知道如何为Job确定BatchStatus和ExitStatus。通过已执行的代码确定Step的这些状态时,将基于配置确定Job的状态。
到目前为止,讨论的所有作业配置都至少具有一个没有过渡的最终Step。例如,执行以下步骤后,Job将结束:
<step id="stepC" parent="s3"/>
如果未为Step定义过渡,则Job的状态将定义如下:
- 如果
Step以ExitStatusFAILED 结尾,则Job的BatchStatus和ExitStatus都将变为 FAILED。 - 否则,
Job的BatchStatus和ExitStatus都将被完成。
尽管这种终止批处理作业的方法对于某些批处理作业(例如简单的 Sequences 步骤作业)已足够,但是可能需要自定义定义的作业停止方案。为此,Spring Batch 提供了三个过渡元素来停止Job(除了我们之前讨论的“next” element之外)。这些停止元素中的每一个都将停止具有特定BatchStatus的Job。重要的是要注意,停止过渡元素将不会对Job中任何Step的BatchStatus或ExitStatus产生影响:这些元素只会影响Job的最终状态。例如,作业中的每个步骤都可能具有“已失败”状态,但是作业具有“已完成”状态,反之亦然。
“结束”元素
‘end’元素指示Job以BatchStatus的 COMPLETED 停止。状态为 COMPLETED 的Job无法重新启动(框架将抛出JobInstanceAlreadyCompleteException)。 ‘end’元素还允许使用可选的’exit-code’属性,该属性可用于自定义Job的ExitStatus。如果未提供’exit-code’属性,则默认情况下ExitStatus将为“ COMPLETED”,以匹配BatchStatus。
在以下情况下,如果步骤 2 失败,则Job将以BatchStatus的 COMPLETED 停止,而ExitStatus的“ COMPLETED”停止,并且 step3 将不执行;否则,执行将移至步骤 3.请注意,如果步骤 2 失败,则Job将无法重新启动(因为状态为 COMPLETED)。
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<end on="FAILED"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">
“失败”元素
“失败”元素指示Job以BatchStatus的 FAILED 停止。与’end’元素不同,’fail’元素不会阻止Job重新启动。 ‘fail’元素还允许使用可选的’exit-code’属性,该属性可用于自定义Job的ExitStatus。如果未提供’exit-code’属性,则默认情况下ExitStatus为“ FAILED”,以匹配BatchStatus。
在以下情况下,如果步骤 2 失败,则Job将以BatchStatus失败而停止,而ExitStatus则为“早期终止”而停止,步骤 3 将不执行;否则,执行将移至步骤 3.此外,如果步骤 2 失败,并且Job重新启动,则将在步骤 2 再次开始执行。
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<fail on="FAILED" exit-code="EARLY TERMINATION"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">
“停止”元素
‘stop’元素指示Job以BatchStatus的 STOPPED 停止。停止Job可以暂时中断处理,以便操作员可以在重新启动Job之前采取一些措施。 ‘stop’元素需要一个’restart’属性,该属性指定Job is restarted时应该执行的步骤。
在以下情况下,如果 step1 以 COMPLETE 完成,则作业将停止。重新启动后,将在步骤 2 开始执行。
<step id="step1" parent="s1">
<stop on="COMPLETED" restart="step2"/>
</step>
<step id="step2" parent="s2"/>
5.3.4 程序流程决策
在某些情况下,可能需要比ExitStatus更多的信息来决定下一步执行哪个步骤。在这种情况下,可以使用JobExecutionDecider来辅助决策。
public class MyDecider implements JobExecutionDecider {
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
if (someCondition) {
return "FAILED";
}
else {
return "COMPLETED";
}
}
}
在作业配置中,“决策”标签将指定要使用的决策器以及所有转换。
<job id="job">
<step id="step1" parent="s1" next="decision" />
<decision id="decision" decider="decider">
<next on="FAILED" to="step2" />
<next on="COMPLETED" to="step3" />
</decision>
<step id="step2" parent="s2" next="step3"/>
<step id="step3" parent="s3" />
</job>
<beans:bean id="decider" class="com.MyDecider"/>
5.3.5 分流
到目前为止,所描述的每种情况都涉及一个Job,它以线性方式一次执行其Step。除了这种典型的样式外,Spring Batch 命名空间还允许使用“ split”元素使用并行流来配置作业。如下所示,“ split”元素包含一个或多个“ flow”元素,可以在其中定义整个单独的流。 “拆分”元素还可以包含任何先前讨论的过渡元素,例如“下一个”属性或“下一个”,“结束”,“失败”或“暂停”元素。
<split id="split1" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
5.3.6 外部化作业之间的流程定义和依赖性
可以将作业中的部分流程外部化为单独的 Bean 定义,然后重新使用。有两种方法可以做到这一点,第一种是简单地将流声明为对其他地方定义的引用:
<job id="job">
<flow id="job1.flow1" parent="flow1" next="step3"/>
<step id="step3" parent="s3"/>
</job>
<flow id="flow1">
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
像这样定义外部流程的作用仅仅是将外部流程中的步骤插入作业中,就好像它们已被内联声明一样。这样,许多作业可以引用相同的模板流,并将这些模板组成不同的逻辑流。这也是分离单个流的集成测试的好方法。
外部化流程的另一种形式是使用JobStep。 JobStep与FlowStep类似,但是实际上为指定流程中的步骤创建并启动了单独的作业执行。这是一个例子:
<job id="jobStepJob" restartable="true">
<step id="jobStepJob.step1">
<job ref="job" job-launcher="jobLauncher"
job-parameters-extractor="jobParametersExtractor"/>
</step>
</job>
<job id="job" restartable="true">...</job>
<bean id="jobParametersExtractor" class="org.spr...DefaultJobParametersExtractor">
<property name="keys" value="input.file"/>
</bean>
作业参数提取器是一种策略,用于确定Step的ExecutionContext如何转换为要执行的 Job 的JobParameters。 JobStep在您希望有一些更精细的选项来监视和报告作业和步骤时很有用。使用JobStep通常也可以很好地回答以下问题:“如何在作业之间创建依赖关系?”。这是将大型系统分解为较小的模块并控制作业流程的好方法。
5.4 作业和步骤属性的后期绑定
上面的 XML 和 Flat File 示例都使用 Spring Resource抽象来获取文件。之所以有效,是因为Resource有一个 getFile 方法,该方法返回java.io.File。可以使用标准 Spring 构造来配置 XML 和平面文件资源:
<bean id="flatFileItemReader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource"
value="file://outputs/20070122.testStream.CustomerReportStep.TEMP.txt" />
</bean>
上面的Resource将从指定的文件系统位置加载文件。请注意,绝对位置必须以双斜杠(“ //”)开头。在大多数 spring 应用程序中,此解决方案足够好,因为它们的名称在编译时就已知。但是,在批处理方案中,可能需要在运行时将文件名确定为作业的参数。可以使用-D 参数(即系统属性)解决此问题:
<bean id="flatFileItemReader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="${input.file.name}" />
</bean>
要使该解决方案起作用,所需要做的只是一个系统参数(-Dinput.file.name =“ file://file.txt”)。 (请注意,尽管此处可以使用PropertyPlaceholderConfigurer,但始终设置系统属性不是必需的,因为 Spring 中的ResourceEditor已经过滤并在系统属性上进行了占位符替换.)
通常,在批处理设置中,最好在作业的JobParameters中参数化文件名,而不是通过系统属性来访问文件名。为此,Spring Batch 允许后期绑定各种 Job 和 Step 属性:
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters['input.file.name']}" />
</bean>
可以通过相同的方式访问JobExecution和StepExecution级别ExecutionContext:
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobExecutionContext['input.file.name']}" />
</bean>
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{stepExecutionContext['input.file.name']}" />
</bean>
Note
任何使用后期绑定的 bean 必须使用 scope =“ step”声明。请参阅第 5.4.1 节“步骤范围”更多信息。
Note
如果您使用的是 Spring 3.0(或更高版本),则步进作用域 Bean 中的表达式将使用 Spring Expression Language,这是一种功能强大的通用语言,具有许多有趣的功能。为了提供向后兼容性,如果 Spring Batch 检测到存在较旧版本的 Spring,它将使用功能较弱且解析规则稍有不同的本机表达式语言。主要区别在于,上面示例中的 map 键不需要在 Spring 2.5 中用引号引起来,但是在 Spring 3.0 中引号是必需的。
5.4.1 步骤范围
上面所有的后期绑定示例都在 bean 定义中声明了“ step”的范围:
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters[input.file.name]}" />
</bean>
为了使用后期绑定,需要使用Step范围,因为在Step启动之前实际上无法实例化 bean,这样才能找到属性。因为默认情况下它不是 Spring 容器的一部分,所以必须使用batch命名空间来显式添加范围:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
<batch:job .../>
...
</beans>
或通过显式包含StepScope的 bean 定义(但不能同时包含两者):
<bean class="org.springframework.batch.core.scope.StepScope" />
5.4.2 工作范围
Spring Batch 3.0 中引入的 Job 作用域与配置中的 Step 作用域类似,但是是 Job 上下文的作用域,因此每个执行的作业只有一个这样的 bean 实例。此外,还提供了对使用#\ {}占位符从 JobContext 访问的引用的后期绑定的支持。使用此功能,可以从作业或作业执行上下文以及作业参数中提取 Bean 属性。例如。
<bean id="..." class="..." scope="job">
<property name="name" value="#{jobParameters[input]}" />
</bean>
<bean id="..." class="..." scope="job">
<property name="name" value="#{jobExecutionContext['input.name']}.txt" />
</bean>
因为默认情况下它不是 Spring 容器的一部分,所以必须使用batch名称空间显式添加范围:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
<batch:job .../>
...
</beans>
或通过显式包括JobScope的 bean 定义(但不能同时包含两者):
<bean class="org.springframework.batch.core.scope.JobScope" />
6. ItemReaders 和 ItemWriters
所有批处理都可以以其最简单的形式描述为读取大量数据,执行某种类型的计算或转换并写出结果。 Spring Batch 提供了三个关键接口来帮助执行批量读取和写入:ItemReader,ItemProcessor和ItemWriter。
6.1 ItemReader
尽管是一个简单的概念,但ItemReader是用于从许多不同类型的 Importing 中提供数据的方法。最一般的示例包括:
- 平面文件-平面文件 Item 读取器从平面文件中读取数据行,这些行通常描述记录的数据字段,该字段由文件中的固定位置定义或由某些特殊字符(例如逗号)分隔。
- XML-XML ItemReaders 独立于用于解析,Map 和验证对象的技术来处理 XML。Importing 数据允许根据 XSD 模式验证 XML 文件。
- 数据库-访问数据库资源以返回结果集,该结果集可以 Map 到对象以进行处理。默认的 SQL ItemReaders 调用
RowMapper来返回对象,如果需要重新启动,则跟踪当前行,存储基本统计信息,并提供一些事务增强功能,这将在后面进行解释。
还有更多的可能性,但本章将重点介绍基本的可能性。所有可用的 ItemReader 的完整列表可以在附录 A 中找到。
ItemReader是通用 Importing 操作的基本界面:
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException;
}
read方法定义了ItemReader的最基本 Contract;调用它返回一个 Item,如果没有剩余的 Item,则返回 null。一个 Item 可能代表文件中的一行,数据库中的一行或 XML 文件中的元素。通常期望将它们 Map 到可用的域对象(即 Trade,Foo 等),但 Contract 中没有要求这样做。
预计ItemReader接口的实现将仅转发。但是,如果基础资源是事务性的(例如 JMS 队列),则在回滚方案中,调用 read 可能会在后续调用中返回相同的逻辑项。还值得注意的是,ItemReader缺少要处理的 Item 不会导致引发异常。例如,配置有返回 0 结果的查询的数据库ItemReader只会在第一次调用read时返回 null。
6.2 ItemWriter
ItemWriter在功能上与ItemReader类似,但具有相反的运算。资源仍然需要定位,打开和关闭,但是它们的区别在于ItemWriter是写出而不是读入。对于数据库或队列,它们可能是插入,更新或发送。输出序列化的格式特定于每个批处理作业。
与ItemReader一样,ItemWriter是一个相当通用的接口:
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}
与ItemReader上的read一样,write提供ItemWriter的基本 Contract;只要打开,它将尝试写出传入的 Item 列表。因为通常期望将 Item“分批”在一起,然后输出,所以接口接受 Item 列表,而不是 Item 本身。写入列表后,可以执行任何必要的刷新操作,然后再从 write 方法返回。例如,如果写入一个 Hibernate DAO,则可以进行多个写入操作,每个 Item 一个。然后,Writer 可以在返回之前在休眠会话上调用 close。
6.3 ItemProcessor
ItemReader和ItemWriter接口对于它们的特定任务都非常有用,但是如果要在编写之前插入业务逻辑怎么办?读写的一种选择是使用复合模式:创建一个包含另一个ItemWriter的ItemWriter或一个包含另一个ItemReader的ItemReader。例如:
public class CompositeItemWriter<T> implements ItemWriter<T> {
ItemWriter<T> itemWriter;
public CompositeItemWriter(ItemWriter<T> itemWriter) {
this.itemWriter = itemWriter;
}
public void write(List<? extends T> items) throws Exception {
//Add business logic here
itemWriter.write(item);
}
public void setDelegate(ItemWriter<T> itemWriter){
this.itemWriter = itemWriter;
}
}
上面的类包含另一个ItemWriter,它在提供了一些业务逻辑后将其委托给该ItemWriter。该模式也可以很容易地用于ItemReader,也许可以基于主ItemReader提供的 Importing 来获取更多参考数据。如果您需要自己控制对write的调用,它也很有用。但是,如果您只想在实际写入之前“转换”传递给写入的 Item,则您自己不需要调用write:您只想修改该 Item。对于这种情况,Spring Batch 提供了ItemProcessor接口:
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}
ItemProcessor非常简单;给定一个对象,对其进行转换,然后返回另一个。提供的对象可以是或可以不是相同的类型。关键是,业务逻辑可以在流程中应用,并且完全取决于开发人员来创建。 ItemProcessor可以直接连接到步骤中,例如,假设ItemReader提供了 Foo 类型的类,则需要先将其转换为 Bar 类型。可以编写ItemProcessor来执行转换:
public class Foo {}
public class Bar {
public Bar(Foo foo) {}
}
public class FooProcessor implements ItemProcessor<Foo,Bar>{
public Bar process(Foo foo) throws Exception {
//Perform simple transformation, convert a Foo to a Bar
return new Bar(foo);
}
}
public class BarWriter implements ItemWriter<Bar>{
public void write(List<? extends Bar> bars) throws Exception {
//write bars
}
}
在上面非常简单的示例中,存在一个类Foo,一个类Bar和一个类FooProcessor,它们都坚持ItemProcessor接口。转换很简单,但是任何类型的转换都可以在这里完成。 BarWriter将用于写出Bar对象,如果提供任何其他类型,则会引发异常。同样,如果提供了Foo以外的任何内容,FooProcessor将引发异常。然后可以将FooProcessor注入到Step中:
<job id="ioSampleJob">
<step name="step1">
<tasklet>
<chunk reader="fooReader" processor="fooProcessor" writer="barWriter"
commit-interval="2"/>
</tasklet>
</step>
</job>
6.3.1 链接 ItemProcessor
执行单个转换在许多情况下很有用,但是如果您要“链接”多个ItemProcessor怎么办?这可以使用前面提到的复合图案来完成。要更新先前的单个转换,例如Foo将转换为Bar,然后将其转换为Foobar并写出:
public class Foo {}
public class Bar {
public Bar(Foo foo) {}
}
public class Foobar{
public Foobar(Bar bar) {}
}
public class FooProcessor implements ItemProcessor<Foo,Bar>{
public Bar process(Foo foo) throws Exception {
//Perform simple transformation, convert a Foo to a Bar
return new Bar(foo);
}
}
public class BarProcessor implements ItemProcessor<Bar,FooBar>{
public FooBar process(Bar bar) throws Exception {
return new Foobar(bar);
}
}
public class FoobarWriter implements ItemWriter<FooBar>{
public void write(List<? extends FooBar> items) throws Exception {
//write items
}
}
FooProcessor和BarProcessor可以“链接”在一起以得到结果Foobar:
CompositeItemProcessor<Foo,Foobar> compositeProcessor =
new CompositeItemProcessor<Foo,Foobar>();
List itemProcessors = new ArrayList();
itemProcessors.add(new FooTransformer());
itemProcessors.add(new BarTransformer());
compositeProcessor.setDelegates(itemProcessors);
与前面的示例一样,可以将复合处理器配置为Step:
<job id="ioSampleJob">
<step name="step1">
<tasklet>
<chunk reader="fooReader" processor="compositeProcessor" writer="foobarWriter"
commit-interval="2"/>
</tasklet>
</step>
</job>
<bean id="compositeItemProcessor"
class="org.springframework.batch.item.support.CompositeItemProcessor">
<property name="delegates">
<list>
<bean class="..FooProcessor" />
<bean class="..BarProcessor" />
</list>
</property>
</bean>
6.3.2 过滤记录
Item 处理器的一种典型用法是在将记录传递给 ItemWriter 之前过滤掉记录。过滤是一种不同于跳过的动作;跳过表示记录无效,而过滤仅表示不应写入记录。
例如,考虑一个批处理作业,该作业读取一个包含三种不同类型记录的文件:要插入的记录,要更新的记录和要删除的记录。如果系统不支持删除记录,则我们不希望将任何“删除”记录发送到ItemWriter。但是,由于这些记录实际上并不是不良记录,因此我们希望将其过滤掉,而不是跳过。结果,ItemWriter 将仅接收“插入”和“更新”记录。
要过滤记录,只需从ItemProcessor返回“ null”。框架将检测到结果为“ null”,并避免将该 Item 添加到传递给ItemWriter的记录列表中。与往常一样,从ItemProcessor引发的异常将导致跳过。
6.3.3 容错
回滚块时,可能会重新处理读取期间已缓存的 Item。如果将步骤配置为容错的(通常使用跳过或重试处理),则应以幂等的方式实现所使用的任何 ItemProcessor。通常,这将包括不对 ItemProcessor 的 Importing 项执行任何更改,而仅更新作为结果的实例。
6.4 ItemStream
ItemReader和ItemWriter都很好地满足了各自的目的,但是它们之间存在一个共同的问题,那就是需要另一个接口。通常,作为批处理作业范围的一部分,需要打开,关闭读取器和写入器,并需要一种持久化状态的机制:
public interface ItemStream {
void open(ExecutionContext executionContext) throws ItemStreamException;
void update(ExecutionContext executionContext) throws ItemStreamException;
void close() throws ItemStreamException;
}
在描述每种方法之前,我们应该提到ExecutionContext。同样实现ItemStream的ItemReader的 Client 端应在对read的任何调用之前先调用open,以打开文件等任何资源或获得连接。类似的限制适用于实现ItemStream的ItemWriter。如第 2 章所述,如果在ExecutionContext中找到了预期的数据,则可以使用它在初始状态以外的位置启动ItemReader或ItemWriter。相反,将调用close以确保安全释放在open期间分配的任何资源。调用update主要是为了确保当前保留的任何状态都已加载到提供的ExecutionContext中。在提交之前将调用此方法,以确保在提交之前将当前状态保留在数据库中。
在ItemStream的 Client 端是Step(来自 Spring Batch Core)的特殊情况下,将为每个StepExecution创建一个ExecutionContext,以允许用户存储特定执行的状态,并期望如果执行时返回该状态。相同的JobInstance重新启动。对于那些熟悉 Quartz 的人,其语义与 Quartz JobDataMap非常相似。
6.5 委托模式和步骤注册
请注意,CompositeItemWriter是委派模式的示例,在 Spring Batch 中很常见。委托本身可以实现回调接口StepListener。如果这样做的话,并且它们与 Spring Batch Core 一起作为Job中Step的一部分使用,那么几乎可以肯定他们需要手动向Step注册。如果直接实现该接口的ItemStream或StepListener接口,则直接注册到该步骤中的读取器,写入器或处理器将被自动注册。但是由于Step并不了解委托,因此需要将它们作为侦听器或流(或在适当时将两者同时注入)注入:
<job id="ioSampleJob">
<step name="step1">
<tasklet>
<chunk reader="fooReader" processor="fooProcessor" writer="compositeItemWriter"
commit-interval="2">
<streams>
<stream ref="barWriter" />
</streams>
</chunk>
</tasklet>
</step>
</job>
<bean id="compositeItemWriter" class="...CustomCompositeItemWriter">
<property name="delegate" ref="barWriter" />
</bean>
<bean id="barWriter" class="...BarWriter" />
6.6 平面文件
交换批量数据的最常见机制之一一直是平面文件。与 XML 具有定义其结构化(XSD)的公认标准不同,任何阅读平面文件的人都必须提前了解文件的结构。通常,所有平面文件都分为两种:定界文件和固定长度文件。分隔文件是指用逗号分隔分隔符的字段。固定长度文件具有设置长度的字段。
6.6.1 FieldSet
在 Spring Batch 中使用平面文件时,无论是用于 Importing 还是输出,最重要的类之一是FieldSet。许多体系结构和库都包含用于帮助您从文件读入的抽象,但是它们通常返回 String 或 String 数组。这真的只会让您半途而废。 FieldSet是 Spring Batch 的抽象,用于启用文件资源中字段的绑定。它使开发人员可以像处理数据库 Importing 一样使用文件 Importing。 FieldSet在概念上与 Jdbc ResultSet非常相似。 FieldSet 仅需要一个参数,即String标记数组。 (可选)您还可以在字段名称中进行配置,以便可以按索引或ResultSet之后的名称访问字段:
String[] tokens = new String[]{"foo", "1", "true"};
FieldSet fs = new DefaultFieldSet(tokens);
String name = fs.readString(0);
int value = fs.readInt(1);
boolean booleanValue = fs.readBoolean(2);
FieldSet界面上还有更多选项,例如Date,long,BigDecimal等。FieldSet的最大优点是,它提供了对平面文件 Importing 的一致解析。在处理由格式异常引起的错误或进行简单的数据转换时,它可以保持一致,而不是使每个批处理作业以潜在的意外方式进行不同的解析。
6.6.2 FlatFileItemReader
平面文件是最多包含二维(表格)数据的任何类型的文件。 FlatFileItemReader类有助于在 Spring Batch 框架中读取平面文件,该类提供了用于读取和解析平面文件的基本功能。 FlatFileItemReader的两个最重要的必需依赖项是Resource和LineMapper.。在下一部分中将进一步探讨LineMapper接口。 resource 属性表示一个 Spring Core Resource。可以在Spring 框架,第 5 章资源中找到说明如何创建此类 bean 的文档。因此,本指南将不涉及创建Resource对象的详细信息。但是,可以在下面找到文件系统资源的简单示例:
Resource resource = new FileSystemResource("resources/trades.csv");
在复杂的批处理环境中,目录结构通常由 EAI 基础结构 Management,在 EAI 基础结构中,构建了用于外部接口的放置区,以将文件从 ftp 位置移动到批处理位置,反之亦然。文件移动 Util 超出了 Spring 批处理体系结构的范围,但是批处理作业流中包含文件移动 Util 作为作业流中的步骤并不少见。批处理体系结构只需要知道如何找到要处理的文件就足够了。 Spring Batch 从此起点开始将数据馈入管道的过程。但是,Spring Integration提供了许多此类服务。
FlatFileItemReader中的其他属性使您可以进一步指定如何解释数据:
表 6.1. FlatFileItemReader 属性
| Property | Type | Description |
|---|---|---|
| comments | String[] | 指定指示 Comments 行的行前缀 |
| encoding | String | 指定要使用的文本编码-默认为“ ISO-8859-1” |
| lineMapper | LineMapper | 将表示 Item 的String转换为Object。 |
| linesToSkip | int | 文件顶部要忽略的行数 |
| recordSeparatorPolicy | RecordSeparatorPolicy | 用于确定行尾的位置,并执行诸如在带引号的字符串中 continue 到行尾的操作。 |
| resource | Resource | 从中读取资源。 |
| skippedLinesCallback | LineCallbackHandler | 该接口传递要跳过的文件中各行的原始行内容。如果 linesToSkip 设置为 2,则此接口将被调用两次。 |
| strict | boolean | 在严格模式下,如果 Importing 资源不存在,则读取器将在 ExecutionContext 上引发异常。 |
LineMapper
与RowMapper一样,它采用诸如ResultSet之类的低级构造并返回Object,平面文件处理需要相同的构造才能将String行转换为Object:
public interface LineMapper<T> {
T mapLine(String line, int lineNumber) throws Exception;
}
基本约定是,给定当前行及其关联的行号,Map 器应返回结果域对象。这与RowMapper相似,因为每一行都与其行号相关联,就像ResultSet中的每一行都与其行号相关联一样。这允许将行号绑定到结果域对象,以进行身份比较或提供更多信息。但是,与RowMapper不同,LineMapper被赋予了原始行,如上所述,该原始行只会使您到达中间。该行必须标记为FieldSet,然后可以将其 Map 到对象,如下所述。
LineTokenizer
必须将 Importing 行转换为行FieldSet的抽象,因为可能需要将许多格式的平面文件数据转换为FieldSet。在 Spring Batch 中,此接口是LineTokenizer:
public interface LineTokenizer {
FieldSet tokenize(String line);
}
LineTokenizer的约定使得在给定 Importing 行的情况下(理论上String可以包含多行),将返回代表该行的FieldSet。然后可以将此FieldSet传递给FieldSetMapper。 Spring Batch 包含以下LineTokenizer实现:
DelmitedLineTokenizer-用于 Logging 的字段由定界符分隔的文件。最常见的定界符是逗号,但是也经常使用竖线或分号。FixedLengthTokenizer-用于 Logging 字段均为“固定宽度”的文件。必须为每种记录类型定义每个字段的宽度。PatternMatchingCompositeLineTokenizer-通过检查模式,确定应在特定行上使用LineTokenizers 列表中的哪一个。
FieldSetMapper
FieldSetMapper接口定义单个方法mapFieldSet,该方法采用FieldSet对象并将其内容 Map 到对象。根据作业的需要,此对象可以是自定义 DTO,域对象或简单数组。 FieldSetMapper与LineTokenizer结合使用可将一行数据从资源转换为所需类型的对象:
public interface FieldSetMapper<T> {
T mapFieldSet(FieldSet fieldSet);
}
使用的模式与JdbcTemplate使用的RowMapper相同。
DefaultLineMapper
既然已经定义了读取平面文件的基本接口,那么很明显,需要三个基本步骤:
- 从文件中读取一行。
- 将字符串行传递到
LineTokenizer#tokenize()方法中,以便检索FieldSet。 - 将标记化返回的
FieldSet传递给FieldSetMapper,并从ItemReader#read()方法返回结果。
上面描述的两个接口代表两个单独的任务:将线转换为FieldSet,并将FieldSetMap 到域对象。因为LineTokenizer的 Importing 与LineMapper的 Importing(一行)匹配,并且FieldSetMapper的输出与LineMapper的输出匹配,所以提供了同时使用LineTokenizer和FieldSetMapper的默认实现。 DefaultLineMapper代表大多数用户将需要的行为:
public class DefaultLineMapper<T> implements LineMapper<T>, InitializingBean {
private LineTokenizer tokenizer;
private FieldSetMapper<T> fieldSetMapper;
public T mapLine(String line, int lineNumber) throws Exception {
return fieldSetMapper.mapFieldSet(tokenizer.tokenize(line));
}
public void setLineTokenizer(LineTokenizer tokenizer) {
this.tokenizer = tokenizer;
}
public void setFieldSetMapper(FieldSetMapper<T> fieldSetMapper) {
this.fieldSetMapper = fieldSetMapper;
}
}
以上功能是默认实现中提供的,而不是内置于 Reader 本身中(如在框架的先前版本中所做的那样),以便允许用户在控制解析过程时具有更大的灵 Active,尤其是在访问原始行的情况下。需要。
简单分隔文件读取示例
以下示例将用于使用实际域方案进行说明。这个特定的批处理作业从以下文件中读取足球运动员:
ID,lastName,firstName,position,birthYear,debutYear
"AbduKa00,Abdul-Jabbar,Karim,rb,1974,1996",
"AbduRa00,Abdullah,Rabih,rb,1975,1999",
"AberWa00,Abercrombie,Walter,rb,1959,1982",
"AbraDa00,Abramowicz,Danny,wr,1945,1967",
"AdamBo00,Adams,Bob,te,1946,1969",
"AdamCh00,Adams,Charlie,wr,1979,2003"
该文件的内容将 Map 到以下Player域对象:
public class Player implements Serializable {
private String ID;
private String lastName;
private String firstName;
private String position;
private int birthYear;
private int debutYear;
public String toString() {
return "PLAYER:ID=" + ID + ",Last Name=" + lastName +
",First Name=" + firstName + ",Position=" + position +
",Birth Year=" + birthYear + ",DebutYear=" +
debutYear;
}
// setters and getters...
}
为了将FieldSetMap 到Player对象,需要定义返回玩家的FieldSetMapper:
protected static class PlayerFieldSetMapper implements FieldSetMapper<Player> {
public Player mapFieldSet(FieldSet fieldSet) {
Player player = new Player();
player.setID(fieldSet.readString(0));
player.setLastName(fieldSet.readString(1));
player.setFirstName(fieldSet.readString(2));
player.setPosition(fieldSet.readString(3));
player.setBirthYear(fieldSet.readInt(4));
player.setDebutYear(fieldSet.readInt(5));
return player;
}
}
然后可以通过正确构造FlatFileItemReader并调用read来读取文件:
FlatFileItemReader<Player> itemReader = new FlatFileItemReader<Player>();
itemReader.setResource(new FileSystemResource("resources/players.csv"));
//DelimitedLineTokenizer defaults to comma as its delimiter
DefaultLineMapper<Player> lineMapper = new DefaultLineMapper<Player>();
lineMapper.setLineTokenizer(new DelimitedLineTokenizer());
lineMapper.setFieldSetMapper(new PlayerFieldSetMapper());
itemReader.setLineMapper(lineMapper);
itemReader.open(new ExecutionContext());
Player player = itemReader.read();
每次对read的调用都会从文件的每一行返回一个新的 Player 对象。到达文件末尾时,将返回 null。
按名称 Map 字段
DelimitedLineTokenizer和FixedLengthTokenizer允许另外一项功能,其功能类似于 Jdbc ResultSet。字段的名称可以被注入到这些LineTokenizer实现中,以提高 Map 函数的可读性。首先,将平面文件中所有字段的列名注入令牌生成器中:
tokenizer.setNames(new String[] {"ID", "lastName","firstName","position","birthYear","debutYear"});
FieldSetMapper可以使用以下信息:
public class PlayerMapper implements FieldSetMapper<Player> {
public Player mapFieldSet(FieldSet fs) {
if(fs == null){
return null;
}
Player player = new Player();
player.setID(fs.readString("ID"));
player.setLastName(fs.readString("lastName"));
player.setFirstName(fs.readString("firstName"));
player.setPosition(fs.readString("position"));
player.setDebutYear(fs.readInt("debutYear"));
player.setBirthYear(fs.readInt("birthYear"));
return player;
}
}
将字段集自动 Map 到域对象
对于许多人来说,必须编写特定的FieldSetMapper与为JdbcTemplate编写特定的RowMapper一样麻烦。 Spring Batch 通过提供FieldSetMapper来简化此过程,该FieldSetMapper通过使用 JavaBean 规范将字段名称与对象上的设置器进行匹配来自动 Map 字段。再次使用足球示例,BeanWrapperFieldSetMapper配置如下所示:
<bean id="fieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper">
<property name="prototypeBeanName" value="player" />
</bean>
<bean id="player"
class="org.springframework.batch.sample.domain.Player"
scope="prototype" />
对于FieldSet中的每个条目,Map 器将在Player对象的新实例上查找对应的 setter(因此,需要原型作用域),方式与 Spring 容器将查找与属性名称匹配的 setter 相同。 FieldSet中的每个可用字段都将被 Map,并且将返回结果Player对象,而无需代码。
定长文件格式
到目前为止,仅详细讨论了定界文件,但是,它们仅占文件读取图片的一半。许多使用平面文件的组织都使用固定长度格式。固定长度文件示例如下:
UK21341EAH4121131.11customer1
UK21341EAH4221232.11customer2
UK21341EAH4321333.11customer3
UK21341EAH4421434.11customer4
UK21341EAH4521535.11customer5
虽然这 Watch 起来像一个大字段,但实际上代表了 4 个不同的字段:
- ISIN:要 Order 的商品的唯一标识符-12 个字符长。
- 数量:已 Order 的 Item 数-3 个字符长。
- 价格:商品价格-5 个字符长。
- Client:Order 商品的 ClientID-9 个字符长。
配置FixedLengthLineTokenizer时,必须以范围的形式提供以下每种长度:
<bean id="fixedLengthLineTokenizer"
class="org.springframework.batch.io.file.transform.FixedLengthTokenizer">
<property name="names" value="ISIN,Quantity,Price,Customer" />
<property name="columns" value="1-12, 13-15, 16-20, 21-29" />
</bean>
因为FixedLengthLineTokenizer使用与上述相同的LineTokenizer接口,所以它将返回相同的FieldSet,就好像使用了分隔符一样。这允许在处理其输出时使用相同的方法,例如使用BeanWrapperFieldSetMapper。
Note
要支持上述范围语法,需要在ApplicationContext中配置专门的属性编辑器RangeArrayPropertyEditor。但是,此 Bean 是在使用批处理名称空间的ApplicationContext中自动声明的。
单个文件中的多种记录类型
到目前为止,为简单起见,所有文件读取示例都作了一个关键假设:文件中的所有记录都具有相同的格式。但是,并非总是如此。通常,文件中的记录可能具有不同的格式,需要对其进行不同的标记和 Map 到不同的对象。以下文件摘录对此进行了说明:
USER;Smith;Peter;;T;20014539;F
LINEA;1044391041ABC037.49G201XX1383.12H
LINEB;2134776319DEF422.99M005LI
在此文件中,我们有三种类型的记录:“ USER”,“ LINEA”和“ LINEB”。 “ USER”行对应于一个 User 对象。尽管“ LINEA”比“ LINEB”具有更多信息,但“ LINEA”和“ LINEB”都对应于 Line 对象。
ItemReader将分别读取每一行,但是我们必须指定不同的LineTokenizer和FieldSetMapper对象,以便ItemWriter将接收正确的 Item。 PatternMatchingCompositeLineMapper通过允许配置模式到LineTokenizer的 Map 以及模式到FieldSetMapper的 Map,使此操作变得容易:
<bean id="orderFileLineMapper"
class="org.spr...PatternMatchingCompositeLineMapper">
<property name="tokenizers">
<map>
<entry key="USER*" value-ref="userTokenizer" />
<entry key="LINEA*" value-ref="lineATokenizer" />
<entry key="LINEB*" value-ref="lineBTokenizer" />
</map>
</property>
<property name="fieldSetMappers">
<map>
<entry key="USER*" value-ref="userFieldSetMapper" />
<entry key="LINE*" value-ref="lineFieldSetMapper" />
</map>
</property>
</bean>
在此示例中,“ LINEA”和“ LINEB”具有单独的LineTokenizer,但它们都使用相同的FieldSetMapper。
PatternMatchingCompositeLineMapper使用PatternMatcher的match方法来为每行选择正确的委托。 PatternMatcher允许使用两个具有特殊含义的通配符:问号(“?”)恰好匹配一个字符,而星号(“ *”)则匹配零个或多个字符。请注意,在上述配置中,所有模式都以星号结尾,从而使它们有效地成为行的前缀。 PatternMatcher将始终匹配最可能的特定模式,而不考虑配置中的 Sequences。因此,如果“ LINE *”和“ LINEA *”都被列为模式,则“ LINEA”将与模式“ LINEA *”匹配,而“ LINEB”将与模式“ LINE *”匹配。另外,单个星号(“ *”)可以通过匹配未与任何其他模式匹配的任何行作为默认值。
<entry key="*" value-ref="defaultLineTokenizer" />
还有一个PatternMatchingCompositeLineTokenizer可以单独用于令牌化。
平面文件包含每个跨越多行的记录也是很常见的。为了处理这种情况,需要更复杂的策略。 第 11.5 节“多行记录”中提供了这种常见模式的演示。
平面文件中的异常处理
在很多情况下,对行进行标记可能会引发异常。许多平面文件并不完美,并且包含格式不正确的记录。许多用户选择跳过这些错误的行,注销问题,原始行和行号。以后可以手动或通过其他批处理作业检查这些日志。因此,Spring Batch 提供了一个用于处理解析异常的异常层次结构:FlatFileParseException和FlatFileFormatException。尝试读取文件时遇到任何错误,FlatFileItemReader会引发FlatFileParseException。 LineTokenizer接口的实现抛出FlatFileFormatException,并指示在标记化时遇到的更具体的错误。
IncorrectTokenCountException
DelimitedLineTokenizer和FixedLengthLineTokenizer都可以指定可用于创建FieldSet的列名。但是,如果列名的数量与对行进行标记时找到的列数不匹配,则无法创建FieldSet,并抛出IncorrectTokenCountException,其中包含遇到的令牌数和预期的数目:
tokenizer.setNames(new String[] {"A", "B", "C", "D"});
try {
tokenizer.tokenize("a,b,c");
}
catch(IncorrectTokenCountException e){
assertEquals(4, e.getExpectedCount());
assertEquals(3, e.getActualCount());
}
因为令牌化器配置了 4 个列名,但是在文件中仅找到 3 个令牌,所以抛出了IncorrectTokenCountException。
IncorrectLineLengthException
解析为固定长度格式的文件在解析时还有其他要求,因为与分隔格式不同,每一列必须严格遵守其 sched 义宽度。如果总行长不等于该列的最宽值,则抛出异常:
tokenizer.setColumns(new Range[] { new Range(1, 5),
new Range(6, 10),
new Range(11, 15) });
try {
tokenizer.tokenize("12345");
fail("Expected IncorrectLineLengthException");
}
catch (IncorrectLineLengthException ex) {
assertEquals(15, ex.getExpectedLength());
assertEquals(5, ex.getActualLength());
}
上面标记器的配置范围是:1-5、6-10 和 11-15,因此预期行的总长度为 15.但是,在这种情况下,传入了长度为 5 的行,从而导致IncorrectLineLengthException被抛出。在这里抛出异常而不是仅 Map 第一列,可以使行的处理更早地失败,并且比试图在FieldSetMapper的第 2 列中读取失败的情况提供更多的信息。但是,在某些情况下,线的长度并不总是恒定的。因此,可以通过“ strict”属性关闭行长的验证:
tokenizer.setColumns(new Range[] { new Range(1, 5), new Range(6, 10) });
tokenizer.setStrict(false);
FieldSet tokens = tokenizer.tokenize("12345");
assertEquals("12345", tokens.readString(0));
assertEquals("", tokens.readString(1));
上面的示例几乎与之前的示例相同,只是调用了 tokenizer.setStrict(false)。此设置告诉令牌化程序在对行进行令牌化时不要强制行长。现在已正确创建并返回FieldSet。但是,它将仅包含剩余值的空令牌。
6.6.3 FlatFileItemWriter
写入平面文件具有相同的问题和必须从文件中读取的问题。步骤必须能够以事务方式以定界或定长格式写出。
LineAggregator
就像需要LineTokenizer接口来获取一项并将其变成String一样,文件写入必须具有一种将多个字段聚合到单个字符串中以写入文件的方法。在 Spring Batch 中,这是LineAggregator:
public interface LineAggregator<T> {
public String aggregate(T item);
}
LineAggregator与LineTokenizer相反。 LineTokenizer取String并返回FieldSet,而LineAggregator取item并返回String。
PassThroughLineAggregator
LineAggregator 接口的最基本实现是PassThroughLineAggregator,它简单地假定对象已经是一个字符串,或者它的字符串表示形式可以用于编写:
public class PassThroughLineAggregator<T> implements LineAggregator<T> {
public String aggregate(T item) {
return item.toString();
}
}
如果需要直接控制创建字符串,但是上面的实现很有用,但是FlatFileItemWriter的优点(例如事务和重新启动支持)是必需的。
简化文件编写示例
既然已经定义了LineAggregator接口及其最基本的实现PassThroughLineAggregator,那么可以说明基本的编写流程:
- 要写入的对象被传递到
LineAggregator以获得String。 - 返回的
String将被写入配置的文件。
FlatFileItemWriter的以下摘录用代码表示:
public void write(T item) throws Exception {
write(lineAggregator.aggregate(item) + LINE_SEPARATOR);
}
一个简单的配置如下所示:
<bean id="itemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" value="file:target/test-outputs/output.txt" />
<property name="lineAggregator">
<bean class="org.spr...PassThroughLineAggregator"/>
</property>
</bean>
FieldExtractor
上面的示例对于写入文件的最基本用途可能很有用。但是,FlatFileItemWriter的大多数用户将具有需要写出的域对象,因此必须将其转换为一行。在读取文件时,需要满足以下条件:
- 从文件中读取一行。
- 将字符串行传递到
LineTokenizer#tokenize()方法中,以便检索FieldSet - 将令牌化返回的
FieldSet传递给FieldSetMapper,并从ItemReader#read()方法返回结果
文件写入具有相似但相反的步骤:
- 将要写入的 Item 传递给 Writer
- 将 Item 上的字段转换为数组
- 将结果数组聚合为一行
因为框架没有办法知道对象中哪些字段需要写出,所以必须写一个FieldExtractor来完成将 Item 变成数组的任务:
public interface FieldExtractor<T> {
Object[] extract(T item);
}
FieldExtractor接口的实现应从提供的对象的字段中创建一个数组,然后可以使用元素之间的分隔符将其写出,也可以将其写为字段宽度线的一部分。
PassThroughFieldExtractor
在许多情况下,需要写出集合,例如数组Collection或FieldSet。从这些集合类型之一中“提取”数组非常简单:只需将集合转换为数组即可。因此,在这种情况下应使用PassThroughFieldExtractor。应当注意,如果传入的对象不是集合类型,则PassThroughFieldExtractor将返回仅包含要提取的 Item 的数组。
BeanWrapperFieldExtractor
与在文件读取部分中介绍的BeanWrapperFieldSetMapper一样,通常最好配置如何将域对象转换为对象数组,而不是自己编写转换。 BeanWrapperFieldExtractor仅提供这种类型的功能:
BeanWrapperFieldExtractor<Name> extractor = new BeanWrapperFieldExtractor<Name>();
extractor.setNames(new String[] { "first", "last", "born" });
String first = "Alan";
String last = "Turing";
int born = 1912;
Name n = new Name(first, last, born);
Object[] values = extractor.extract(n);
assertEquals(first, values[0]);
assertEquals(last, values[1]);
assertEquals(born, values[2]);
此提取器实现只有一个必需的属性,即要 Map 的字段名称。就像BeanWrapperFieldSetMapper需要字段名称将FieldSet上的字段 Map 到所提供对象上的 setter 一样,BeanWrapperFieldExtractor也需要名称 Map 到 getter 来创建对象数组。值得注意的是,名称的 Sequences 决定了数组中字段的 Sequences。
分隔文件写入示例
最基本的平面文件格式是其中所有字段都由定界符分隔的格式。这可以使用DelimitedLineAggregator完成。下面的示例写出一个简单的域对象,该对象代表 Client 帐户的贷方:
public class CustomerCredit {
private int id;
private String name;
private BigDecimal credit;
//getters and setters removed for clarity
}
由于正在使用域对象,因此必须提供 FieldExtractor 接口的实现以及要使用的定界符:
<bean id="itemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator">
<bean class="org.spr...DelimitedLineAggregator">
<property name="delimiter" value=","/>
<property name="fieldExtractor">
<bean class="org.spr...BeanWrapperFieldExtractor">
<property name="names" value="name,credit"/>
</bean>
</property>
</bean>
</property>
</bean>
在这种情况下,本章前面介绍的BeanWrapperFieldExtractor用于将CustomerCredit中的名称和贷方字段转换为对象数组,然后将其写成每个字段之间的逗号。
定宽文件写入示例
分隔不是平面文件格式的唯一类型。许多人更喜欢为每个列使用固定宽度来在字段之间划定轮廓,这通常称为“固定宽度”。 Spring Batch 通过FormatterLineAggregator在文件写入中支持此功能。使用上述相同的CustomerCredit域对象,可以将其配置如下:
<bean id="itemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator">
<bean class="org.spr...FormatterLineAggregator">
<property name="fieldExtractor">
<bean class="org.spr...BeanWrapperFieldExtractor">
<property name="names" value="name,credit" />
</bean>
</property>
<property name="format" value="%-9s%-2.0f" />
</bean>
</property>
</bean>
上面的大多数示例应该 Watch 起来很熟悉。但是,format 属性的值是新的:
<property name="format" value="%-9s%-2.0f" />
使用与 Java 5 相同的Formatter构建底层实现。Java Formatter基于 C 编程语言的printf功能。有关如何配置格式化程序的大多数详细信息,请参见Formatter的 javadoc。
处理文件创建
FlatFileItemReader与文件资源的关系非常简单。初始化 Reader 后,它将打开文件(如果存在),并引发异常(如果没有)。文件写入并不是那么简单。乍一 Watch,似乎对于FlatFileItemWriter应该存在类似的直接约定:如果文件已经存在,则引发异常;如果不存在,则创建它并开始写入。但是,潜在地重新启动Job可能会导致问题。在正常的重新启动方案中,Contract 是相反的:如果文件存在,则从最后一个已知的好的位置开始对其进行写入,如果不存在,则引发异常。但是,如果此作业的文件名始终相同会怎样?在这种情况下,您希望删除该文件(如果存在),除非重新启动。由于这种可能性,FlatFileItemWriter包含属性shouldDeleteIfExists。将此属性设置为 true 将导致在打开编写器时删除具有相同名称的现有文件。
6.7 XMLItem 读取器和写入器
Spring Batch 提供了用于读取 XML 记录并将它们 Map 到 Java 对象以及将 Java 对象编写为 XML 记录的事务性基础结构。
Note
StAX API 用于 I/O,因为其他标准 XML 解析 API 不符合批处理要求(DOM 将整个 Importing 立即加载到内存中,而 SAX 控制解析过程,仅允许用户提供回调)。
让我们仔细 WatchWatchSpring Batch 中 XMLImporting 和输出的工作方式。首先,有一些概念与文件读写不同,但在 Spring Batch XML 处理中很常见。通过 XML 处理,而不是需要标记的记录行(FieldSets),假定 XML 资源是与各个记录相对应的“片段”的集合:
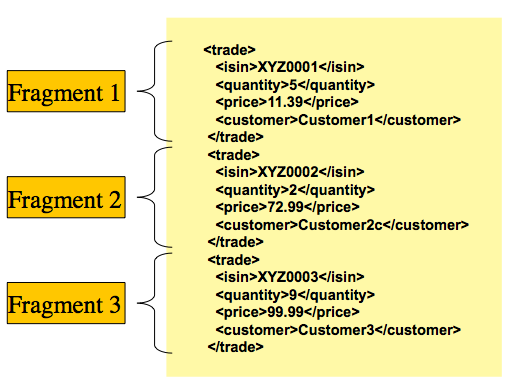
图 3.1:XMLImporting
在上述方案中,“贸易”标签被定义为“根元素”。 ‘ ‘和’ ‘之间的所有内容均被视为一个“片段”。 Spring Batch 使用对象/ XMLMap(OXM)将片段绑定到对象。但是,Spring Batch 不与任何特定的 XML 绑定技术绑定。典型的用法是委托Spring OXM,它为最流行的 OXM 技术提供统一的抽象。对 Spring OXM 的依赖关系是可选的,如果需要,您可以选择实现特定于 Spring Batch 的接口。与 OXM 支持的技术的关系可以显示如下:
图 3.2:OXM 绑定
现在,对 OXM 进行了介绍,并介绍了如何使用 XML 片段来表示记录,下面让我们仔细 WatchWatchReader。
6.7.1 StaxEventItemReader
StaxEventItemReader配置提供了用于处理 XMLImporting 流中的记录的典型设置。首先,让我们检查StaxEventItemReader可以处理的一组 XML 记录。
<?xml version="1.0" encoding="UTF-8"?>
<records>
<trade xmlns="http://springframework.org/batch/sample/io/oxm/domain">
<isin>XYZ0001</isin>
<quantity>5</quantity>
<price>11.39</price>
<customer>Customer1</customer>
</trade>
<trade xmlns="http://springframework.org/batch/sample/io/oxm/domain">
<isin>XYZ0002</isin>
<quantity>2</quantity>
<price>72.99</price>
<customer>Customer2c</customer>
</trade>
<trade xmlns="http://springframework.org/batch/sample/io/oxm/domain">
<isin>XYZ0003</isin>
<quantity>9</quantity>
<price>99.99</price>
<customer>Customer3</customer>
</trade>
</records>
为了能够处理 XML 记录,需要执行以下操作:
- 根元素名称-组成要 Map 对象的片段的根元素的名称。示例配置通过贸易价值展示了这一点。
- 资源-表示要读取的文件的 Spring 资源。
Unmarshaller-Spring OXM 提供的解组工具,用于将 XML 片段 Map 到对象。<bean id="itemReader" class="org.springframework.batch.item.xml.StaxEventItemReader"> <property name="fragmentRootElementName" value="trade" /> <property name="resource" value="data/iosample/input/input.xml" /> <property name="unmarshaller" ref="tradeMarshaller" /> </bean>
注意,在此示例中,我们选择使用XStreamMarshaller来接受作为 Map 传入的别名,其中第一个键和值是片段的名称(即根元素)以及要绑定的对象类型。然后,类似于FieldSet,Map 到对象类型内字段的其他元素的名称在 Map 中描述为键/值对。在配置文件中,我们可以使用 Spring 配置 Util 来描述所需的别名,如下所示:
<bean id="tradeMarshaller"
class="org.springframework.oxm.xstream.XStreamMarshaller">
<property name="aliases">
<util:map id="aliases">
<entry key="trade"
value="org.springframework.batch.sample.domain.Trade" />
<entry key="price" value="java.math.BigDecimal" />
<entry key="name" value="java.lang.String" />
</util:map>
</property>
</bean>
Importing 时,Reader 将读取 XML 资源,直到它识别出一个新的片段即将开始(默认情况下通过匹配标记名称)。读取器从该片段创建一个独立的 XML 文档(或至少使它 Watch 起来如此),然后将该文档传递给解串器(通常是 Spring OXM Unmarshaller的包装器),以将 XMLMap 到 Java 对象。
总之,此过程类似于以下脚本 Java 代码,该代码使用 Spring 配置提供的注入:
StaxEventItemReader xmlStaxEventItemReader = new StaxEventItemReader()
Resource resource = new ByteArrayResource(xmlResource.getBytes())
Map aliases = new HashMap();
aliases.put("trade","org.springframework.batch.sample.domain.Trade");
aliases.put("price","java.math.BigDecimal");
aliases.put("customer","java.lang.String");
XStreamMarshaller unmarshaller = new XStreamMarshaller();
unmarshaller.setAliases(aliases);
xmlStaxEventItemReader.setUnmarshaller(unmarshaller);
xmlStaxEventItemReader.setResource(resource);
xmlStaxEventItemReader.setFragmentRootElementName("trade");
xmlStaxEventItemReader.open(new ExecutionContext());
boolean hasNext = true
CustomerCredit credit = null;
while (hasNext) {
credit = xmlStaxEventItemReader.read();
if (credit == null) {
hasNext = false;
}
else {
System.out.println(credit);
}
}
6.7.2 StaxEventItemWriter
输出与 Importing 对称地工作。 StaxEventItemWriter需要Resource,编组和rootTagName。将 Java 对象传递到编组器(通常是标准 Spring OXM Marshaller),编组器使用自定义事件编写器写入Resource,该事件编写器过滤 OXM 工具为每个片段生成的StartDocument和EndDocument事件。我们将在使用MarshallingEventWriterSerializer的示例中对此进行展示。此设置的 Spring 配置如下所示:
<bean id="itemWriter" class="org.springframework.batch.item.xml.StaxEventItemWriter">
<property name="resource" ref="outputResource" />
<property name="marshaller" ref="customerCreditMarshaller" />
<property name="rootTagName" value="customers" />
<property name="overwriteOutput" value="true" />
</bean>
该配置设置了三个必需的属性,还可以选择设置 overwriteOutput = true,这在本章前面提到的用于指定是否可以覆盖现有文件。应当注意,用于编写程序的编组器与本章前面的阅读示例中使用的编组器完全相同:
<bean id="customerCreditMarshaller"
class="org.springframework.oxm.xstream.XStreamMarshaller">
<property name="aliases">
<util:map id="aliases">
<entry key="customer"
value="org.springframework.batch.sample.domain.CustomerCredit" />
<entry key="credit" value="java.math.BigDecimal" />
<entry key="name" value="java.lang.String" />
</util:map>
</property>
</bean>
总结一下 Java 示例,以下代码说明了所有讨论的要点,展示了所需属性的编程设置:
StaxEventItemWriter staxItemWriter = new StaxEventItemWriter()
FileSystemResource resource = new FileSystemResource("data/outputFile.xml")
Map aliases = new HashMap();
aliases.put("customer","org.springframework.batch.sample.domain.CustomerCredit");
aliases.put("credit","java.math.BigDecimal");
aliases.put("name","java.lang.String");
Marshaller marshaller = new XStreamMarshaller();
marshaller.setAliases(aliases);
staxItemWriter.setResource(resource);
staxItemWriter.setMarshaller(marshaller);
staxItemWriter.setRootTagName("trades");
staxItemWriter.setOverwriteOutput(true);
ExecutionContext executionContext = new ExecutionContext();
staxItemWriter.open(executionContext);
CustomerCredit Credit = new CustomerCredit();
trade.setPrice(11.39);
credit.setName("Customer1");
staxItemWriter.write(trade);
6.8 多文件 Importing
通常在单个Step中处理多个文件。假设文件格式相同,则MultiResourceItemReader支持 XML 和平面文件处理的这种类型的 Importing。考虑目录中的以下文件:
file-1.txt file-2.txt ignored.txt
file-1.txt 和 file-2.txt 的格式相同,出于商业原因,应一起处理。可以使用通配符使用MuliResourceItemReader读取两个文件:
<bean id="multiResourceReader" class="org.spr...MultiResourceItemReader">
<property name="resources" value="classpath:data/input/file-*.txt" />
<property name="delegate" ref="flatFileItemReader" />
</bean>
引用的委托是简单的FlatFileItemReader。上面的配置将从两个文件中读取 Importing,以处理回滚和重新启动场景。应当注意,与任何ItemReader一样,添加额外的 Importing(在这种情况下为文件)可能会在重新启动时引起潜在的问题。建议批处理作业使用其各自的目录,直到成功完成为止。
6.9 Database
像大多数企业应用程序样式一样,数据库是批处理的中央存储机制。但是,批处理与其他应用程序样式不同,这是由于系统必须使用的数据集的绝对大小。如果 SQL 语句返回 100 万行,则结果集可能将所有返回的结果保存在内存中,直到读取了所有行。 Spring Batch 针对此问题提供了两种类型的解决方案:游标和分页数据库 ItemReaders。
6.9.1 基于游标的 ItemReader
通常,使用数据库游标是大多数批处理开发人员的默认方法,因为它是数据库解决“流式”关系数据问题的方法。 Java ResultSet类本质上是用于操纵游标的面向对象的机制。 ResultSet将光标保留到当前数据行。在ResultSet上调用next会将光标移到下一行。基于 Spring Batch 游标的 ItemReaders 在初始化时打开游标,并针对每次对read的调用将游标向前移动一行,从而返回可用于处理的 Map 对象。然后将调用close方法以确保释放所有资源。 Spring 核心JdbcTemplate通过使用回调模式完全 MapResultSet中的所有行并在将控制权返回给方法调用者之前关闭来解决此问题。但是,必须分批完成,直到步骤完成。下面是基于游标的ItemReader的工作原理的一般示意图,虽然以 SQL 语句为例,因为它广为人知,但是任何技术都可以实现基本方法:
本示例说明了基本模式。给定一个’FOO’表,该表具有三列:ID,NAME 和 BAR,选择 ID 大于 1 但小于 7 的所有行。这会将光标的开始(行 1)放在 ID 2 上。结果该行的内容应该是完全 Map 的 Foo 对象。再次调用read()将光标移动到下一行,即 ID 为 3 的 Foo。这些读取的结果将在每个read之后写出,从而允许对对象进行垃圾回收(假设没有实例变量是维护对它们的引用)。
JdbcCursorItemReader
JdbcCursorItemReader是基于游标的技术的 Jdbc 实现。它直接与ResultSet一起使用,并且需要 SQL 语句针对从DataSource获得的连接运行。以下数据库模式将用作示例:
CREATE TABLE CUSTOMER (
ID BIGINT IDENTITY PRIMARY KEY,
NAME VARCHAR(45),
CREDIT FLOAT
);
许多人喜欢为每一行使用一个域对象,因此我们将使用RowMapper接口的实现来 MapCustomerCredit对象:
public class CustomerCreditRowMapper implements RowMapper {
public static final String ID_COLUMN = "id";
public static final String NAME_COLUMN = "name";
public static final String CREDIT_COLUMN = "credit";
public Object mapRow(ResultSet rs, int rowNum) throws SQLException {
CustomerCredit customerCredit = new CustomerCredit();
customerCredit.setId(rs.getInt(ID_COLUMN));
customerCredit.setName(rs.getString(NAME_COLUMN));
customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN));
return customerCredit;
}
}
由于JdbcTemplate对 Spring 的用户非常熟悉,并且JdbcCursorItemReader与它共享关键接口,因此有一个示例如何使用JdbcTemplate读取此数据以与ItemReader进行对比很有用。就本示例而言,我们假设 CUSTOMER 数据库中有 1,000 行。第一个示例将使用JdbcTemplate:
//For simplicity sake, assume a dataSource has already been obtained
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER",
new CustomerCreditRowMapper());
运行此代码段后,customerCredits 列表将包含 1,000 个CustomerCredit对象。在查询方法中,将从DataSource获得连接,将针对该DataSource运行所提供的 SQL,并对ResultSet中的每一行调用mapRow方法。让我们将此与JdbcCursorItemReader的方法进行对比:
JdbcCursorItemReader itemReader = new JdbcCursorItemReader();
itemReader.setDataSource(dataSource);
itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER");
itemReader.setRowMapper(new CustomerCreditRowMapper());
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close(executionContext);
运行此代码段后,计数器将等于 1,000.如果上面的代码已将返回的 customerCredit 放入列表中,则结果将与JdbcTemplate示例完全相同。但是,ItemReader的最大优点是它允许“流式传输”Item。可以一次调用read方法,然后通过ItemWriter写出该 Item,然后通过read获得下一个 Item。这样就可以在“块”中进行 Item 读取和写入,并定期进行,这是高性能批处理的本质。此外,它很容易配置为注入到 Spring Batch Step中:
<bean id="itemReader" class="org.spr...JdbcCursorItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="sql" value="select ID, NAME, CREDIT from CUSTOMER"/>
<property name="rowMapper">
<bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/>
</property>
</bean>
Additional Properties
由于在 Java 中打开光标有多种选择,因此JdbcCustorItemReader上可以设置许多属性:
表 6.2. JdbcCursorItemReader 属性
| ignoreWarnings | 确定是否记录 SQLWarning 或导致异常-默认为 true |
|---|---|
| fetchSize | 当ItemReader所使用的ResultSet对象需要更多行时,向 Jdbc 驱动程序提示有关应从数据库中获取的行数。默认情况下,不给出任何提示。 |
| maxRows | 设置基础ResultSet一次可以容纳的最大行数限制。 |
| queryTimeout | 将驱动程序 awaitStatement对象执行的秒数设置为给定的秒数。如果超出限制,则抛出DataAccessEception。 (有关详细信息,请咨询您的驱动程序供应商文档)。 |
| verifyCursorPosition | 由于ItemReader持有的ResultSet被传递给RowMapper,因此用户可以自己调用ResultSet.next(),这可能会导致读取器的内部计数出现问题。如果将RowMapper调用之后的光标位置与之前的位置不同,则将此值设置为 true 将引发异常。 |
| saveState | 指示是否将读取器的状态保存在ItemStream#update(ExecutionContext)提供的ExecutionContext中。默认值为 true。 |
| driverSupportsAbsolute | 默认为 false。指示 Jdbc 驱动程序是否支持在ResultSet上设置绝对行。对于支持ResultSet.absolute()的 Jdbc 驱动程序,建议将其设置为 true,因为它可以提高性能,特别是如果在处理大型数据集时某个步骤失败时。 |
| setUseSharedExtendedConnection | 默认为 false。指示用于游标的连接是否应由所有其他处理使用,从而共享同一事务。如果将其设置为 false(这是默认值),则游标将使用其自己的连接打开,并且将不参与在其余步骤处理中启动的任何事务。如果将此标志设置为 true,则必须将DataSource包裹在ExtendedConnectionDataSourceProxy中,以防止每次提交后关闭和释放连接。当将此选项设置为 true 时,将同时使用’READ_ONLY’和’HOLD_CUSORS_OVER_COMMIT’选项创建用于打开游标的语句。这样就可以使游标在事务开始时保持打开状态,并在步骤处理中执行提交。要使用此功能,您需要一个支持此功能的数据库以及一个支持 Jdbc 3.0 或更高版本的 Jdbc 驱动程序。 |
HibernateCursorItemReader
就像普通的 Spring 用户在决定是否使用 ORM 解决方案(这会影响他们使用JdbcTemplate还是HibernateTemplate)上做出重要决定一样,Spring Batch 用户也具有相同的选择。 HibernateCursorItemReader是光标技术的 Hibernate 实现。 Hibernate 的批量使用方式一直存在争议。这主要是因为 Hibernate 最初是为支持在线应用程序样式而开发的。但是,这并不意味着它不能用于批处理。解决此问题的最简单方法是使用StatelessSession而不是标准会话。这消除了休眠使用的所有缓存和脏检查,这些检查可能会在批处理方案中引起问题。有关 Stateless 和正常休眠会话之间差异的更多信息,请参阅特定休眠版本的文档。 HibernateCursorItemReader允许您声明 HQL 语句并传递SessionFactory,这将以与JdbcCursorItemReader相同的基本方式将每次调用将一项返回给read。以下是使用与 JDBCReader 相同的“Client 信用”示例的示例配置:
HibernateCursorItemReader itemReader = new HibernateCursorItemReader();
itemReader.setQueryString("from CustomerCredit");
//For simplicity sake, assume sessionFactory already obtained.
itemReader.setSessionFactory(sessionFactory);
itemReader.setUseStatelessSession(true);
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close(executionContext);
假设已为 Customer 表正确创建了休眠 Map 文件,此配置的ItemReader将以与JdbcCursorItemReader所述完全相同的方式返回CustomerCredit个对象。 “ useStatelessSession”属性默认为 true,但已在此处添加,以引起人们注意打开或关闭该属性的能力。还值得注意的是,可以通过 setFetchSize 属性设置基础游标的 fetchSize。与JdbcCursorItemReader一样,配置非常简单:
<bean id="itemReader"
class="org.springframework.batch.item.database.HibernateCursorItemReader">
<property name="sessionFactory" ref="sessionFactory" />
<property name="queryString" value="from CustomerCredit" />
</bean>
StoredProcedureItemReader
有时有必要使用存储过程获取游标数据。 StoredProcedureItemReader的工作方式与JdbcCursorItemReader相似,不同之处在于,我们不执行查询来获取游标,而是执行存储过程来返回游标。存储过程可以通过三种不同的方式返回游标:
- 作为返回的 ResultSet(由 SQL Server,Sybase,DB2,Derby 和 MySQL 使用)
- 作为作为 out 参数返回的参考光标(由 Oracle 和 PostgreSQL 使用)
- 作为存储函数调用的返回值
以下是使用与之前相同的“Client 信用”示例的基本示例配置:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="rowMapper">
<bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/>
</property>
</bean>
本示例依赖于存储过程来提供 ResultSet 作为返回结果(上述选项 1)。
如果存储过程返回了一个 ref-cursor(选项 2),那么我们将需要提供 out 参数的位置,即返回的 ref-cursor。这是一个示例,其中第一个参数是返回的参考光标:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper">
<bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/>
</property>
</bean>
如果游标是从存储的函数(选项 3)返回的,则需要将属性“ function”设置为true。默认为false。Watch 起来像这样:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="function" value="true"/>
<property name="rowMapper">
<bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/>
</property>
</bean>
在所有这些情况下,我们都需要定义RowMapper以及DataSource以及实际过程名称。
如果存储过程或函数接受参数,则必须通过 parameters 属性声明和设置它们。这是一个声明三个参数的 Oracle 示例。第一个是返回参量的 out 参数,第二个和第三个是采用 INTEGER 类型值的 in 参数:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="spring.cursor_func"/>
<property name="parameters">
<list>
<bean class="org.springframework.jdbc.core.SqlOutParameter">
<constructor-arg index="0" value="newid"/>
<constructor-arg index="1">
<util:constant static-field="oracle.jdbc.OracleTypes.CURSOR"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="amount"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="custid"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
</list>
</property>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper" ref="rowMapper"/>
<property name="preparedStatementSetter" ref="parameterSetter"/>
</bean>
除了参数声明外,我们还需要指定一个PreparedStatementSetter实现,以设置调用的参数值。这与上面的JdbcCursorItemReader相同。 称为“其他属性”的部分中列出的所有其他属性也适用于StoredProcedureItemReader。
6.9.2 分页 ItemReader
使用数据库游标的另一种方法是执行多个查询,其中每个查询都带回一部分结果。我们将此部分称为页面。每个执行的查询必须指定起始行号和我们要为页面返回的行数。
JdbcPagingItemReader
寻呼ItemReader的一种实现是JdbcPagingItemReader。 JdbcPagingItemReader需要一个PagingQueryProvider负责提供用于检索组成页面的行的 SQL 查询。由于每个数据库都有其提供分页支持的策略,因此我们需要为每种受支持的数据库类型使用不同的PagingQueryProvider。还有SqlPagingQueryProviderFactoryBean可以自动检测正在使用的数据库并确定适当的PagingQueryProvider实现。这简化了配置,是推荐的最佳实践。
SqlPagingQueryProviderFactoryBean要求您指定一个 select 子句和一个 from 子句。您还可以提供可选的 where 子句。这些子句将用于构建与所需 sortKey 组合的 SQL 语句。
Note
重要的是在 sortKey 上具有唯一的键约束,以确保两次执行之间不会丢失任何数据。
打开 Reader 后,它将以与任何其他ItemReader相同的基本方式将每个调用中的一项传递回read。当需要其他行时,分页将在幕后进行。
以下是使用与上面的基于光标的 ItemReader 类似的“Client 信用”示例的示例配置:
<bean id="itemReader" class="org.spr...JdbcPagingItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="queryProvider">
<bean class="org.spr...SqlPagingQueryProviderFactoryBean">
<property name="selectClause" value="select id, name, credit"/>
<property name="fromClause" value="from customer"/>
<property name="whereClause" value="where status=:status"/>
<property name="sortKey" value="id"/>
</bean>
</property>
<property name="parameterValues">
<map>
<entry key="status" value="NEW"/>
</map>
</property>
<property name="pageSize" value="1000"/>
<property name="rowMapper" ref="customerMapper"/>
</bean>
此配置的ItemReader将使用必须指定的RowMapper返回CustomerCredit个对象。 “ pageSize”属性确定每次查询执行时从数据库读取的实体数。
‘parameterValues’属性可用于指定查询的参数值 Map。如果在 where 子句中使用命名参数,则每个条目的键应与命名参数的名称匹配。如果使用传统的“?”占位符,则每个条目的键应为占位符的编号,从 1 开始。
JpaPagingItemReader
寻呼ItemReader的另一种实现是JpaPagingItemReader。 JPA 没有与 Hibernate StatelessSession类似的概念,因此我们必须使用 JPA 规范提供的其他功能。由于 JPA 支持分页,因此在使用 JPA 进行批处理时,这是自然的选择。读取每个页面后,实体将被分离,并且持久性上下文将被清除,以允许在处理页面后对实体进行垃圾回收。
JpaPagingItemReader允许您声明 JPQL 语句并传递EntityManagerFactory。然后,它将以与任何其他ItemReader相同的基本方式将每次调用将一项返回给read。当需要其他实体时,分页发生在幕后。以下是使用与上述 JDBCReader 相同的“Client 信用”示例的示例配置:
<bean id="itemReader" class="org.spr...JpaPagingItemReader">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="queryString" value="select c from CustomerCredit c"/>
<property name="pageSize" value="1000"/>
</bean>
假设 Customer 对象具有正确的 JPA 注解或 ORMMap 文件,此配置的ItemReader将以与上面JdbcPagingItemReader所述完全相同的方式返回CustomerCredit个对象。 “ pageSize”属性确定每次查询执行时从数据库读取的实体数。
IbatisPagingItemReader
Note
从 Spring Batch 3.0 开始不推荐使用该 Reader。
如果使用 IBATIS 进行数据访问,则可以使用IbatisPagingItemReader,顾名思义,它是分页ItemReader的实现。 IBATIS 不直接支持读取页面中的行,但是通过提供几个标准变量,您可以为 IBATIS 查询添加分页支持。
这是上面示例中的IbatisPagingItemReader读取 CustomerCredits 的配置示例:
<bean id="itemReader" class="org.spr...IbatisPagingItemReader">
<property name="sqlMapClient" ref="sqlMapClient"/>
<property name="queryId" value="getPagedCustomerCredits"/>
<property name="pageSize" value="1000"/>
</bean>
上面的IbatisPagingItemReader配置引用了一个名为“ getPagedCustomerCredits”的 IBATIS 查询。这是有关 MySQL 查询的示例。
<select id="getPagedCustomerCredits" resultMap="customerCreditResult">
select id, name, credit from customer order by id asc LIMIT #_skiprows#, #_pagesize#
</select>
_skiprows和_pagesize变量由IbatisPagingItemReader提供,并且如有必要,还可以使用_page变量。分页查询的语法因所使用的数据库而异。这是 Oracle 的示例(不幸的是,我们需要对某些运算符使用 CDATA,因为它属于 XML 文档):
<select id="getPagedCustomerCredits" resultMap="customerCreditResult">
select * from (
select * from (
select t.id, t.name, t.credit, ROWNUM ROWNUM_ from customer t order by id
)) where ROWNUM_ <![CDATA[ > ]]> ( #_page# * #_pagesize# )
) where ROWNUM <![CDATA[ <= ]]> #_pagesize#
</select>
6.9.3 数据库 ItemWriters
虽然平面文件和 XML 都有特定的 ItemWriter,但在数据库世界中没有确切的等效项。这是因为事务提供了所需的所有功能。 ItemWriters 对于文件来说是必需的,因为它们必须像处理事务一样工作,跟踪已写入的 Item 并在适当的时间进行刷新或清除。数据库不需要此功能,因为写入已包含在事务中。用户可以创建自己的 DAO 来实现ItemWriter接口,也可以使用自定义ItemWriter中的 DAO 来处理通用的处理问题,无论哪种方式,他们都应该可以正常工作。需要注意的一件事是批处理输出所提供的性能和错误处理功能。这在将 hibernate 用作ItemWriter时最常见,但在使用 Jdbc 批处理模式时可能会有相同的问题。假设我们要小心刷新并且数据中没有错误,则批处理数据库输出没有任何固有的缺陷。但是,写出时发生的任何错误都可能引起混乱,因为无法知道哪个单个 Item 导致了异常,或者甚至没有任何单个 Item 负责,如下所示:
如果项在被写出之前被缓冲,则遇到的任何错误都不会被抛出,直到在提交之前刷新缓冲区为止。例如,假设每个块将写入 20 个 Item,第 15 个 Item 将引发 DataIntegrityViolationException。就“步骤”而言,所有 20 个 Item 都将成功写出,因为在实际写出之前没有办法知道会发生错误。调用Session# flush()后,缓冲区将被清空,并且将触发异常。此时,Step无能为力,必须回滚该事务。通常,此异常可能导致 Item 被跳过(取决于跳过/重试策略),然后将不会再次将其写出。但是,在批处理方案中,无法知道是哪个 Item 导致了问题,故障发生时整个缓冲区都被写了出来。解决此问题的唯一方法是在每个 Item 之后冲洗:
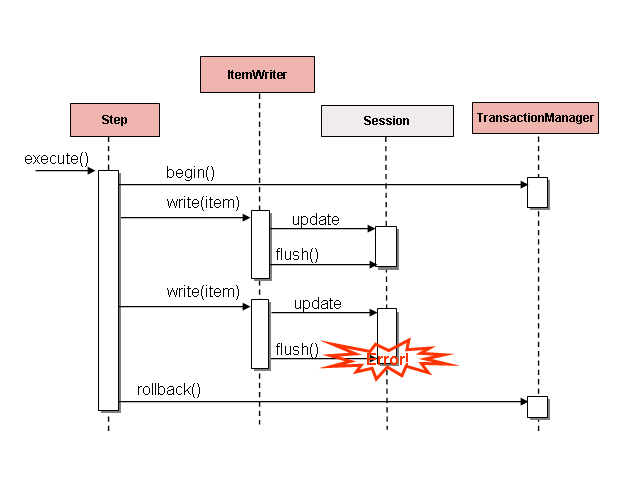
这是一个常见的用例,尤其是在使用 Hibernate 时,实现ItemWriter的简单准则是在每次调用write()时刷新。这样做可以使 Item 可靠地被跳过,Spring Batch 在内部会在发生错误后对ItemWriter的调用粒度进行内部维护。
6.10 重用现有服务
批处理系统通常与其他应用程序样式结合使用。最常见的是在线系统,但它也可以通过移动每种应用程序样式使用的必要批量数据来支持集成甚至胖 Client 端应用程序。因此,许多用户通常都想在其批处理作业中重用现有的 DAO 或其他服务。通过允许注入任何必需的类,Spring 容器本身使此操作相当容易。但是,在某些情况下,现有服务需要充当ItemReader或ItemWriter,以满足另一个 Spring Batch 类的依赖关系,或者因为它确实是某个步骤的主要ItemReader。为每个需要包装的服务编写一个适配器类很简单,但是由于这是一个普遍的问题,Spring Batch 提供了ItemReaderAdapter和ItemWriterAdapter的实现。这两个类都实现了调用委托模式的标准 Spring 方法,并且设置起来非常简单。以下是 Reader 的示例:
<bean id="itemReader" class="org.springframework.batch.item.adapter.ItemReaderAdapter">
<property name="targetObject" ref="fooService" />
<property name="targetMethod" value="generateFoo" />
</bean>
<bean id="fooService" class="org.springframework.batch.item.sample.FooService" />
需要注意的重要一点是 targetMethod 的协定必须与read的协定相同:用尽时它将返回 null,否则返回Object。根据ItemWriter的实现,其他任何因素都将阻止框架知道处理何时结束,从而导致无限循环或错误失败。 ItemWriter实现同样简单:
<bean id="itemWriter" class="org.springframework.batch.item.adapter.ItemWriterAdapter">
<property name="targetObject" ref="fooService" />
<property name="targetMethod" value="processFoo" />
</bean>
<bean id="fooService" class="org.springframework.batch.item.sample.FooService" />
6.11 验证 Importing
在本章的过程中,讨论了多种解析 Importing 的方法。如果每个主要实现的格式都不正确,则将引发异常。如果缺少一系列数据,FixedLengthTokenizer将引发异常。同样,尝试访问FieldSetMapper的RowMapper中不存在的索引或格式与预期的格式不同的索引将导致引发异常。所有这些类型的异常都将在read返回之前引发。但是,它们无法解决退回商品是否有效的问题。例如,如果字段之一是年龄,则显然不能为负。它将正确解析,因为它已经存在并且是一个数字,但是不会引起异常。由于已经存在大量的 Validation 框架,因此 Spring Batch 不会尝试提供另一个框架,而是提供了一个非常简单的接口,可以由许多框架实现:
public interface Validator {
void validate(Object value) throws ValidationException;
}
约定是,如果对象无效,则validate方法将引发异常,如果有效,则正常返回。 Spring Batch 提供了开箱即用的ItemProcessor:
<bean class="org.springframework.batch.item.validator.ValidatingItemProcessor">
<property name="validator" ref="validator" />
</bean>
<bean id="validator"
class="org.springframework.batch.item.validator.SpringValidator">
<property name="validator">
<bean id="orderValidator"
class="org.springmodules.validation.valang.ValangValidator">
<property name="valang">
<value>
<![CDATA[
{ orderId : ? > 0 AND ? <= 9999999999 : 'Incorrect order ID' : 'error.order.id' }
{ totalLines : ? = size(lineItems) : 'Bad count of order lines'
: 'error.order.lines.badcount'}
{ customer.registered : customer.businessCustomer = FALSE OR ? = TRUE
: 'Business customer must be registered'
: 'error.customer.registration'}
{ customer.companyName : customer.businessCustomer = FALSE OR ? HAS TEXT
: 'Company name for business customer is mandatory'
:'error.customer.companyname'}
]]>
</value>
</property>
</bean>
</property>
</bean>
这个简单的示例显示了一个简单的ValangValidator,用于验证订单对象。目的不是为了展示 Valang 功能,而是为了展示如何添加验证器。
6.12 防止状态持久化
默认情况下,所有ItemReader和ItemWriter实现都在提交前将其当前状态存储在ExecutionContext中。但是,这可能并不总是所需的行为。例如,许多开发人员选择使用过程指示器来使其数据库读取器“可重新运行”。在 Importing 数据中添加了一个额外的列,以指示是否已对其进行处理。当读取(或写出)特定记录时,已处理标志将从 false 翻转为 true。然后,SQL 语句可以在 where 子句中包含一个额外的语句,例如“ where PROCESSED_IND = false”,从而确保在重新启动的情况下仅返回未处理的记录。在这种情况下,最好不要存储任何状态,例如当前行号,因为它在重启时将是无关紧要的。因此,所有 Reader 和 Writer 都包含“ saveState”属性:
<bean id="playerSummarizationSource" class="org.spr...JdbcCursorItemReader">
<property name="dataSource" ref="dataSource" />
<property name="rowMapper">
<bean class="org.springframework.batch.sample.PlayerSummaryMapper" />
</property>
<property name="saveState" value="false" />
<property name="sql">
<value>
SELECT games.player_id, games.year_no, SUM(COMPLETES),
SUM(ATTEMPTS), SUM(PASSING_YARDS), SUM(PASSING_TD),
SUM(INTERCEPTIONS), SUM(RUSHES), SUM(RUSH_YARDS),
SUM(RECEPTIONS), SUM(RECEPTIONS_YARDS), SUM(TOTAL_TD)
from games, players where players.player_id =
games.player_id group by games.player_id, games.year_no
</value>
</property>
</bean>
上面配置的ItemReader不会对其参与的执行在ExecutionContext中进行任何 Importing。
6.13 创建自定义 ItemReader 和 ItemWriters
到目前为止,本章已经讨论了 Spring Batch 中存在的用于读写的基本协定以及一些常见的实现。但是,这些都是相当通用的,开箱即用的实现可能无法涵盖很多潜在的场景。本节将通过一个简单的示例说明如何创建自定义的ItemReader和ItemWriter实现并正确实现其 Contract。 ItemReader还将实现ItemStream,以说明如何使读取器或写入器可重新启动。
6.13.1 自定义 ItemReader 示例
就本示例而言,将创建一个从提供的列表中读取的简单ItemReader实现。我们将从实现ItemReader,read的最基本 Contract 开始:
public class CustomItemReader<T> implements ItemReader<T>{
List<T> items;
public CustomItemReader(List<T> items) {
this.items = items;
}
public T read() throws Exception, UnexpectedInputException,
NoWorkFoundException, ParseException {
if (!items.isEmpty()) {
return items.remove(0);
}
return null;
}
}
这个非常简单的类获取一个 Item 列表,然后一次返回一个 Item,将其从列表中删除。当列表为空时,它返回 null,从而满足ItemReader的最基本要求,如下所示:
List<String> items = new ArrayList<String>();
items.add("1");
items.add("2");
items.add("3");
ItemReader itemReader = new CustomItemReader<String>(items);
assertEquals("1", itemReader.read());
assertEquals("2", itemReader.read());
assertEquals("3", itemReader.read());
assertNull(itemReader.read());
使 ItemReader 可重新启动
现在的最后一个挑战是使ItemReader可重新启动。当前,如果断电,并且处理再次开始,则ItemReader必须从头开始。这实际上在许多情况下都是有效的,但有时最好在批处理作业从它停止的地方开始。关键的区别通常是 Reader 是有状态的还是 Stateless 的。Stateless 读取器无需担心可重新启动性,但是有状态读取器必须尝试重新启动时重新构造其最后一个已知状态。因此,我们建议您尽可能使自定义 Reader 保持 Stateless,因此您不必担心可重新启动性。
如果确实需要存储状态,则应使用ItemStream接口:
public class CustomItemReader<T> implements ItemReader<T>, ItemStream {
List<T> items;
int currentIndex = 0;
private static final String CURRENT_INDEX = "current.index";
public CustomItemReader(List<T> items) {
this.items = items;
}
public T read() throws Exception, UnexpectedInputException,
ParseException {
if (currentIndex < items.size()) {
return items.get(currentIndex++);
}
return null;
}
public void open(ExecutionContext executionContext) throws ItemStreamException {
if(executionContext.containsKey(CURRENT_INDEX)){
currentIndex = new Long(executionContext.getLong(CURRENT_INDEX)).intValue();
}
else{
currentIndex = 0;
}
}
public void update(ExecutionContext executionContext) throws ItemStreamException {
executionContext.putLong(CURRENT_INDEX, new Long(currentIndex).longValue());
}
public void close() throws ItemStreamException {}
}
每次调用ItemStream update方法时,ItemReader的当前索引将通过键“ current.index”存储在提供的ExecutionContext中。调用ItemStream open方法时,将检查ExecutionContext以查 Watch 其是否包含具有该键的条目。如果找到该键,则当前索引将移动到该位置。这是一个非常琐碎的示例,但仍然符合一般约定:
ExecutionContext executionContext = new ExecutionContext();
((ItemStream)itemReader).open(executionContext);
assertEquals("1", itemReader.read());
((ItemStream)itemReader).update(executionContext);
List<String> items = new ArrayList<String>();
items.add("1");
items.add("2");
items.add("3");
itemReader = new CustomItemReader<String>(items);
((ItemStream)itemReader).open(executionContext);
assertEquals("2", itemReader.read());
大多数 ItemReader 具有更复杂的重启逻辑。例如JdbcCursorItemReader,将最后处理的行的行 ID 存储在游标中。
还值得注意的是,ExecutionContext中使用的密钥不应太小。这是因为Step中的所有ItemStream使用相同的ExecutionContext。在大多数情况下,只需在键之前加上类名就足以保证唯一性。但是,在极少数情况下,在同一步骤中使用两个相同类型的ItemStream(如果需要输出两个文件,可能会发生这种情况),那么将需要一个更唯一的名称。因此,许多 Spring Batch ItemReader和ItemWriter实现都具有setName()属性,该属性允许覆盖此键名。
6.13.2 自定义 ItemWriter 示例
实现自定义ItemWriter的方式与上述ItemReader的示例在很多方面都相似,但是在足以保证其自己的示例方面有很多不同。但是,添加可重新启动性本质上是相同的,因此在本示例中将不涉及它。与ItemReader示例一样,将使用List来使示例尽可能简单:
public class CustomItemWriter<T> implements ItemWriter<T> {
List<T> output = TransactionAwareProxyFactory.createTransactionalList();
public void write(List<? extends T> items) throws Exception {
output.addAll(items);
}
public List<T> getOutput() {
return output;
}
}
使 ItemWriter 可重新启动
为了使 ItemWriter 可重新启动,我们将遵循与ItemReader相同的过程,添加并实现ItemStream接口以同步执行上下文。在该示例中,我们可能必须计算已处理的 Item 数,并将其添加为页脚记录。如果需要这样做,则可以在ItemWriter中实现ItemStream,以便在重新打开流时从执行上下文重新构造计数器。
在许多实际情况下,自定义 ItemWriters 还会委派给另一个本身可重新启动的编写器(例如,在写入文件时),否则它会写入事务性资源,因此不需要重新启动,因为它是 Stateless 的。当您有状态 Writer 时,您可能还应该确保实现ItemStream和ItemWriter。还请记住,Writer 的 Client 端需要了解ItemStream,因此您可能需要将其作为流注册到配置 xml 中。
7. 缩放和并行处理
单线程,单流程作业可以解决许多批处理问题,因此在考虑更复杂的实现之前,适当地检查是否满足您的需求始终是一个好主意。测量实际工作的性能,并首先查 Watch 最简单的实现是否满足您的需求:即使使用标准硬件,您也可以在一分钟之内轻松读写数百兆的文件。
当您准备开始通过并行处理实现作业时,Spring Batch 提供了一系列选项,本章对此进行了介绍,尽管其他地方介绍了一些功能。在较高级别上,有两种并行处理模式:单进程,多线程;和多进程。这些也分为以下几类:
- 多线程步骤(单进程)
- 并行步骤(单个过程)
- 步骤的远程分块(多进程)
- 分区步骤(单个或多个进程)
接下来,我们首先查 Watch 单进程选项,然后再查 Watch 多进程选项。
7.1 多线程步骤
开始并行处理的最简单方法是将TaskExecutor添加到您的 Step 配置中,例如作为tasklet的属性:
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>
在此示例中,taskExecutor 是对另一个 Bean 定义的引用,实现了TaskExecutor接口。 TaskExecutor是标准的 Spring 界面,因此请查阅《 Spring 用户指南》以获取可用实现的详细信息。最简单的多线程TaskExecutor是SimpleAsyncTaskExecutor。
以上配置的结果是,该步骤通过在单独的执行线程中读取,处理和写入每个 Item 块(每个提交间隔)来执行。请注意,这意味着要处理的 Item 没有固定的 Sequences,与单线程情况相比,大块可能包含不连续的 Item。除了任务 Actuator 设置的任何限制(例如,如果它由线程池支持)之外,tasklet 配置中还有一个限制值,默认为 4.您可能需要增加此限制以确保线程池已满利用,例如
<step id="loading"> <tasklet
task-executor="taskExecutor"
throttle-limit="20">...</tasklet>
</step>
还请注意,您的步骤中使用的任何池化资源(例如DataSource)可能对并发设置了限制。确保在这些步骤中使这些资源中的池至少与所需的并发线程数一样大。
对于某些常见的批处理用例,使用多线程步骤存在一些实际限制。步骤中的许多参与者(例如,读取器和写入器)都是有状态的,并且如果状态不是按线程划分的,则这些组件不能在多线程步骤中使用。特别是,Spring Batch 的大多数现成的读写器都不是为多线程使用而设计的。但是,可以与 Stateless 或线程安全的读取器和写入器一起使用,并且 Spring Batchsamples 中有一个 samples(parallelJob),该 samples 显示了使用过程指示器(请参见第 6.12 节“防止状态持久性”)来跟踪已被删除的 Item。在数据库 Importing 表中处理。
Spring Batch 提供了ItemWriter和ItemReader的一些实现。通常,他们在 Javadocs 中说它们是否是线程安全的,或者为避免在并发环境中发生问题而必须采取的措施。如果 Javadocs 中没有信息,则可以检查实现以查 Watch 是否存在任何状态。如果 Reader 不是线程安全的,则在自己的同步委托器中使用它仍然可能是有效的。您可以将调用同步到read(),只要处理和写入是块中最昂贵的部分,您的步骤仍可能比单线程配置中完成速度快得多。
7.2Parallel 步骤
只要可以将需要并行化的应用程序逻辑划分为不同的职责,并分配给各个步骤,然后就可以在单个过程中对其进行并行化。并行步骤执行易于配置和使用,例如,要与step3并行执行步骤(step1,step2),可以配置如下流程:
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>
可配置的“任务 Actuator”属性用于指定应使用哪个 TaskExecutor 实现来执行各个流程。默认值为SyncTaskExecutor,但是需要异步 TaskExecutor 才能并行运行这些步骤。请注意,该作业将确保在汇总 Export 状态并进行过渡之前,拆分中的每个流均已完成。
有关更多详细信息,请参见第 5.3.5 节“拆分流”部分。
7.3 远程分块
在远程分块中,分步处理被划分为多个进程,并通过某种中间件相互通信。这是实际模式的图片:
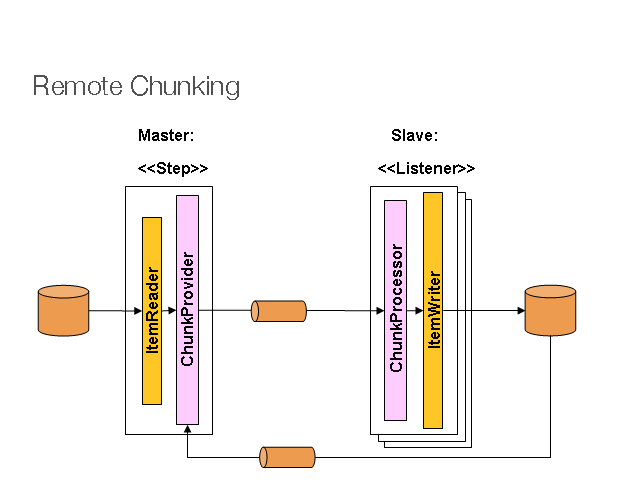
主组件是单个进程,从组件是多个远程进程。显然,如果母版不是瓶颈,则此模式最有效,因此处理必须比读取 Item 更昂贵(在实践中通常是这种情况)。
Master 只是 Spring Batch Step的一种实现,ItemWriter 替换为一个通用版本,该通用版本知道如何将 Item 块作为消息发送到中间件。从站是正在使用的任何中间件的标准侦听器(例如,对于 JMS,它们将是MesssageListeners),它们的作用是通过ChunkProcessor接口使用标准的ItemWriter或ItemProcessor加ItemWriter处理 Item 块。使用此模式的优点之一是读取器,处理器和写入器组件都是现成的(与用于步骤的本地执行的组件相同)。这些 Item 是动态划分的,并且工作是通过中间件共享的,因此,如果侦听器都是渴望的使用者,那么负载平衡是自动的。
中间件必须是耐用的,并保证传递和每个消息的单一使用者。 JMS 很明显是候选者,但是网格计算和共享内存产品空间(例如 Java Spaces)中存在其他选择。
7.4 Partitioning
Spring Batch 还提供了一个 SPI,用于对 Step 执行进行分区并远程执行。在这种情况下,远程参与者只是 Step 实例,可以轻松地对其进行配置并将其用于本地处理。这是实际模式的图片:
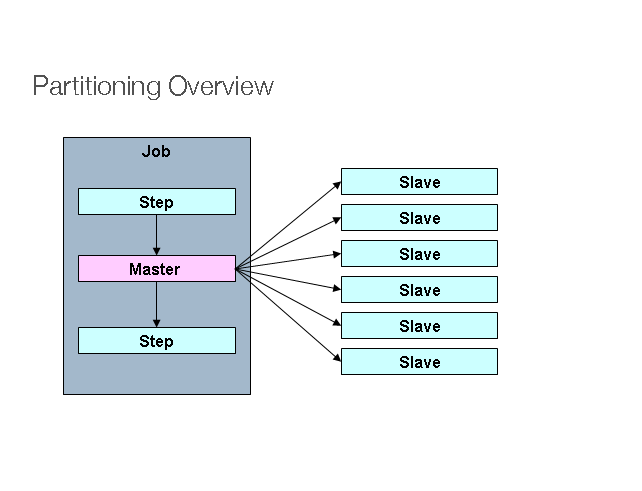
作业作为一系列步骤在左侧执行,并且其中一个步骤标记为“主要”。此图中的从属都是一个步骤的所有相同实例,实际上可以代替主从,从而为工作带来相同的结果。从站通常将是远程服务,但也可能是本地执行线程。主服务器以这种模式发送到从属服务器的消息不需要持久或不需要保证传递:JobRepository中的 Spring Batch 元数据将确保每个从属服务器执行一次,并且每次执行作业仅一次。
Spring Batch 中的 SPI 包含步骤(PartitionStep)的特殊实现,以及针对特定环境需要实现的两个策略接口。策略接口是PartitionHandler和StepExecutionSplitter,它们的作用在下面的序列图中显示:
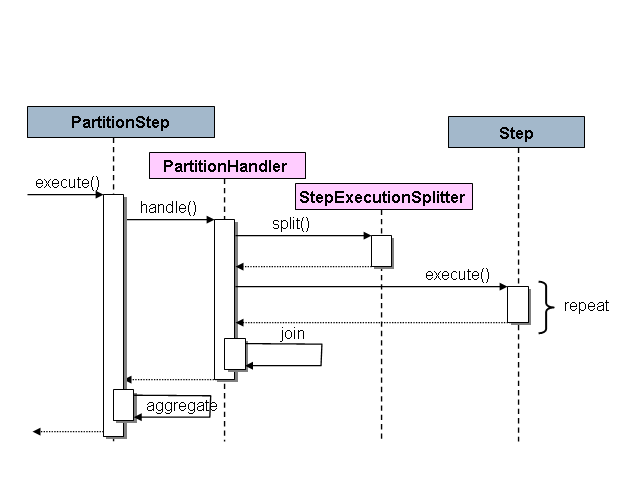
在这种情况下,右侧的步骤是“远程”从设备,因此可能有许多对象和/或进程在扮演该角色,并且显示了 PartitionStep 驱动执行。 PartitionStep 配置如下所示:
<step id="step1.master">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>
与多线程步骤的油门限制属性相似,grid-size 属性可防止任务执行程序被单个步骤的请求所饱和。
有一个简单的示例,可以在 Spring Batch Samples 的单元测试套件中进行复制和扩展(请参见*PartitionJob.xml配置)。
Spring Batch 为名为“ step1:partition0”等的分区创建了步骤执行,因此许多人更喜欢将主步骤称为“ step1:master”以保持一致性。在 Spring 3.0 中,您可以使用步骤别名(指定name属性而不是id)来实现。
7.4.1 PartitionHandler
PartitionHandler是了解远程或网格环境的结构的组件。它能够将StepExecution请求发送到以某些特定于结构的格式包装的远程步骤,例如 DTO。它不必知道如何分割 Importing 数据,或如何汇总多个 Step 执行的结果。一般而言,它可能也不需要了解弹性或故障转移,因为在许多情况下,这些是结构的功能,并且无论如何,Spring Batch 始终提供独立于结构的可重新启动性:失败的 Job 可以始终重新启动,而只有失败的作业步骤将重新执行。
The PartitionHandler界面可以针对多种结构类型进行专门的实现:例如简单的 RMI 远程处理,EJB 远程处理,自定义 Web 服务,JMS,Java 空间,共享内存网格(例如 Terracotta 或 Coherence),网格执行结构(例如 GridGain)。 Spring Batch 不包含任何专有网格或远程结构的实现。
但是,Spring Batch 确实提供了PartitionHandler的有用实现,该实现使用 Spring 的TaskExecutor策略在单独的执行线程中本地执行步骤。该实现称为TaskExecutorPartitionHandler,它是使用上述 XML 名称空间配置的步骤的默认设置。也可以像这样显式配置:
<step id="step1.master">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>
gridSize确定要创建的单独步骤执行的数量,因此可以将其与TaskExecutor中的线程池的大小匹配,或者可以将其设置为大于可用线程的数量,在这种情况下,工作量较小。
TaskExecutorPartitionHandler对于 IO 密集型步骤非常有用,例如复制大量文件或将文件系统复制到内容 Management 系统中。通过提供作为远程调用代理的 Step 实现(例如,使用 Spring Remoting),也可以将其用于远程执行。
7.4.2 Partitioner
分区程序的职责更简单:仅将生成上下文作为 Importing 参数生成新步执行(无需担心重新启动)。它只有一个方法:
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
此方法的返回值将每个步骤执行的唯一名称(String)与ExecutionContext形式的 Importing 参数相关联。这些名称稍后会在批处理元数据中显示为分区StepExecutions中的步骤名称。 ExecutionContext只是一袋名称/值对,因此它可能包含一系列主键,行号或 Importing 文件的位置。然后,远程Step通常使用#{...}占位符(步骤范围中的后期绑定)绑定到上下文 Importing,如下一节所述。
步骤执行的名称(由Partitioner返回的Map中的键)在 Job 的步骤执行中必须是唯一的,但没有其他特定要求。最简单的方法是使前缀对用户有意义,这是使用前缀后缀命名约定,其中前缀是正在执行的步骤的名称(它本身在Job中是唯一的),而后缀只是一个计数器。使用此约定的框架中有一个SimplePartitioner。
可选接口PartitioneNameProvider可用于与分区本身分开提供分区名称。如果Partitioner实现此接口,则在重新启动时仅查询名称。如果分区昂贵,这可能是有用的优化。显然,PartitioneNameProvider提供的名称必须与Partitioner提供的名称匹配。
7.4.3 将 Importing 数据绑定到步骤
由 PartitionHandler 执行的步骤具有相同的配置,并在运行时从 ExecutionContext 绑定它们的 Importing 参数,这非常有效。使用 Spring Batch 的 StepScope 功能很容易做到(在Late Binding的小节中有更详细的介绍)。例如,如果Partitioner使用属性键fileName创建ExecutionContext实例,并为每个步骤调用指向一个不同的文件(或目录),则Partitioner的输出可能如下所示:
表 7.1. 分区程序目标目录处理提供的示例执行上下文名称到执行上下文
| 步骤执行名称(键) | ExecutionContext (value) |
|---|---|
| filecopy:partition0 | fileName=/home/data/one |
| filecopy:partition1 | fileName=/home/data/two |
| filecopy:partition2 | fileName=/home/data/three |
然后,可以使用后期绑定到执行上下文将文件名绑定到步骤:
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resource" value="#{stepExecutionContext[fileName]}/*"/>
</bean>
8. Repeat
8.1 RepeatTemplate
批处理涉及重复性操作-作为简单的优化或作为工作的一部分。为了对重复进行策略化和通用化并为迭代器框架提供足够的信息,Spring Batch 具有RepeatOperations接口。 RepeatOperations界面如下所示:
public interface RepeatOperations {
RepeatStatus iterate(RepeatCallback callback) throws RepeatException;
}
回调是一个简单的接口,允许您插入一些要重复的业务逻辑:
public interface RepeatCallback {
RepeatStatus doInIteration(RepeatContext context) throws Exception;
}
回调将重复执行,直到实现决定迭代结束为止。这些接口中的返回值是一个枚举,可以是RepeatStatus.CONTINUABLE或RepeatStatus.FINISHED。 RepeatStatus将有关是否还有更多工作要做的信息传达给重复操作的调用者。一般来说,RepeatOperations的实现应检查RepeatStatus并将其用作结束迭代的决定的一部分。任何希望向调用者发送 signal 的通知,它们都可以返回RepeatStatus.FINISHED。
RepeatOperations最简单的通用实现是RepeatTemplate。可以这样使用:
RepeatTemplate template = new RepeatTemplate();
template.setCompletionPolicy(new FixedChunkSizeCompletionPolicy(2));
template.iterate(new RepeatCallback() {
public ExitStatus doInIteration(RepeatContext context) {
// Do stuff in batch...
return ExitStatus.CONTINUABLE;
}
});
在该示例中,我们返回RepeatStatus.CONTINUABLE以表明还有更多工作要做。如果回调函数想向调用者发出 signal,表示它没有其他工作要做,那么它也可以返回ExitStatus.FINISHED。某些迭代可以通过回调中完成的工作固有的考虑来终止,就迭代而言,其他迭代实际上是无限循环,并且将完成决策委托给外部策略,如上例所示。
8.1.1 RepeatContext
RepeatCallback的方法参数是RepeatContext。许多回调将仅忽略上下文,但如有必要,可以将其用作属性包,以在迭代过程中存储瞬态数据。 iterate方法返回后,上下文将不再存在。
如果正在进行嵌套嵌套,则RepeatContext将具有父上下文。父上下文有时对于存储需要在iterate的调用之间共享的数据很有用。例如,如果您要计算迭代中事件的发生次数并在后续调用中记住该事件,就属于这种情况。
8.1.2 RepeatStatus
RepeatStatus是 Spring Batch 用来表示处理是否完成的枚举。这些可能是RepeatStatus个值:
表 8.1. ExitStatus 属性
| Value | Description |
|---|---|
| CONTINUABLE | 还有更多工作要做。 |
| FINISHED | 不再重复。 |
也可以使用RepeatStatus中的and()方法将RepeatStatus值与逻辑 AND 操作合并。这样做的结果是对可持续标志进行逻辑与。换句话说,如果任一状态为FINISHED,那么结果将为FINISHED。
8.2 完成 Policy
在RepeatTemplate内部,在iterate方法中循环的终止由CompletionPolicy确定,CompletionPolicy也是RepeatContext的工厂。 RepeatTemplate负责使用当前策略来创建RepeatContext并将其在迭代的每个阶段传递给RepeatCallback。回调完成其doInIteration之后,RepeatTemplate必须调用CompletionPolicy以要求其更新其状态(将存储在RepeatContext中)。然后,它询问策略迭代是否完成。
Spring Batch 提供了CompletionPolicy的一些简单通用实现。 SimpleCompletionPolicy只允许执行固定次数的次数(RepeatStatus.FINISHED可以随时强制提早完成)。
用户可能需要实施自己的完成策略以做出更复杂的决定。例如,一个阻止批处理作业在联机系统正在使用时执行的批处理窗口将需要自定义策略。
8.3 异常处理
如果RepeatCallback内抛出异常,则RepeatTemplate咨询ExceptionHandler,后者可以决定是否重新抛出该异常。
public interface ExceptionHandler {
void handleException(RepeatContext context, Throwable throwable)
throws RuntimeException;
}
一个常见的用例是计算给定类型的异常数,并在达到限制时失败。为此,Spring Batch 提供了SimpleLimitExceptionHandler和更灵活的RethrowOnThresholdExceptionHandler。 SimpleLimitExceptionHandler具有 limit 属性和应与当前异常进行比较的异常类型-还对提供的类型的所有子类进行计数。给定类型的异常将被忽略,直到达到限制,然后重新抛出。其他类型的总是被抛弃。
SimpleLimitExceptionHandler的一个重要的可选属性是布尔标志useParent。默认情况下为 false,因此限制仅在当前RepeatContext中考虑。设置为 true 时,限制在嵌套迭代中跨兄弟上下文保留(例如,步骤中的一组块)。
8.4 Listeners
通常,能够接收更多的回调,以解决许多不同迭代中的交叉问题。为此,Spring Batch 提供了RepeatListener接口。 RepeatTemplate允许用户注册RepeatListener,并且将在迭代过程中向他们提供RepeatContext和RepeatStatus的回调。
界面如下所示:
public interface RepeatListener {
void before(RepeatContext context);
void after(RepeatContext context, RepeatStatus result);
void open(RepeatContext context);
void onError(RepeatContext context, Throwable e);
void close(RepeatContext context);
}
open和close回调在整个迭代之前和之后出现。 before,after和onError适用于各个 RepeatCallback 调用。
请注意,当有多个侦听器时,它们在列表中,因此有一个 Sequences。在这种情况下,open和before的调用 Sequences 相同,而after,onError和close的调用 Sequences 相反。
8.5 并行处理
RepeatOperations的实现不限于 Sequences 执行回调。某些实现能够并行执行其回调非常重要。为此,Spring Batch 提供了TaskExecutorRepeatTemplate,它使用 Spring TaskExecutor策略来运行RepeatCallback。默认是使用SynchronousTaskExecutor,它具有在同一线程中执行整个迭代的效果(与普通RepeatTemplate相同)。
8.6 声明式迭代
有时,您知道某些业务处理需要在每次发生时重复进行。典型的例子是优化消息管道-处理一批消息(如果它们频繁到达)比承担每条消息的单独事务处理的成本更有效。 Spring Batch 为此提供了一个 AOP 拦截器,该方法将方法调用包装在RepeatOperations中。 RepeatOperationsInterceptor执行拦截的方法,并根据提供的RepeatTemplate中的CompletionPolicy重复。
这是一个使用 Spring AOP 名称空间重复声明称为processMessage的服务的声明式迭代的示例(有关如何配置 AOP 拦截器的更多详细信息,请参见 Spring 用户指南):
<aop:config>
<aop:pointcut id="transactional"
expression="execution(* com..*Service.processMessage(..))" />
<aop:advisor pointcut-ref="transactional"
advice-ref="retryAdvice" order="-1"/>
</aop:config>
<bean id="retryAdvice" class="org.spr...RepeatOperationsInterceptor"/>
上面的示例在拦截器内部使用默认的RepeatTemplate。要更改策略,侦听器等,您只需要将RepeatTemplate的实例注入拦截器即可。
如果拦截的方法返回void,则拦截器将始终返回 ExitStatus.CONTINUABLE(因此,如果CompletionPolicy没有 endpoints,则存在无限循环的危险)。否则,它将返回ExitStatus.CONTINUABLE,直到截获方法的返回值为 null 为止,此时它将返回ExitStatus.FINISHED。因此,目标方法内部的业务逻辑可以通过返回null或引发由提供的RepeatTemplate中的ExceptionHandler抛出的异常来发出 signal,表明您无需进行其他工作。
9. Retry
9.1 RetryTemplate
Note
从 2.2.0 版本开始,重试功能已从 Spring Batch 中撤出。现在它是新库 Spring Retry 的一部分。
为了使处理过程更健壮且更不容易出错,有时可以自动重试失败的操作,以防后续尝试成功执行。易受此类处理影响的错误本质上是暂时的。例如,由于网络故障或数据库更新中的DeadLockLoserException而导致对 Web 服务或 RMI 服务的远程调用失败,可能会在短暂的 await 后解决。为了使此类操作自动重试,Spring Batch 具有RetryOperations策略。 RetryOperations界面如下所示:
public interface RetryOperations {
<T> T execute(RetryCallback<T> retryCallback) throws Exception;
<T> T execute(RetryCallback<T> retryCallback, RecoveryCallback<T> recoveryCallback)
throws Exception;
<T> T execute(RetryCallback<T> retryCallback, RetryState retryState)
throws Exception, ExhaustedRetryException;
<T> T execute(RetryCallback<T> retryCallback, RecoveryCallback<T> recoveryCallback,
RetryState retryState) throws Exception;
}
基本回调是一个简单的接口,允许您插入一些要重试的业务逻辑:
public interface RetryCallback<T> {
T doWithRetry(RetryContext context) throws Throwable;
}
回调将被执行,如果失败(通过抛出Exception),则将重试该回调,直到该回调成功或实现决定中止为止。 RetryOperations接口中有许多重载的execute方法,它们处理所有重试尝试都已用尽时用于恢复的各种用例,并且还具有重试状态,这使 Client 端和实现可以在调用之间存储信息(稍后会详细介绍)。
RetryOperations最简单的通用实现是RetryTemplate。可以这样使用
RetryTemplate template = new RetryTemplate();
TimeoutRetryPolicy policy = new TimeoutRetryPolicy();
policy.setTimeout(30000L);
template.setRetryPolicy(policy);
Foo result = template.execute(new RetryCallback<Foo>() {
public Foo doWithRetry(RetryContext context) {
// Do stuff that might fail, e.g. webservice operation
return result;
}
});
在该示例中,我们执行 Web 服务调用并将结果返回给用户。如果该呼叫失败,则重试直到超时。
9.1.1 RetryContext
RetryCallback的方法参数是RetryContext。许多回调将仅忽略上下文,但如有必要,可以将其用作属性包,以在迭代过程中存储数据。
如果在同一线程中正在进行嵌套重试,则RetryContext将具有父上下文。父上下文有时对于存储需要在execute的调用之间共享的数据很有用。
9.1.2 RecoveryCallback
重试完成后,RetryOperations可以将控制权传递给另一个回调RecoveryCallback。要使用此功能,Client 端只需将回调一起传递给相同的方法,例如:
Foo foo = template.execute(new RetryCallback<Foo>() {
public Foo doWithRetry(RetryContext context) {
// business logic here
},
new RecoveryCallback<Foo>() {
Foo recover(RetryContext context) throws Exception {
// recover logic here
}
});
如果在模板决定中止之前业务逻辑未成功,则将使 Client 端有机会通过恢复回调进行一些替代处理。
9.1.3Stateless 重试
在最简单的情况下,重试只是一个 while 循环:RetryTemplate可以 continue 尝试直到成功或失败为止。 RetryContext包含一些状态来确定是重试还是中止,但是此状态在堆栈上,不需要将其全局存储在任何地方,因此我们将其称为 Stateless 重试。Stateless 重试和有状态重试之间的区别包含在RetryPolicy的实现中(RetryTemplate可以同时处理两者)。在 Stateless 重试中,回调总是在失败时在相同的线程中执行。
9.1.4 有状态重试
故障导致事务资源无效的地方,有一些特殊的注意事项。因为通常没有事务资源,所以这不适用于简单的远程调用,但是有时确实适用于数据库更新,尤其是在使用 Hibernate 时。在这种情况下,有意义的是立即重新抛出调用失败的异常,以便事务可以回滚并且我们可以开始一个新的有效事务。
在这些情况下,Stateless 重试不够好,因为重新抛出和回滚必然涉及离开RetryOperations.execute()方法并可能丢失堆栈中的上下文。为了避免丢失它,我们必须引入一种存储策略以将其从堆栈中取出并(至少)放入堆存储中。为此,Spring Batch 提供了一种存储策略RetryContextCache,可以将其注入RetryTemplate。 RetryContextCache的默认实现在内存中,使用简单的Map。在群集环境中对多个进程进行高级使用时,可能还会考虑使用某种类型的群集缓存来实现RetryContextCache(尽管,即使在群集环境中,这也可能会过大)。
RetryOperations的部分职责是识别失败的操作,使其在新的执行中恢复(通常包含在新的事务中)。为方便起见,Spring Batch 提供了RetryState抽象。这与RetryOperations中的特殊execute方法结合使用。
识别失败操作的方式是通过在重试的多次调用中识别状态。为了标识状态,用户可以提供一个RetryState对象,该对象负责返回标识该 Item 的唯一键。标识符用作RetryContextCache中的键。
Warning
在RetryState返回的键中对Object.equals()和Object.hashCode()的实现要非常小心。最好的建议是使用业务密钥来识别 Item。对于 JMS 消息,可以使用消息 ID。
重试用尽后,还可以选择以其他方式处理失败的 Item,而不是调用RetryCallback(现在假定它很可能失败)。就像在 Stateless 情况下一样,此选项由RecoveryCallback提供,可以通过将其传递给RetryOperations的execute方法来提供。
是否重试的决定实际上是委托给常规的RetryPolicy,因此可以将有关限制和超时的常见问题注入那里(请参阅下文)。
9.2 重试策略
在RetryTemplate内部,由RetryPolicy决定execute方法重试还是失败的决定,该RetryPolicy也是RetryContext的工厂。 RetryTemplate负责使用当前策略创建RetryContext,并在每次尝试时将其传递给RetryCallback。回调失败后,RetryTemplate必须调用RetryPolicy以要求其更新其状态(将存储在RetryContext中),然后询问策略是否可以进行另一次尝试。如果无法进行其他尝试(例如,达到限制或检测到超时),则该策略还负责处理耗尽状态。简单的实现只会抛出RetryExhaustedException,这将导致任何封闭的事务被回滚。更复杂的实现可能会尝试采取一些恢复操作,在这种情况下,事务可以保持不变。
Tip
故障本质上是可以重试的,还是不能重试的-如果总是要从业务逻辑中引发相同的异常,则重试将无济于事。因此,请勿重试所有异常类型-尝试仅关注您希望可重试的那些异常。主动重试通常对业务逻辑没有害处,但是这样做是浪费的,因为如果故障是确定性的,那么将有时间花费在重试事先知道是致命的事情上。
Spring Batch 提供了一些 Stateless 的RetryPolicy的简单通用实现,例如SimpleRetryPolicy和上面示例中使用的TimeoutRetryPolicy。
SimpleRetryPolicy仅允许重试任何命名类型的异常类型,最多可重复固定次数。它还有一个“致命”异常列表,这些列表永远都不应重试,并且此列表会覆盖可重试列表,以便可以使用它来更好地控制重试行为:
SimpleRetryPolicy policy = new SimpleRetryPolicy();
// Set the max retry attempts
policy.setMaxAttempts(5);
// Retry on all exceptions (this is the default)
policy.setRetryableExceptions(new Class[] {Exception.class});
// ... but never retry IllegalStateException
policy.setFatalExceptions(new Class[] {IllegalStateException.class});
// Use the policy...
RetryTemplate template = new RetryTemplate();
template.setRetryPolicy(policy);
template.execute(new RetryCallback<Foo>() {
public Foo doWithRetry(RetryContext context) {
// business logic here
}
});
还有一种更灵活的实现,称为ExceptionClassifierRetryPolicy,它允许用户通过ExceptionClassifier抽象为任意一组异常类型配置不同的重试行为。该策略通过调用分类器将异常转换为委托RetryPolicy来起作用,例如,与通过将异常 Map 到其他策略相比,可以在失败之前重试一个异常类型多次。
用户可能需要实施自己的重试策略以进行更多自定义的决策。例如,如果存在众所周知的,特定于解决方案的 exception,则将异常分类为可重试和不可重试。
9.3 退避 Policy
在短暂故障后重试时,通常有助于稍等一会再尝试,因为通常故障是由某些问题引起的,只有通过 await 才能解决。如果RetryCallback失败,则RetryTemplate可以根据适当的BackoffPolicy暂停执行。
public interface BackoffPolicy {
BackOffContext start(RetryContext context);
void backOff(BackOffContext backOffContext)
throws BackOffInterruptedException;
}
BackoffPolicy可以自由选择以任何方式实施 backOff。 Spring Batch 提供的现成策略都使用Object.wait()。一个常见的用例是使用成倍增加的 await 时间来回退,以避免两次重试进入锁定步骤而都失败了-这是从以太网中学到的教训。为此,Spring Batch 提供了ExponentialBackoffPolicy。
9.4 Listeners
通常,能够收到更多的回调,以解决许多不同的重试中的交叉问题。为此,Spring Batch 提供了RetryListener接口。 RetryTemplate允许用户注册RetryListener,并且将在迭代过程中向他们提供RetryContext和Throwable的回调。
界面如下所示:
public interface RetryListener {
void open(RetryContext context, RetryCallback<T> callback);
void onError(RetryContext context, RetryCallback<T> callback, Throwable e);
void close(RetryContext context, RetryCallback<T> callback, Throwable e);
}
在最简单的情况下,open和close回调在整个重试之前和之后出现,并且onError适用于单个RetryCallback调用。 close方法可能还会收到Throwable;如果有错误,则是RetryCallback抛出的最后一个错误。
请注意,当有多个侦听器时,它们在列表中,因此有一个 Sequences。在这种情况下,open的调用 Sequences 相同,而onError和close的调用 Sequences 相反。
9.5 声明式重试
有时,您知道某些业务处理每次发生时都想重试。典型的例子是远程服务调用。 Spring Batch 为此提供了一个 AOP 拦截器,该方法将方法调用包装在RetryOperations中。 RetryOperationsInterceptor根据提供的RepeatTemplate中的RetryPolicy执行拦截的方法并重试失败。
这是一个使用 Spring AOP 名称空间重复声明称为remoteCall的服务的声明式迭代的示例(有关如何配置 AOP 拦截器的更多详细信息,请参见 Spring 用户指南):
<aop:config>
<aop:pointcut id="transactional"
expression="execution(* com..*Service.remoteCall(..))" />
<aop:advisor pointcut-ref="transactional"
advice-ref="retryAdvice" order="-1"/>
</aop:config>
<bean id="retryAdvice"
class="org.springframework.batch.retry.interceptor.RetryOperationsInterceptor"/>
上面的示例在拦截器内部使用默认的RetryTemplate。要更改策略或侦听器,您只需要将RetryTemplate的实例注入到拦截器中。
10. Unit Testing
与其他应用程序样式一样,对作为批处理作业一部分编写的任何代码进行单元测试也非常重要。 Spring 核心文档详细介绍了如何对 Spring 进行单元测试和集成测试,因此在此不再赘述。但是,重要的是考虑如何“端对端”测试批处理作业,这是本章将重点讨论的内容。Spring Batch 测试 Item 包括有助于简化这种端到端测试方法的类。
10.1 创建单元测试类
为了使单元测试运行批处理作业,框架必须加载作业的 ApplicationContext。使用两个 Comments 来触发此操作:
@RunWith(SpringJUnit4ClassRunner.class):指示该类应使用 Spring 的 JUnit 工具@ContextConfiguration(locations = {...}):指示哪些 XML 文件包含 ApplicationContext。@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = { "/simple-job-launcher-context.xml", "/jobs/skipSampleJob.xml" }) public class SkipSampleFunctionalTests { ... }
10.2 批处理作业的端到端测试
“端到端”测试可以定义为从头到尾测试批处理作业的完整运行。这样就可以进行测试,以设置测试条件,执行工作并验证最终结果。
在下面的示例中,批处理作业从数据库读取并写入平面文件。测试方法首先使用测试数据构建数据库。它将清除 CUSTOMER 表,然后插入 10 条新记录。然后,测试使用launchJob()方法启动Job。 launchJob()方法由JobLauncherTestUtils类提供。 utils 类还提供了launchJob(JobParameters),它允许测试提供特定的参数。 launchJob()方法返回JobExecution对象,该对象对于 assert 有关Job运行的特定信息很有用。在以下情况下,测试将验证Job以状态“ COMPLETED”结束。
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = { "/simple-job-launcher-context.xml",
"/jobs/skipSampleJob.xml" })
public class SkipSampleFunctionalTests {
@Autowired
private JobLauncherTestUtils jobLauncherTestUtils;
private SimpleJdbcTemplate simpleJdbcTemplate;
@Autowired
public void setDataSource(DataSource dataSource) {
this.simpleJdbcTemplate = new SimpleJdbcTemplate(dataSource);
}
@Test
public void testJob() throws Exception {
simpleJdbcTemplate.update("delete from CUSTOMER");
for (int i = 1; i <= 10; i++) {
simpleJdbcTemplate.update("insert into CUSTOMER values (?, 0, ?, 100000)",
i, "customer" + i);
}
JobExecution jobExecution = jobLauncherTestUtils.launchJob().getStatus();
Assert.assertEquals("COMPLETED", jobExecution.getExitStatus());
}
}
10.3 测试各个步骤
对于复杂的批处理作业,端到端测试方法中的测试用例可能变得难以 Management。在这些情况下,使用测试用例自行测试各个步骤可能会更有用。 AbstractJobTests类包含方法launchStep,该方法采用步骤名称并仅运行特定的Step。通过允许测试仅针对该步骤设置数据并直接验证其结果,该方法可以进行更具针对性的测试。
JobExecution jobExecution = jobLauncherTestUtils.launchStep("loadFileStep");
10.4 测试步骤范围的组件
通常,在运行时为您的步骤配置的组件会使用步骤作用域和后期绑定来从步骤或作业执行中注入上下文。将它们作为独立的组件进行测试非常棘手,除非您有一种将上下文设置为好像它们在一步执行中的方式。这就是 Spring Batch 中两个组件的目标:StepScopeTestExecutionListener和StepScopeTestUtils。
侦听器在类级别声明,其工作是为每个测试方法创建一个步骤执行上下文。例如:
@ContextConfiguration
@TestExecutionListeners( { DependencyInjectionTestExecutionListener.class,
StepScopeTestExecutionListener.class })
@RunWith(SpringJUnit4ClassRunner.class)
public class StepScopeTestExecutionListenerIntegrationTests {
// This component is defined step-scoped, so it cannot be injected unless
// a step is active...
@Autowired
private ItemReader<String> reader;
public StepExecution getStepExection() {
StepExecution execution = MetaDataInstanceFactory.createStepExecution();
execution.getExecutionContext().putString("input.data", "foo,bar,spam");
return execution;
}
@Test
public void testReader() {
// The reader is initialized and bound to the input data
assertNotNull(reader.read());
}
}
有两个TestExecutionListeners,一个来自常规 Spring Test 框架,并处理来自已配置的应用程序上下文的依赖项注入,从而注入读取器,另一个是 Spring Batch StepScopeTestExecutionListener。它通过在StepExecution的测试用例中查找工厂方法并将其用作测试方法的上下文来工作,就像该执行在运行时在 Step 中处于活动状态一样。 factory 方法通过其签名检测(它只需返回StepExecution)。如果未提供工厂方法,则会创建默认的StepExecution。
如果您希望步骤作用域的持续时间是测试方法的执行,则侦听器方法很方便。对于更灵活但更具侵入性的方法,您可以使用StepScopeTestUtils。例如,要计算上面的 Reader 中可用的 Item 数:
int count = StepScopeTestUtils.doInStepScope(stepExecution,
new Callable<Integer>() {
public Integer call() throws Exception {
int count = 0;
while (reader.read() != null) {
count++;
}
return count;
}
});
10.5 验证输出文件
当批处理作业写入数据库时,很容易查询数据库以验证输出是否符合预期。但是,如果批处理作业写入文件,则验证输出同样重要。 Spring Batch 提供了一个AssertFile类,以方便验证输出文件。方法assertFileEquals接受两个File对象(或两个Resource对象),并逐行 assert 两个文件具有相同的内容。因此,可以创建具有预期输出的文件并将其与实际结果进行比较:
private static final String EXPECTED_FILE = "src/main/resources/data/input.txt";
private static final String OUTPUT_FILE = "target/test-outputs/output.txt";
AssertFile.assertFileEquals(new FileSystemResource(EXPECTED_FILE),
new FileSystemResource(OUTPUT_FILE));
10.6 模拟域对象
在编写 Spring Batch 组件的单元测试和集成测试时遇到的另一个常见问题是如何模拟域对象。一个很好的例子是StepExecutionListener,如下所示:
public class NoWorkFoundStepExecutionListener extends StepExecutionListenerSupport {
public ExitStatus afterStep(StepExecution stepExecution) {
if (stepExecution.getReadCount() == 0) {
throw new NoWorkFoundException("Step has not processed any items");
}
return stepExecution.getExitStatus();
}
}
上面的侦听器由框架提供,并检查StepExecution的空读取计数,从而表示未完成任何工作。尽管这个示例非常简单,但是它用于说明尝试对实现需要 Spring Batch 域对象的接口的类进行单元测试时可能遇到的问题类型。考虑上面的侦听器的单元测试:
private NoWorkFoundStepExecutionListener tested = new NoWorkFoundStepExecutionListener();
@Test
public void testAfterStep() {
StepExecution stepExecution = new StepExecution("NoProcessingStep",
new JobExecution(new JobInstance(1L, new JobParameters(),
"NoProcessingJob")));
stepExecution.setReadCount(0);
try {
tested.afterStep(stepExecution);
fail();
} catch (NoWorkFoundException e) {
assertEquals("Step has not processed any items", e.getMessage());
}
}
由于 Spring Batch 域模型遵循良好的面向对象原则,因此 StepExecution 需要JobExecution,而后者需要JobInstance和JobParameters才能创建有效的StepExecution。尽管这在固态域模型中很好,但确实会使创建用于单元测试的存根对象变得冗长。为了解决这个问题,Spring Batch 测试模块包括一个用于创建域对象的工厂:MetaDataInstanceFactory。有了这个工厂,可以将单元测试更新为更简洁:
private NoWorkFoundStepExecutionListener tested = new NoWorkFoundStepExecutionListener();
@Test
public void testAfterStep() {
StepExecution stepExecution = MetaDataInstanceFactory.createStepExecution();
stepExecution.setReadCount(0);
try {
tested.afterStep(stepExecution);
fail();
} catch (NoWorkFoundException e) {
assertEquals("Step has not processed any items", e.getMessage());
}
}
上面创建简单StepExecution的方法只是工厂中可用的一种便捷方法。完整的方法列表可在其Javadoc中找到。
11. 常见批处理模式
一些批处理作业可以纯粹从 Spring Batch 中的现成组件中组装。例如,ItemReader和ItemWriter实现可以配置为涵盖各种场景。但是,在大多数情况下,必须编写自定义代码。应用程序开发人员的主要 API 入口点是Tasklet,ItemReader,ItemWriter和各种侦听器接口。大多数简单的批处理作业将能够使用 Spring Batch ItemReader的现成 Importing,但是在处理和编写过程中通常存在自定义问题,这要求开发人员实现ItemWriter或ItemProcessor。
在这里,我们提供了一些自定义业务逻辑中常见模式的示例。这些示例主要具有侦听器接口。应当注意,如果合适,ItemReader或ItemWriter也可以实现侦听器接口。
11.1 记录 Item 处理和失败
一个常见的用例是需要对步骤中的错误进行逐项的特殊处理,可能需要登录到特殊通道,或者将记录插入数据库。面向块的Step(从 step factory Bean 创建)允许用户使用简单的ItemReadListener(用于读取错误)和ItemWriteListener(用于写入错误)来实现此用例。以下代码段说明了一个记录读取和写入失败的侦听器:
public class ItemFailureLoggerListener extends ItemListenerSupport {
private static Log logger = LogFactory.getLog("item.error");
public void onReadError(Exception ex) {
logger.error("Encountered error on read", e);
}
public void onWriteError(Exception ex, Object item) {
logger.error("Encountered error on write", ex);
}
}
实现了此侦听器后,必须在以下步骤进行注册:
<step id="simpleStep">
...
<listeners>
<listener>
<bean class="org.example...ItemFailureLoggerListener"/>
</listener>
</listeners>
</step>
请记住,如果您的侦听器以onError()方法执行任何操作,则它将位于要回滚的事务内。如果需要在onError()方法内部使用事务性资源(例如数据库),请考虑向该方法添加声明性事务(有关详细信息,请参见《 Spring Core 参考指南》),并为其传播属性赋予值 REQUIRES_NEW。
11.2 由于业务原因手动停止作业
Spring Batch 通过JobLauncher接口提供了stop()方法,但这实际上是供操作员而非应用程序程序员使用的。有时从业务逻辑中停止作业执行更方便或更有意义。
最简单的方法是抛出RuntimeException(不会无限期重试或跳过的一次)。例如,可以使用自定义异常类型,如下例所示:
public class PoisonPillItemWriter implements ItemWriter<T> {
public void write(T item) throws Exception {
if (isPoisonPill(item)) {
throw new PoisonPillException("Poison pill detected: " + item);
}
}
}
停止执行步骤的另一种简单方法是从ItemReader返回null:
public class EarlyCompletionItemReader implements ItemReader<T> {
private ItemReader<T> delegate;
public void setDelegate(ItemReader<T> delegate) { ... }
public T read() throws Exception {
T item = delegate.read();
if (isEndItem(item)) {
return null; // end the step here
}
return item;
}
}
前面的示例实际上是基于CompletionPolicy策略的默认实现的,该默认实现在要处理的 Item 为 null 时发出完整批次的 signal。可以实施更复杂的完成策略,并通过SimpleStepFactoryBean注入Step:
<step id="simpleStep">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="10"
chunk-completion-policy="completionPolicy"/>
</tasklet>
</step>
<bean id="completionPolicy" class="org.example...SpecialCompletionPolicy"/>
另一种方法是在StepExecution中设置一个标志,该标志由 Item 处理之间的框架中的Step实现检查。要实现此替代方案,我们需要访问当前的StepExecution,这可以通过实现StepListener并将其注册到Step来实现。这是设置标志的侦听器的示例:
public class CustomItemWriter extends ItemListenerSupport implements StepListener {
private StepExecution stepExecution;
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
public void afterRead(Object item) {
if (isPoisonPill(item)) {
stepExecution.setTerminateOnly(true);
}
}
}
设置标志时,此处的默认行为是抛出JobInterruptedException的步骤。可以通过StepInterruptionPolicy进行控制,但是唯一的选择是引发或不引发异常,因此这始终是工作的异常结束。
11.3 添加页脚记录
通常,在写入平面文件时,在完成所有处理后,必须在文件末尾附加“页脚”记录。这也可以使用 Spring Batch 提供的FlatFileFooterCallback接口来实现。 FlatFileFooterCallback(及其对应的FlatFileHeaderCallback)是FlatFileItemWriter的可选属性:
<bean id="itemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator" ref="lineAggregator"/>
<property name="headerCallback" ref="headerCallback" />
<property name="footerCallback" ref="footerCallback" />
</bean>
页脚回调接口非常简单。当必须编写页脚时,只有一种方法被调用:
public interface FlatFileFooterCallback {
void writeFooter(Writer writer) throws IOException;
}
11.3.1 编写摘要页脚
涉及页脚记录的一个非常常见的要求是在输出过程中汇总信息,并将此信息附加到文件末尾。此页脚用作文件摘要或提供校验和。
例如,如果批处理作业将Trade记录写入平面文件,并且要求将所有Trade的总数放在页脚中,则可以使用以下ItemWriter实现:
public class TradeItemWriter implements ItemWriter<Trade>,
FlatFileFooterCallback {
private ItemWriter<Trade> delegate;
private BigDecimal totalAmount = BigDecimal.ZERO;
public void write(List<? extends Trade> items) {
BigDecimal chunkTotal = BigDecimal.ZERO;
for (Trade trade : items) {
chunkTotal = chunkTotal.add(trade.getAmount());
}
delegate.write(items);
// After successfully writing all items
totalAmount = totalAmount.add(chunkTotal);
}
public void writeFooter(Writer writer) throws IOException {
writer.write("Total Amount Processed: " + totalAmount);
}
public void setDelegate(ItemWriter delegate) {...}
}
此TradeItemWriter存储一个totalAmount值,该值随每个写入的Trade项中的amount增加。在处理最后一个Trade之后,框架将调用writeFooter,这会将totalAmount放入文件中。请注意,write方法使用了临时变量chunkTotalAmount,该临时变量将事务总数存储在块中。这样做是为了确保如果write方法中发生跳过,totalAmount 将保持不变。只有在write方法的末尾,一旦我们保证不会引发任何异常,就可以更新totalAmount。
为了调用writeFooter方法,必须将TradeItemWriter(实现FlatFileFooterCallback)作为footerCallback连接到FlatFileItemWriter:
<bean id="tradeItemWriter" class="..TradeItemWriter">
<property name="delegate" ref="flatFileItemWriter" />
</bean>
<bean id="flatFileItemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator" ref="lineAggregator"/>
<property name="footerCallback" ref="tradeItemWriter" />
</bean>
到目前为止TradeItemWriter的运行方式只有在Step无法重新启动时才能正常运行。这是因为该类是有状态的(因为它存储了totalAmount),但是totalAmount没有持久化到数据库中,因此,在重新启动的情况下无法检索到它。为了使此类可以重新启动,应将ItemStream接口与方法open和update一起实现:
public void open(ExecutionContext executionContext) {
if (executionContext.containsKey("total.amount") {
totalAmount = (BigDecimal) executionContext.get("total.amount");
}
}
public void update(ExecutionContext executionContext) {
executionContext.put("total.amount", totalAmount);
}
update方法会将totalAmount的最新版本存储到ExecutionContext,直到该对象被持久存储到数据库中。 open方法将从ExecutionContext中检索任何现有的totalAmount并将其用作处理的起点,从而允许TradeItemWriter在重新启动时重新启动,而上一次执行Step时它已停止。
11.4 驱动基于查询的 ItemReader
在有关读写器的章节中,讨论了使用分页的数据库 Importing。许多数据库供应商,例如 DB2,都具有极其悲观的锁定策略,如果正在读取的表也需要由联机应用程序的其他部分使用,则会导致问题。此外,在非常大的数据集上打开游标可能会导致某些供应商出现问题。因此,许多 Item 更喜欢使用“驱动查询”方法来读取数据。这种方法的工作方式是遍历键,而不是遍历需要返回的整个对象,如以下示例所示:
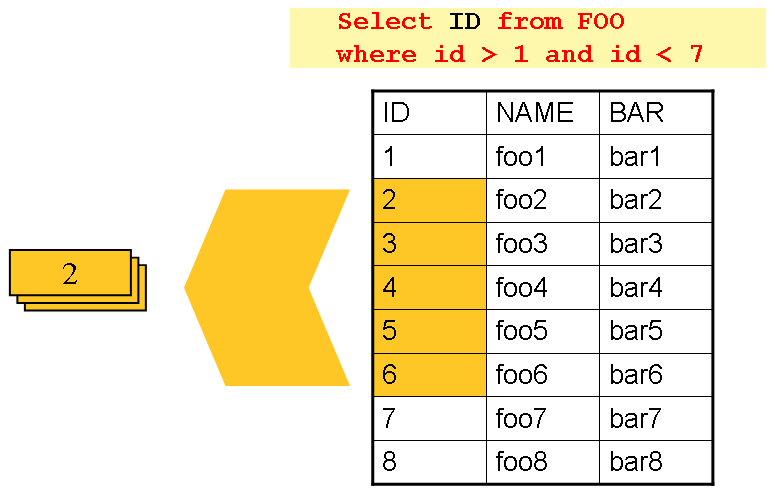
如您所见,该示例使用与基于游标的示例相同的“ FOO”表。但是,不是选择整个行,而是在 SQL 语句中仅选择了 ID。因此,不是从read返回 FOO 对象,而是将返回 Integer。然后可以使用该数字查询“详细信息”,它是完整的 Foo 对象:
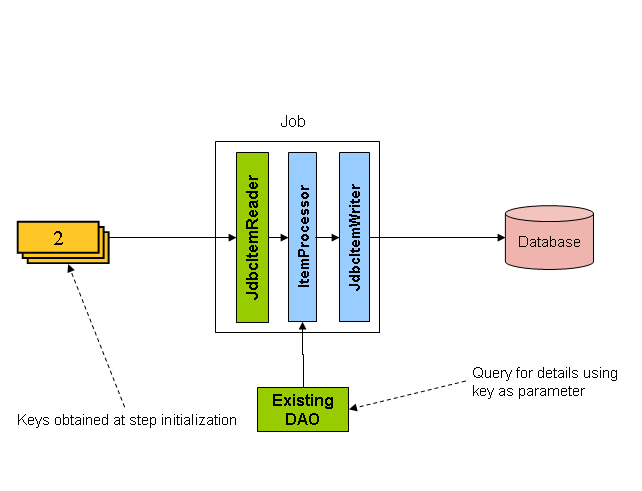
应该使用 ItemProcessor 将从驾驶查询中获得的键转换为完整的“ Foo”对象。现有的 DAO 可以用于根据密钥查询完整的对象。
11.5 多行记录
通常在平面文件中,每条记录只限于一行,但通常情况下,一个文件中的记录可能会跨越多种格式的多行。以下文件摘录对此进行了说明:
HEA;0013100345;2007-02-15
NCU;Smith;Peter;;T;20014539;F
BAD;;Oak Street 31/A;;Small Town;00235;IL;US
FOT;2;2;267.34
以“ HEA”开头的行和以“ FOT”开头的行之间的所有内容均被视为一条记录。为了正确处理此情况,必须考虑以下几点:
ItemReader不能一次读取一个记录,而必须将多行记录的每一行作为一个组读取,以便可以将其完整地传递给ItemWriter。- 每种线型可能需要不同地标记。
由于一条记录跨越多行,而且我们可能不知道有多少行,因此ItemReader必须小心以始终读取整个记录。为此,应实现自定义ItemReader作为FlatFileItemReader的包装。
<bean id="itemReader" class="org.spr...MultiLineTradeItemReader">
<property name="delegate">
<bean class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="data/iosample/input/multiLine.txt" />
<property name="lineMapper">
<bean class="org.spr...DefaultLineMapper">
<property name="lineTokenizer" ref="orderFileTokenizer"/>
<property name="fieldSetMapper">
<bean class="org.spr...PassThroughFieldSetMapper" />
</property>
</bean>
</property>
</bean>
</property>
</bean>
为了确保正确标记每行,这对于固定长度的 Importing 尤其重要,可以在委托FlatFileItemReader上使用PatternMatchingCompositeLineTokenizer。有关更多详细信息,请参见称为“单个文件中的多种记录类型”的部分。然后,委托 Reader 将使用PassThroughFieldSetMapper将每行的FieldSet传递回包装ItemReader。
<bean id="orderFileTokenizer" class="org.spr...PatternMatchingCompositeLineTokenizer">
<property name="tokenizers">
<map>
<entry key="HEA*" value-ref="headerRecordTokenizer" />
<entry key="FOT*" value-ref="footerRecordTokenizer" />
<entry key="NCU*" value-ref="customerLineTokenizer" />
<entry key="BAD*" value-ref="billingAddressLineTokenizer" />
</map>
</property>
</bean>
该包装程序必须能够识别记录的结尾,以便它可以连续地对其委托调用read()直到到达结尾。对于读取的每一行,包装器应构建要返回的 Item。到达页脚后,可以将商品退回以交付给ItemProcessor和ItemWriter。
private FlatFileItemReader<FieldSet> delegate;
public Trade read() throws Exception {
Trade t = null;
for (FieldSet line = null; (line = this.delegate.read()) != null;) {
String prefix = line.readString(0);
if (prefix.equals("HEA")) {
t = new Trade(); // Record must start with header
}
else if (prefix.equals("NCU")) {
Assert.notNull(t, "No header was found.");
t.setLast(line.readString(1));
t.setFirst(line.readString(2));
...
}
else if (prefix.equals("BAD")) {
Assert.notNull(t, "No header was found.");
t.setCity(line.readString(4));
t.setState(line.readString(6));
...
}
else if (prefix.equals("FOT")) {
return t; // Record must end with footer
}
}
Assert.isNull(t, "No 'END' was found.");
return null;
}
11.6 执行系统命令
许多批处理作业可能需要从批处理作业中调用外部命令。调度程序可以单独启动此过程,但是有关运行的通用元数据的优势将丢失。此外,也需要将多步骤作业拆分为多个作业。
由于这种需求非常普遍,因此 Spring Batch 提供了Tasklet实现来调用系统命令:
<bean class="org.springframework.batch.core.step.tasklet.SystemCommandTasklet">
<property name="command" value="echo hello" />
<!-- 5 second timeout for the command to complete -->
<property name="timeout" value="5000" />
</bean>
11.7 未找到 Importing 时的处理步骤完成
在许多批处理方案中,在数据库或文件中找不到要处理的行并不是 exception。 Step仅被视为未找到任何工作,并完成了 0 项读取。 Spring Batch 中提供的所有ItemReader实现都是默认使用此方法。如果即使有 Importing 也没有写出任何内容,这可能会导致混乱。 (通常是在文件名错误的情况下发生,等等)。因此,应检查元数据本身,以确定框架将要处理的工作量。但是,如果找不到任何 Importing 被认为是 exceptions 怎么办?在这种情况下,以编程方式检查元数据中是否有未处理的 Item 并导致失败是最好的解决方案。因为这是一个常见的用例,所以仅向侦听器提供此功能:
public class NoWorkFoundStepExecutionListener extends StepExecutionListenerSupport {
public ExitStatus afterStep(StepExecution stepExecution) {
if (stepExecution.getReadCount() == 0) {
return ExitStatus.FAILED;
}
return null;
}
}
上面的StepExecutionListener在“后续步骤”阶段检查StepExecution的 readCount 属性,以确定是否未读取任何 Item。在这种情况下,将返回退出代码 FAILED,表明Step应该失败。否则,将返回 null,这不会影响Step的状态。
11.8 将数据传递到将来的步骤
将信息从一个步骤传递到另一步骤通常很有用。可以使用ExecutionContext完成。要注意的是,有两个ExecutionContext:一个在Step级别,一个在Job级别。 Step ExecutionContext的寿命仅与台阶一样长,而Job ExecutionContext的寿命贯穿整个Job。另一方面,每次Step提交一个块时Step ExecutionContext被更新,而Job ExecutionContext仅在每个Step的末尾被更新。
这种分离的结果是在执行Step时必须将所有数据都放在Step ExecutionContext中。这将确保在Step持续进行期间正确存储数据。如果将数据存储到Job ExecutionContext,则在Step执行期间将不会保留该数据,并且如果Step失败,则该数据将丢失。
public class SavingItemWriter implements ItemWriter<Object> {
private StepExecution stepExecution;
public void write(List<? extends Object> items) throws Exception {
// ...
ExecutionContext stepContext = this.stepExecution.getExecutionContext();
stepContext.put("someKey", someObject);
}
@BeforeStep
public void saveStepExecution(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
}
为了使数据对将来的Step可用,必须在完成该步骤之后将其“提升”到Job ExecutionContext。 Spring Batch 为此提供了ExecutionContextPromotionListener。必须为侦听器配置与必须提升的ExecutionContext中的数据相关的键。还可以选择为其配置升级的退出代码模式列表(默认为“ COMPLETED”)。与所有侦听器一样,它必须在Step上注册。
<job id="job1">
<step id="step1">
<tasklet>
<chunk reader="reader" writer="savingWriter" commit-interval="10"/>
</tasklet>
<listeners>
<listener ref="promotionListener"/>
</listeners>
</step>
<step id="step2">
...
</step>
</job>
<beans:bean id="promotionListener" class="org.spr....ExecutionContextPromotionListener">
<beans:property name="keys" value="someKey"/>
</beans:bean>
最后,必须从Job ExeuctionContext检索保存的值:
public class RetrievingItemWriter implements ItemWriter<Object> {
private Object someObject;
public void write(List<? extends Object> items) throws Exception {
// ...
}
@BeforeStep
public void retrieveInterstepData(StepExecution stepExecution) {
JobExecution jobExecution = stepExecution.getJobExecution();
ExecutionContext jobContext = jobExecution.getExecutionContext();
this.someObject = jobContext.get("someKey");
}
}
| Name | Spring Batch 中文文档 |
|---|---|
| Version | 3.0.x 4.1.x |
| Language | English 中文 |
| Badge |  |
| Last Updated | 2021-09-27T13:20:25 |
12. JSR-352 Support
从 Spring Batch 3.0 开始,已经完全实现了对 JSR-352 的支持。本部分不是规范本身的替代,而是打算解释 JSR-352 特定概念如何应用于 Spring Batch。有关 JSR-352 的其他信息,可以通过 JCP 在这里找到:https://jcp.org/en/jsr/detail?id=352
12.1 一般说明 Spring Batch 和 JSR-352
Spring Batch 和 JSR-352 在结构上相同。他们俩的工作都是由步骤组成的。他们都有阅 Reader,处理者,Writer 和 Listener。但是,它们之间的交互作用略有不同。例如,Spring Batch 中的org.springframework.batch.core.SkipListener#onSkipInWrite(S item, Throwable t)接收两个参数:被跳过的 Item 和导致跳过的异常。相同方法(javax.batch.api.chunk.listener.SkipWriteListener#onSkipWriteItem(List<Object> items, Exception ex))的 JSR-352 版本也接收两个参数。但是,第一个是当前块中所有 Item 的List,第二个是导致跳过的Exception。由于存在这些差异,因此需要特别注意的是,在 Spring Batch 中有两种执行作业的路径:传统的 Spring Batch 作业或基于 JSR-352 的作业。尽管使用 Spring Batch 工件(读取器,写入器等)将在通过 JSR-352 的 JSL 配置并通过JsrJobOperator执行的作业中工作,但它们将按照 JSR-352 的规则运行。还需要注意的是,针对 JSR-352 接口开发的批处理工件将无法在传统的 Spring Batch 作业中使用。
12.2 Setup
12.2.1 应用程序上下文
Spring Batch 中所有基于 JSR-352 的作业均包含两个应用程序上下文。一个父上下文,其中包含与 Spring Batch 基础结构(如JobRepository,PlatformTransactionManager等)相关的 bean,以及一个子上下文,该子上下文包含要运行的作业的配置。父上下文是通过框架提供的baseContext.xml定义的。可以通过JSR-352-BASE-CONTEXT系统属性覆盖此上下文。
Note
JSR-352 处理器不对基本上下文进行诸如属性注入之类的处理,因此不需要在其中配置任何需要额外处理的组件。
12.2.2 启动基于 JSR-352 的作业
JSR-352 需要执行批处理作业的非常简单的路径。以下代码是执行第一个批处理作业所需的全部:
JobOperator operator = BatchRuntime.getJobOperator();
jobOperator.start("myJob", new Properties());
虽然这对开发人员很方便,但细节在于魔鬼。 Spring Batch 在开发人员可能想覆盖的幕后引导了一些基础架构。以下是首次调用BatchRuntime.getJobOperator()时的引导程序:
| Bean Name | Default Configuration | Notes |
|---|---|---|
| dataSource | 具有配置值的 Apache DBCP BasicDataSource。 | 默认情况下,HSQLDB 被引导。 |
transactionManager |
org.springframework.jdbc.datasource.DataSourceTransactionManager |
引用上面定义的 dataSource bean。 |
| 数据源初始化器 | 它被配置为执行通过batch.drop.script和batch.schema.script属性配置的脚本。默认情况下,将执行 HSQLDB 的架构脚本。可以通过batch.data.source.init属性禁用此行为。 |
|
| jobRepository | 基于 JDBC 的SimpleJobRepository。 |
JobRepository使用前面提到的数据源和事务 Management 器。可通过batch.table.prefix属性配置模式的表前缀(默认为 BATCH_)。 |
| jobLauncher | org.springframework.batch.core.launch.support.SimpleJobLauncher |
用于启动工作。 |
| batchJobOperator | org.springframework.batch.core.launch.support.SimpleJobOperator |
JsrJobOperator对此进行了包装,以提供其大部分功能。 |
| jobExplorer | org.springframework.batch.core.explore.support.JobExplorerFactoryBean |
用于解决JsrJobOperator提供的查找功能。 |
| jobParametersConverter | org.springframework.batch.core.jsr.JsrJobParametersConverter |
JSR-352 的具体实现JobParametersConverter。 |
| jobRegistry | org.springframework.batch.core.configuration.support.MapJobRegistry |
由SimpleJobOperator使用。 |
| placeholderProperties | org.springframework.beans.factory.config.PropertyPlaceholderConfigure |
加载属性文件batch-${ENVIRONMENT:hsql}.properties以配置上述属性。 ENVIRONMENT 是一个系统属性(默认为 hsql),可用于指定 Spring Batch 当前支持的任何受支持数据库。 |
Note
对于执行基于 JSR-352 的作业,上述所有 bean 都不是可选的。所有这些都可以覆盖以根据需要提供自定义功能。
12.3 依赖注入
JSR-352 很大程度上基于 Spring Batch 编程模型。这样,虽然没有明确要求正式的依赖注入实现,但暗含了某种形式的 DI。 Spring Batch 支持三种用于加载由 JSR-352 定义的批处理工件的方法:
- 特定于实现的加载器-Spring Batch 是基于 Spring 构建的,因此支持 JSR-352 批处理作业中的 Spring 依赖项注入。
- 存档加载器-JSR-352 定义了现成的 batch.xml 文件,该文件提供了逻辑名和类名之间的 Map。如果使用此文件,则必须在/ META-INF /目录中找到该文件。
- 线程上下文类加载器-JSR-352 允许配置通过内联提供完全限定的类名来在其 JSL 中指定批处理工件实现。 Spring Batch 在 JSR-352 配置的作业中也支持此功能。
在基于 JSR-352 的批处理作业中使用 Spring 依赖项注入包括使用 Spring 应用程序上下文作为 bean 配置批处理工件。一旦定义了 bean,作业就可以引用它们,就像在 batch.xml 中定义的任何 bean 一样。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://xmlns.jcp.org/xml/ns/javaee
http://xmlns.jcp.org/xml/ns/javaee/jobXML_1_0.xsd">
<!-- javax.batch.api.Batchlet implementation -->
<bean id="fooBatchlet" class="io.spring.FooBatchlet">
<property name="prop" value="bar"/>
</bean>
<!-- Job is defined using the JSL schema provided in JSR-352 -->
<job id="fooJob" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="step1">
<batchlet ref="fooBatchlet"/>
</step>
</job>
</beans>
Spring 上下文的组装(导入等)可与 JSR-352 作业一起使用,就像与任何其他基于 Spring 的应用程序一样。与基于 JSR-352 的作业的唯一区别是,上下文定义的入口点将是在/ META-INF/batch-jobs /中找到的作业定义。
要使用线程上下文类加载器方法,您需要做的就是提供完全限定的类名作为 ref。重要的是要注意,当使用这种方法或 batch.xml 方法时,所引用的类需要一个无参数构造函数,该构造函数将用于创建 bean。
<?xml version="1.0" encoding="UTF-8"?>
<job id="fooJob" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="step1" >
<batchlet ref="io.spring.FooBatchlet" />
</step>
</job>
12.4 批处理属性
12.4.1 财产支持
JSR-352 允许通过 JSL 中的配置在 Job,Step 和 Batch 工件级别上定义属性。批处理属性通过以下方式在每个级别上配置:
<properties>
<property name="propertyName1" value="propertyValue1"/>
<property name="propertyName2" value="propertyValue2"/>
</properties>
可以在任何批处理工件上配置属性。
12.4.2 @BatchProperty 注解
通过使用@BatchProperty和@Inject注解对类字段进行注解,批处理工件中引用了属性(规范要求这两个注解)。根据 JSR-352 的定义,属性的字段必须为 String 类型。任何类型的转换都由实施开发人员来执行。
javax.batch.api.chunk.ItemReader工件可以配置一个属性块,例如上述的属性块,并按以下方式访问:
public class MyItemReader extends AbstractItemReader {
@Inject
@BatchProperty
private String propertyName1;
...
}
字段“ propertyName1”的值将为“ propertyValue1”
12.4.3 财产替代
通过操作符和简单的条件表达式提供属性替换。一般用法是#\ {operator[‘key’]}。
Supported operators:
- jobParameters-访问启动/重新启动作业的作业参数值。
- jobProperties-访问在 JSL 的作业级别配置的属性。
- systemProperties-访问命名的系统属性。
partitionPlan-从分区步骤的分区计划中访问命名属性。
#{jobParameters['unresolving.prop']}?:#{systemProperties['file.separator']}
分配的左侧是期望值,右侧是默认值。在此示例中,结果将解析为系统属性 file.separator 的值,因为假定#\ {jobParameters[‘unresolving.prop’]}不可解析。如果两个表达式都无法解析,则将返回一个空的 String。可以使用多个条件,以“;”分隔。
12.5 处理模型
JSR-352 提供了与 Spring Batch 相同的两个基本处理模型:
- 基于 Item 的处理-使用
javax.batch.api.chunk.ItemReader,可选javax.batch.api.chunk.ItemProcessor和javax.batch.api.chunk.ItemWriter。 - 基于任务的处理-使用
javax.batch.api.Batchlet实现。此处理模型与当前可用的基于org.springframework.batch.core.step.tasklet.Tasklet的处理相同。
12.5.1 基于 Item 的处理
在这种情况下,基于 Item 的处理是由ItemReader读取的 Item 数设置的块大小。要以这种方式配置步骤,请指定item-count(默认值为 10),并可以选择将checkpoint-policy配置为 Item(默认值)。
...
<step id="step1">
<chunk checkpoint-policy="item" item-count="3">
<reader ref="fooReader"/>
<processor ref="fooProcessor"/>
<writer ref="fooWriter"/>
</chunk>
</step>
...
如果选择了基于 Item 的检查点,则支持附加属性time-limit。这为必须处理指定的 Item 数设置了时间限制。如果达到了超时,那么无论item-count被配置为什么,块都将完成,但是届时将读取许多项。
12.5.2 自定义检查点
JSR-352 在“检查点”步骤内在提交间隔附近调用该过程。如上所述,基于 Item 的检查点是一种方法。但是,这在许多情况下不够鲁棒。因此,该规范允许通过实现javax.batch.api.chunk.CheckpointAlgorithm接口来实现自定义检查点算法。该功能在功能上与 Spring Batch 的自定义完成策略相同。要使用CheckpointAlgorithm的实现,请使用自定义checkpoint-policy配置您的步骤,如下所示,其中 fooCheckpointer 引用CheckpointAlgorithm的实现。
...
<step id="step1">
<chunk checkpoint-policy="custom">
<checkpoint-algorithm ref="fooCheckpointer"/>
<reader ref="fooReader"/>
<processor ref="fooProcessor"/>
<writer ref="fooWriter"/>
</chunk>
</step>
...
12.6 执行工作
通过javax.batch.operations.JobOperator可以执行基于 JSR-352 的作业。 Spring Batch 为此接口(org.springframework.batch.core.jsr.launch.JsrJobOperator)提供了我们自己的实现。此实现是通过javax.batch.runtime.BatchRuntime加载的。启动基于 JSR-352 的批处理作业的实现如下:
JobOperator jobOperator = BatchRuntime.getJobOperator();
long jobExecutionId = jobOperator.start("fooJob", new Properties());
上面的代码执行以下操作:
- 引导基本的 ApplicationContext-为了提供批处理功能,框架需要引导一些基础结构。每个 JVM 发生一次。引导的组件与
@EnableBatchProcessing提供的组件类似。具体细节可以在JsrJobOperator的 javadoc 中找到。 - 为请求的作业加载
ApplicationContext-在上面的示例中,框架将在/ META-INF/batch-jobs 中查找名为 fooJob.xml 的文件,并加载一个上下文,该上下文是前面提到的共享上下文的子级。 - 启动作业-在上下文中定义的作业将异步执行。
JobExecution的 ID 将返回。
Note
所有基于 JSR-352 的批处理作业均异步执行。
当使用SimpleJobOperator调用JobOperator#start时,Spring Batch 将确定该调用是初始运行还是重试先前执行的运行。使用基于 JSR-352 的JobOpeator#start(String jobXMLName, Properties jobParameters),框架将始终创建一个新的JobInstance(JSR-352 作业参数无法识别)。为了重新启动作业,需要调用JobOperator#restart(long executionId, Properties restartParameters)。
12.7 Contexts
JSR-352 定义了两个上下文对象,它们用于与批处理工件中的作业或步骤的元数据进行交互:javax.batch.runtime.context.JobContext和javax.batch.runtime.context.StepContext。两者都可以在任何步骤级别的工件(Batchlet,ItemReader等)中使用,而JobContext也可用于作业级别的工件(例如JobListener)。
要获得对当前范围内的JobContext或StepContext的引用,只需使用@Inject注解:
@Inject
JobContext jobContext;
Note
这些上下文的注入不支持使用 Spring 的@Autowire。
在 Spring Batch 中,JobContext和StepContext包装了它们相应的执行对象(分别为JobExecution和StepExecution)。通过StepContext#persistent#setPersistentUserData(Serializable data)存储的数据存储在 Spring Batch StepExecution#executionContext中。
12.8 步骤流程
在基于 JSR-352 的作业中,步骤流程的工作原理与 Spring Batch 中的步骤相似。但是,有一些细微的差异:
- 决策就是步骤-在常规的 Spring Batch 工作中,决策是没有独立的
StepExecution或没有完整步骤所伴随的任何权利和责任的状态。但是,对于 JSR-352,决策是与其他任何步骤一样,其行为也将与其他任何步骤一样(可 Transactional,它得到StepExecution等)。这意味着它们也与其他任何重新启动步骤一样。 next属性和步骤过渡-在常规作业中,允许它们在同一步骤中一起出现。 JSR-352 允许它们在同一步骤中使用,并且下一个属性在评估中优先使用。- 过渡元素排序-在标准 Spring Batch 作业中,过渡元素从最具体到最不具体排序,并按该 Sequences 进行评估。 JSR-352 作业按照 XML 中指定的 Sequences 评估过渡元素。
12.9 扩展 JSR-352 批处理作业
传统的 Spring Batch 作业具有四种扩展方式(后两种可以跨多个 JVM 执行):
- 拆分-并行运行多个步骤。
- 多线程-通过多线程执行单个步骤。
- 分区-划分数据以进行并行处理(主/从)。
- 远程分块-远程执行处理器逻辑。
JSR-352 提供了两个用于扩展批处理作业的选项。这两个选项仅支持单个 JVM:
- 拆分-与 Spring Batch 相同
- 分区-从概念上讲与 Spring Batch 相同,但是实现方面略有不同。
12.9.1 Partitioning
从概念上讲,JSR-352 中的分区与 Spring Batch 中的分区相同。元数据提供给每个从属设备,以标识要处理的 Importing,从属设备在完成后将结果报告给主设备。但是,有一些重要的区别:
- 已分区
Batchlet-这将在多个线程上运行已配置Batchlet的多个实例。每个实例将具有由 JSL 或PartitionPlan提供的自己的一组属性。 PartitionPlan-使用 Spring Batch 的分区,为每个分区提供ExecutionContext。对于 JSR-352,将为单个javax.batch.api.partition.PartitionPlan提供一个Properties数组,以提供每个分区的元数据。PartitionMapper-JSR-352 提供了两种生成分区元数据的方式。一种是通过 JSL(分区属性)。第二个是通过javax.batch.api.partition.PartitionMapper接口的实现。从功能上讲,该接口类似于 Spring Batch 提供的org.springframework.batch.core.partition.support.Partitioner接口,因为它提供了一种以编程方式生成用于分区的元数据的方法。StepExecutions-在 Spring Batch 中,分区步骤以主/从身份运行。在 JSR-352 中,会发生相同的配置。但是,从属步骤未获得官方StepExecutions。因此,对JsrJobOperator#getStepExecutions(long jobExecutionId)的调用只会为主机返回StepExecution。
Note
子StepExecution仍然存在于作业存储库中,可以通过JobExplorer和 Spring Batch Admin 使用。
- 补偿逻辑-由于 Spring Batch 使用步骤实现分区的主/从逻辑,因此如果出现问题,可以使用
StepExecutionListeners 处理补偿逻辑。但是,由于从站 JSR-352 提供了其他组件的集合,因此能够在发生错误时提供补偿逻辑并动态设置退出状态。这些组件包括:
| Artifact Interface | Description |
|---|---|
javax.batch.api.partition.PartitionCollector |
提供一种用于从属步骤将信息发送回主控方的方法。每个从属线程有一个实例。 |
javax.batch.api.partition.PartitionAnalyzer |
端点,该端点接收PartitionCollector收集的信息以及来自已完成分区的结果状态。 |
javax.batch.api.partition.PartitionReducer |
提供为分区步骤提供补偿逻辑的功能。 |
12.10 Testing
由于所有基于 JSR-352 的作业都是异步执行的,因此很难确定作业何时完成。为了帮助测试,Spring Batch 提供了org.springframework.batch.core.jsr.JsrTestUtils。该 Util 类提供了启动作业,重新启动作业并 await 其完成的功能。作业完成后,将返回关联的JobExecution。
13. Spring 批处理集成
13.1. Spring Batch 集成介绍
Spring Batch 的许多用户可能会遇到超出 Spring Batch 范围的要求,但可以使用 Spring Integration 来高效,简洁地实现。相反,Spring Batch 用户可能会遇到 Spring Batch 要求,并需要一种有效地集成两个框架的方法。在这种情况下,出现了几种模式和用例,Spring Batch Integration 将解决这些需求。
Spring Batch 和 Spring Integration 之间的界线并不总是很清楚,但是有些准则可以遵循。原则上,这些是:考虑粒度,并应用通用模式。这些常见模式中的一些在本参考手册部分中进行了描述。
将消息添加到批处理过程中,可以实现自动化操作,还可以对关键问题进行分离和制定策略。例如,一条消息可能触发作业执行,然后可以通过多种方式公开消息的发送。或者,当作业完成或失败时,可能会触发消息发送,而这些消息的使用者可能会遇到与应用程序本身无关的操作问题。消息传递也可以嵌入到作业中,例如读取或写入要通过通道进行处理的 Item。远程分区和远程分块提供了在多个工作人员上分配工作负载的方法。
我们将介绍的一些关键概念是:
13.1.1. 命名空间支持
从 Spring Batch Integration 1.3 开始,添加了专用的 XML 命名空间支持,目的是提供更轻松的配置体验。为了激活名称空间,请将以下名称空间声明添加到您的 Spring XML Application Context 文件中:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch-int="http://www.springframework.org/schema/batch-integration"
xsi:schemaLocation="
http://www.springframework.org/schema/batch-integration
http://www.springframework.org/schema/batch-integration/spring-batch-integration.xsd">
...
</beans>
完整配置的用于 Spring Batch Integration 的 Spring XML Application Context 文件可能如下所示:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:int="http://www.springframework.org/schema/integration"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:batch-int="http://www.springframework.org/schema/batch-integration"
xsi:schemaLocation="
http://www.springframework.org/schema/batch-integration
http://www.springframework.org/schema/batch-integration/spring-batch-integration.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd">
...
</beans>
也允许将版本号附加到引用的 XSD 文件中,但是由于无版本声明将始终使用最新的架构,因此我们通常不建议将版本号附加到 XSD 名称中。例如,添加版本号可能会在更新 Spring Batch Integration 依赖项时产生问题,因为它们可能需要 XML 模式的最新版本。
13.1.2. 通过消息启动批处理作业
使用核心 Spring Batch API 启动批处理作业时,您基本上有 2 个选择:
- 通过
CommandLineJobRunner的命令行 - 通过
JobOperator.start()或JobLauncher.run()编程。
例如,当您使用 Shell 脚本调用批处理作业时,可能要使用CommandLineJobRunner。或者,您可以直接使用JobOperator,例如,在将 Spring Batch 用作 Web 应用程序的一部分时。但是,如何处理更复杂的用例呢?也许您需要轮询远程(S)FTP 服务器以检索批处理作业的数据。或者您的应用程序必须同时支持多个不同的数据源。例如,您不仅可以通过 Web 接收数据文件,还可以通过 FTP 接收数据文件。也许在调用 Spring Batch 之前需要对 Importing 文件进行其他转换。
因此,使用 Spring Integration 及其众多适配器来执行批处理作业将更加强大。例如,您可以使用*文件入站通道适配器*监视文件系统中的目录,并在 Importing 文件到达后立即启动批处理作业。另外,您可以创建使用多个不同适配器的 Spring Integration 流,仅使用配置即可轻松地同时从多个源中获取批处理作业的数据。使用 Spring Integration 轻松实现所有这些场景,因为它允许事件驱动的JobLauncher解耦执行。
Spring Batch Integration 提供了JobLaunchingMessageHandler类,可用于启动批处理作业。 JobLaunchingMessageHandler的 Importing 由 Spring Integration 消息提供,其有效载荷类型为JobLaunchRequest。该类是需要启动的 Job 的包装,以及启动 Batch 作业所需的JobParameters。
下图说明了用于启动批处理作业的典型 Spring Integration 消息流。 EIP(企业集成模式)网站提供了消息图标及其描述的完整概述。
将文件转换为 JobLaunchRequest
package io.spring.sbi;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.integration.launch.JobLaunchRequest;
import org.springframework.integration.annotation.Transformer;
import org.springframework.messaging.Message;
import java.io.File;
public class FileMessageToJobRequest {
private Job job;
private String fileParameterName;
public void setFileParameterName(String fileParameterName) {
this.fileParameterName = fileParameterName;
}
public void setJob(Job job) {
this.job = job;
}
@Transformer
public JobLaunchRequest toRequest(Message<File> message) {
JobParametersBuilder jobParametersBuilder =
new JobParametersBuilder();
jobParametersBuilder.addString(fileParameterName,
message.getPayload().getAbsolutePath());
return new JobLaunchRequest(job, jobParametersBuilder.toJobParameters());
}
}
JobExecution 响应
执行批处理作业时,将返回JobExecution实例。该实例可用于确定执行状态。如果能够成功创建JobExecution,则无论实际执行是否成功,都将始终返回它。
如何返回JobExecution实例的确切行为取决于所提供的TaskExecutor。如果使用synchronous(单线程)TaskExecutor实现,则仅在after作业完成时返回JobExecution响应。使用asynchronous TaskExecutor时,会立即返回JobExecution实例。然后,用户可以使用JobExecution实例(JobExecution.getJobId())的id并使用JobExplorer向JobRepository查询作业的更新状态。有关更多信息,请参阅查询存储库上的Spring Batch参考文档。
以下配置将在提供的目录中创建文件inbound-channel-adapter来侦听 CSV 文件,将其交给我们的转换器(FileMessageToJobRequest),通过* Job Launching Gateway *启动作业,然后只需通过logging-channel-adapter记录JobExecution的输出。
Spring Batch 集成配置
<int:channel id="inboundFileChannel"/>
<int:channel id="outboundJobRequestChannel"/>
<int:channel id="jobLaunchReplyChannel"/>
<int-file:inbound-channel-adapter id="filePoller"
channel="inboundFileChannel"
directory="file:/tmp/myfiles/"
filename-pattern="*.csv">
<int:poller fixed-rate="1000"/>
</int-file:inbound-channel-adapter>
<int:transformer input-channel="inboundFileChannel"
output-channel="outboundJobRequestChannel">
<bean class="io.spring.sbi.FileMessageToJobRequest">
<property name="job" ref="personJob"/>
<property name="fileParameterName" value="input.file.name"/>
</bean>
</int:transformer>
<batch-int:job-launching-gateway request-channel="outboundJobRequestChannel"
reply-channel="jobLaunchReplyChannel"/>
<int:logging-channel-adapter channel="jobLaunchReplyChannel"/>
现在我们正在轮询文件并启动作业,我们需要配置例如 Spring Batch ItemReader以利用由作业参数“ input.file.name”表示的找到的文件:
ItemReader 配置示例
<bean id="itemReader" class="org.springframework.batch.item.file.FlatFileItemReader"
scope="step">
<property name="resource" value="file://#{jobParameters['input.file.name']}"/>
...
</bean>
这里的主要兴趣点是将#{jobParameters['input.file.name']}的值注入为 Resource 属性值,并将 ItemReader bean 设置为* Step scope *以利用后期绑定支持的优势,该支持允许访问jobParameters变量。
Job-Launching 网关的可用属性
id标识基础 Spring bean 定义,该定义是以下之一的实例:EventDrivenConsumerPollingConsumer
确切的实现取决于组件的 Importing 通道是否为:
SubscribableChannel或PollableChannel
auto-startup布尔值标志,指示端点应在启动时自动启动。默认值为* true *。request-channel此端点的 ImportingMessageChannel。- 生成的
JobExecution有效负载将发送到reply-channelMessage Channel。 reply-timeout允许您指定此网关在引发异常之前 awaitawait 成功将回复消息发送到回复通道的时间。仅当通道可能阻塞时(例如,当使用当前已满的有界队列通道时),此属性才适用。另外,请记住,发送到DirectChannel时,调用将在发送者的线程中进行。因此,发送操作的失败可能是由更下游的其他组件引起的。reply-timeout属性 Map 到基础MessagingTemplate实例的sendTimeout属性。如果未指定,则该属性默认为* -1 *,这意味着默认情况下,网关将无限期 await。该值以毫秒为单位指定。job-launcher传递自定义JobLauncherbean 引用。此属性是可选的。如果未指定,适配器将重新使用在 IDjobLauncher下注册的实例。如果不存在默认实例,则将引发异常。order指定将此端点作为订户连接到SubscribableChannel时的调用 Sequences。
Sub-Elements
当此网关从PollableChannel接收消息时,您必须提供全局默认的 Poller 或为Job Launching Gateway提供 Poller 子元素:
<batch-int:job-launching-gateway request-channel="queueChannel"
reply-channel="replyChannel" job-launcher="jobLauncher">
<int:poller fixed-rate="1000"/>
</batch-int:job-launching-gateway>
13.1.3. 提供信息性消息的反馈
由于 Spring Batch 作业可以长期运行,因此提供进度信息至关重要。例如,如果批处理作业的某些或全部部分失败,则可能希望通知利益相关者。 Spring Batch 支持通过以下方式收集此信息:
- 主动轮询或
- 事件驱动,使用侦听器。
异步启动 Spring Batch 作业时,例如通过使用Job Launching Gateway,将返回JobExecution实例。因此,通过使用JobExplorer从JobRepository检索JobExecution的更新实例,可以使用JobExecution.getJobId()连续轮询状态更新。但是,这被认为不是最佳选择,因此应首选事件驱动的方法。
因此,Spring Batch 提供了以下监听器:
- StepListener
- ChunkListener
- JobExecutionListener
在以下示例中,使用StepExecutionListener配置了 Spring Batch 作业。因此,Spring Integration 将接收并处理步骤之前/之后的任何事件。例如,可以使用Router检查接收到的StepExecution。根据检查的结果,可能会发生各种事情,例如将邮件路由到邮件出站通道适配器,以便可以根据某种条件发送电子邮件通知。
以下是如何配置侦听器以针对StepExecution事件向Gateway发送消息并将其输出记录到logging-channel-adapter的示例:
首先创建通知集成 bean:
<int:channel id="stepExecutionsChannel"/>
<int:gateway id="notificationExecutionsListener"
service-interface="org.springframework.batch.core.StepExecutionListener"
default-request-channel="stepExecutionsChannel"/>
<int:logging-channel-adapter channel="stepExecutionsChannel"/>
然后修改您的工作以添加步骤级别的侦听器:
<job id="importPayments">
<step id="step1">
<tasklet ../>
<chunk ../>
<listeners>
<listener ref="notificationExecutionsListener"/>
</listeners>
</tasklet>
...
</step>
</job>
13.1.4. 异步处理器
异步处理器可帮助您扩展 Item 的处理。在异步处理器用例中,AsyncItemProcessor充当调度程序,对新线程上的 Item 执行ItemProcessor的逻辑。处理器完成后,Future将传递到AsynchItemWriter进行写入。
因此,您可以使用异步 Item 处理来提高性能,基本上可以实现* fork-join *方案。 AsyncItemWriter将收集结果并在所有结果可用后立即写回该块。
AsyncItemProcessor和AsyncItemWriter的配置都很简单,首先是AsyncItemProcessor:
<bean id="processor"
class="org.springframework.batch.integration.async.AsyncItemProcessor">
<property name="delegate">
<bean class="your.ItemProcessor"/>
</property>
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor"/>
</property>
</bean>
属性“ delegate”实际上是对ItemProcessor bean 的引用,而“ taskExecutor”属性是对所选TaskExecutor的引用。
然后,我们配置AsyncItemWriter:
<bean id="itemWriter"
class="org.springframework.batch.integration.async.AsyncItemWriter">
<property name="delegate">
<bean id="itemWriter" class="your.ItemWriter"/>
</property>
</bean>
同样,属性“ delegate”实际上是对ItemWriter bean 的引用。
13.1.5. 外化批处理执行
到目前为止讨论的集成方法建议用例,其中 Spring Integration 像 Shell 一样包装 Spring Batch。但是,Spring Batch 也可以在内部使用 Spring Integration。使用这种方法,Spring Batch 用户可以将 Item 甚至块的处理委派给外部流程。这使您可以卸载复杂的处理。 Spring Batch Integration 为以下方面提供了专门的支持:
- Remote Chunking
- Remote Partitioning
Remote Chunking
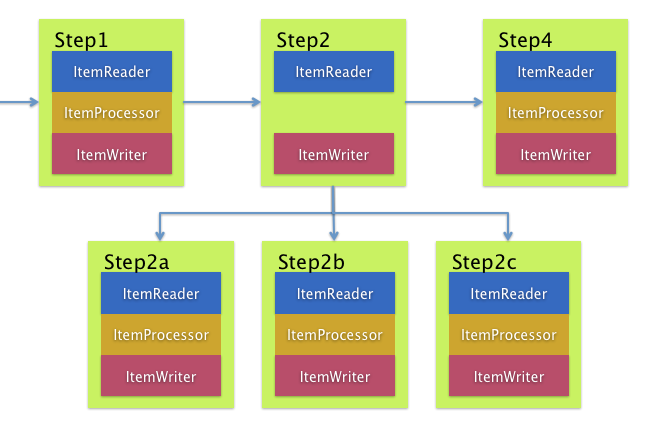
更进一步,人们还可以使用 Spring Batch Integration 提供的ChunkMessageChannelItemWriter来外部化块处理,它将发送 Item 并收集结果。发送后,Spring Batch 将 continue 读取和分组 Item,而无需 await 结果。而是由ChunkMessageChannelItemWriter负责收集结果并将其重新集成到 Spring Batch 流程中。
使用 Spring Integration,您可以完全控制进程的并发性,例如使用QueueChannel而不是DirectChannel。此外,通过依赖 Spring Integration 丰富的通道适配器集合(例如 JMS 或 AMQP),您可以将 Batch 作业的块分发到外部系统进行处理。
一个具有要远程分块的步骤的简单作业,其配置将类似于以下内容:
<job id="personJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="200"/>
</tasklet>
...
</step>
</job>
ItemReader 参考将指向您要用于在主服务器上读取数据的 bean。如上所述,ItemWriter 引用指向特殊的 ItemWriter“ ChunkMessageChannelItemWriter”。处理器(如果有)保留在从属配置上,而不再是主控配置。以下配置提供了基本的主设置。建议在实现用例时检查所有其他组件属性,例如节流阀限制等。
<bean id="connectionFactory" class="org.apache.activemq.ActiveMQConnectionFactory">
<property name="brokerURL" value="tcp://localhost:61616"/>
</bean>
<int-jms:outbound-channel-adapter id="requests" destination-name="requests"/>
<bean id="messagingTemplate"
class="org.springframework.integration.core.MessagingTemplate">
<property name="defaultChannel" ref="requests"/>
<property name="receiveTimeout" value="2000"/>
</bean>
<bean id="itemWriter"
class="org.springframework.batch.integration.chunk.ChunkMessageChannelItemWriter"
scope="step">
<property name="messagingOperations" ref="messagingTemplate"/>
<property name="replyChannel" ref="replies"/>
</bean>
<bean id="chunkHandler"
class="org.springframework.batch.integration.chunk.RemoteChunkHandlerFactoryBean">
<property name="chunkWriter" ref="itemWriter"/>
<property name="step" ref="step1"/>
</bean>
<int:channel id="replies">
<int:queue/>
</int:channel>
<int-jms:message-driven-channel-adapter id="jmsReplies"
destination-name="replies"
channel="replies"/>
这种配置为我们提供了许多 bean。我们使用 Spring Integration 提供的 ActiveMQ 和入站/出站 JMS 适配器配置消息传递中间件。如图所示,我们的工作步骤引用的itemWriter bean 利用ChunkMessageChannelItemWriter在已配置的中间件上写入块。
现在让我们 continue 进行从属配置:
<bean id="connectionFactory" class="org.apache.activemq.ActiveMQConnectionFactory">
<property name="brokerURL" value="tcp://localhost:61616"/>
</bean>
<int:channel id="requests"/>
<int:channel id="replies"/>
<int-jms:message-driven-channel-adapter id="jmsIn"
destination-name="requests"
channel="requests"/>
<int-jms:outbound-channel-adapter id="outgoingReplies"
destination-name="replies"
channel="replies">
</int-jms:outbound-channel-adapter>
<int:service-activator id="serviceActivator"
input-channel="requests"
output-channel="replies"
ref="chunkProcessorChunkHandler"
method="handleChunk"/>
<bean id="chunkProcessorChunkHandler"
class="org.springframework.batch.integration.chunk.ChunkProcessorChunkHandler">
<property name="chunkProcessor">
<bean class="org.springframework.batch.core.step.item.SimpleChunkProcessor">
<property name="itemWriter">
<bean class="io.spring.sbi.PersonItemWriter"/>
</property>
<property name="itemProcessor">
<bean class="io.spring.sbi.PersonItemProcessor"/>
</property>
</bean>
</property>
</bean>
这些配置项中的大多数应该从主配置中 Watch 起来很熟悉。从站不需要访问诸如 Spring Batch JobRepository之类的东西,也不需要访问实际的作业配置文件。感兴趣的主要 bean 是“ chunkProcessorChunkHandler”。 ChunkProcessorChunkHandler的chunkProcessor属性采用已配置的SimpleChunkProcessor,在该位置您将提供对ItemWriter以及可选的ItemProcessor的引用,该引用将在从属服务器接收到来自主服务器的块时在从属服务器上运行。
有关更多信息,请参阅 Spring Batch 手册,特别是关于Remote Chunking的章节。
Remote Partitioning
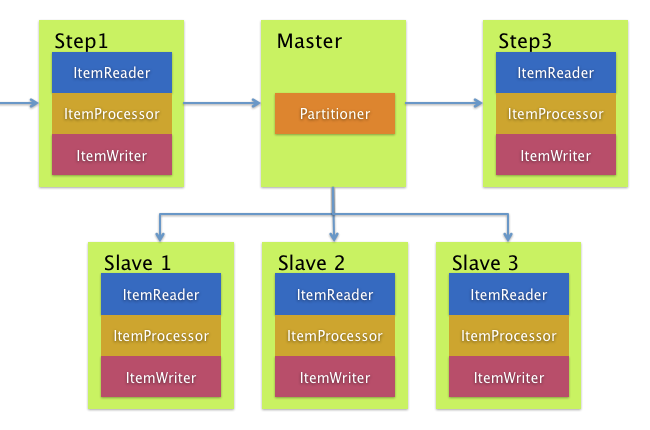
另一方面,当问题不是 Item 处理,而是相关的 I/O 成为瓶颈时,远程分区很有用。使用远程分区,可以将工作分配给执行完整 Spring Batch 步骤的从属服务器。因此,每个从站都有自己的ItemReader,ItemProcessor和ItemWriter。为此,Spring Batch Integration 提供了MessageChannelPartitionHandler。
PartitionHandler接口的此实现使用MessageChannel实例向远程工作程序发送指令并接收其响应。这提供了用于与远程工作人员通信的传输方式(例如 JMS 或 AMQP)的良好抽象。
参考手册第Remote Partitioning部分概述了配置远程分区所需的概念和组件,并显示了使用默认TaskExecutorPartitionHandler在单独的本地执行线程中进行分区的示例。为了对多个 JVM 进行远程分区,需要两个附加组件:
- 远程处理结构或网格环境
- 支持所需的远程结构或网格环境的 PartitionHandler 实现
与远程分块类似,JMS 可以用作“远程结构”,并且如上所述要使用的 PartitionHandler 实现是MessageChannelPartitionHandler。下面显示的示例假设现有分区作业,并着重于MessageChannelPartitionHandler和 JMS 配置:
<bean id="partitionHandler"
class="org.springframework.batch.integration.partition.MessageChannelPartitionHandler">
<property name="stepName" value="step1"/>
<property name="gridSize" value="3"/>
<property name="replyChannel" ref="outbound-replies"/>
<property name="messagingOperations">
<bean class="org.springframework.integration.core.MessagingTemplate">
<property name="defaultChannel" ref="outbound-requests"/>
<property name="receiveTimeout" value="100000"/>
</bean>
</property>
</bean>
<int:channel id="outbound-requests"/>
<int-jms:outbound-channel-adapter destination="requestsQueue"
channel="outbound-requests"/>
<int:channel id="inbound-requests"/>
<int-jms:message-driven-channel-adapter destination="requestsQueue"
channel="inbound-requests"/>
<bean id="stepExecutionRequestHandler"
class="org.springframework.batch.integration.partition.StepExecutionRequestHandler">
<property name="jobExplorer" ref="jobExplorer"/>
<property name="stepLocator" ref="stepLocator"/>
</bean>
<int:service-activator ref="stepExecutionRequestHandler" input-channel="inbound-requests"
output-channel="outbound-staging"/>
<int:channel id="outbound-staging"/>
<int-jms:outbound-channel-adapter destination="stagingQueue"
channel="outbound-staging"/>
<int:channel id="inbound-staging"/>
<int-jms:message-driven-channel-adapter destination="stagingQueue"
channel="inbound-staging"/>
<int:aggregator ref="partitionHandler" input-channel="inbound-staging"
output-channel="outbound-replies"/>
<int:channel id="outbound-replies">
<int:queue/>
</int:channel>
<bean id="stepLocator"
class="org.springframework.batch.integration.partition.BeanFactoryStepLocator" />
还要确保分区handler属性 Map 到partitionHandler bean:
<job id="personJob">
<step id="step1.master">
<partition partitioner="partitioner" handler="partitionHandler"/>
...
</step>
</job>
附录 A.ItemReader 和 ItemWriter 的列表
A.1ItemReader
表 A.1.可用 ItemReader
| Item Reader | Description |
|---|---|
| AbstractItemCountingItemStreamItemReader | 通过计算从ItemReader返回的 Item 数提供基本重新启动功能的抽象 Base Class。 |
| AggregateItemReader | 一个 ItemReader,将一个列表作为其 Item 传递,从注入的 ItemReader 中存储对象,直到准备好将它们打包为一个集合为止。此 ItemReader 应该使用 FieldSetMapper AggregateItemReader# BEGIN_RECORD 和 AggregateItemReader# END_RECORD 中的常量值标记记录的开始和结束。 |
| AmqpItemReader | 给定一个 Spring AmqpTemplate,它提供了同步接收方法。 receiveAndConvert()方法使您可以接收 POJO 对象。 |
| FlatFileItemReader | 从平面文件读取。包括 ItemStream 和 Skipable 功能。请参阅“从文件读取”部分 |
| HibernateCursorItemReader | 基于 HQL 查询从游标读取。请参阅有关从数据库读取的部分 |
| HibernatePagingItemReader | 从分页的 HQL 查询中读取 |
| IbatisPagingItemReader | 通过 iBATIS 根据查询进行读取。通过行的页面,以便可以在不耗尽内存的情况下读取大型数据集。请参阅 HOWTO-从数据库读取。从 Spring Batch 3.0 开始不推荐使用此 ItemReader。 |
| ItemReaderAdapter | 使任何类适应ItemReader接口。 |
| JdbcCursorItemReader | 通过 JDBC 从数据库游标中读取。请参阅 HOWTO-从数据库读取 |
| JdbcPagingItemReader | 给定一条 SQL 语句,可以在行中进行分页,这样就可以读取大型数据集而不会耗尽内存 |
| JmsItemReader | 给定一个 Spring JmsOperations 对象和一个 JMS 目标或目标名称来发送错误,它提供通过注入的 JmsOperations receive()方法接收的 Item |
| JpaPagingItemReader | 给定一个 JPQL 语句,可以在各行之间进行分页,从而可以读取大型数据集而不会耗尽内存 |
| ListItemReader | 提供列表中的 Item,一次提供一个 |
| MongoItemReader | 给定 MongoOperations 对象和基于 JSON 的 MongoDB 查询,可以提供从 MongoOperations 查找方法接收的项 |
| Neo4jItemReader | 给定 Neo4jOperations 对象和 Cyhper 查询的组件,作为 Neo4jOperations.query 方法的结果返回项 |
| RepositoryItemReader | 给定一个 Spring Data PagingAndSortingRepository 对象,一个 Sort 和要执行的方法的名称,返回 Spring Data 存储库实现提供的 Item |
| StoredProcedureItemReader | 从数据库游标读取,该游标是由于执行数据库存储过程而产生的。请参阅 HOWTO-从数据库读取 |
| StaxEventItemReader | 通过 StAX 读取。请参阅 HOWTO-从文件读取 |
A.2ItemWriter
表 A.2.可用的 ItemWriter
| Item Writer | Description |
|---|---|
| AbstractItemStreamItemWriter | 结合了ItemStream和ItemWriter接口的抽象 Base Class。 |
| AmqpItemWriter | 给定一个 Spring AmqpTemplate,它提供了同步发送方法。 convertAndSend(Object)方法使您可以发送 POJO 对象。 |
| CompositeItemWriter | 将 Item 传递给注入的 ItemWriter 对象的 List 列表中每个对象的处理方法 |
| FlatFileItemWriter | 写入平面文件。包括 ItemStream 和 Skipable 功能。请参阅“写入文件”部分 |
| GemfireItemWriter | 使用 GemfireOperations 对象,可以根据删除标志的配置从 Gemfire 实例写入或删除 Item |
| HibernateItemWriter | 该 ItemWriter 是休眠会话感知的,并处理一些与事务相关的工作,这些事务是非“休眠意识”ItemWriter 不需要知道的,然后委托另一个 ItemWriter 进行实际的编写。 |
| IbatisBatchItemWriter | 直接使用 iBatis API 批量写入 Item。从 Spring Batch 3.0 开始不推荐使用此 ItemWriter。 |
| ItemWriterAdapter | 使任何类适应ItemWriter接口。 |
| JdbcBatchItemWriter | 使用PreparedStatement中的批处理功能(如果有),并且可以采取基本步骤来确定flush期间的故障。 |
| JmsItemWriter | 使用 JmsOperations 对象,可通过 JmsOperations.convertAndSend()方法将 Item 写入默认队列。 |
| JpaItemWriter | 此 ItemWriter 是 JPA EntityManager 感知的,并处理非“ jpa 感知” ItemWriter不需要了解的一些与事务相关的工作,然后委托其他 Writer 进行实际编写。 |
| MimeMessageItemWriter | 使用 Spring 的 JavaMailSender,类型MimeMessage的 Item 作为邮件发送 |
| MongoItemWriter | 给定一个 MongoOperations 对象,可以通过 MongoOperations.save(Object)方法写入 Item。实际写入将延迟到事务提交之前的最后一个可能 Moment。 |
| Neo4jItemWriter | 给定 Neo4jOperations 对象,根据ItemWriter的配置,Item 通过 save(Object)方法保留,或通过 delete(Object)删除 |
| PropertyExtractingDelegatingItemWriter | 扩展了动态创建参数的 AbstractMethodInvokingDelegator。通过基于注入的字段名称数组从要处理的 Item 中的字段(通过 SpringBeanWrapper)中检索值来创建参数 |
| RepositoryItemWriter | 给定一个 Spring Data CrudRepository 实现,通过配置中指定的方法保存 Item。 |
| StaxEventItemWriter | 使用 ObjectToXmlSerializer 实现将每个 Item 转换为 XML,然后使用 StAX 将其写入 XML 文件。 |
附录 B.元数据架构
B.1 Overview
Spring Batch 元数据表与 Java 中表示它们的 Domain 对象非常匹配。例如,JobInstance,JobExecution,JobParameters和StepExecution分别 Map 到 BATCH_JOB_INSTANCE,BATCH_JOB_EXECUTION,BATCH_JOB_EXECUTION_PARAMS 和 BATCH_STEP_EXECUTION。 ExecutionContext同时 Map 到 BATCH_JOB_EXECUTION_CONTEXT 和 BATCH_STEP_EXECUTION_CONTEXT。 JobRepository负责将每个 Java 对象保存并存储到正确的表中。以下附录详细描述了元数据表,以及创建元数据表时做出的许多设计决策。查 Watch 下面的各种表创建语句时,重要的是要意识到所使用的数据类型应尽可能通用。 Spring Batch 提供了许多模式作为示例,由于各个数据库供应商对数据类型的处理方式不同,所有模式都有不同的数据类型。以下是所有 6 个表格及其相互关系的 ERD 模型:
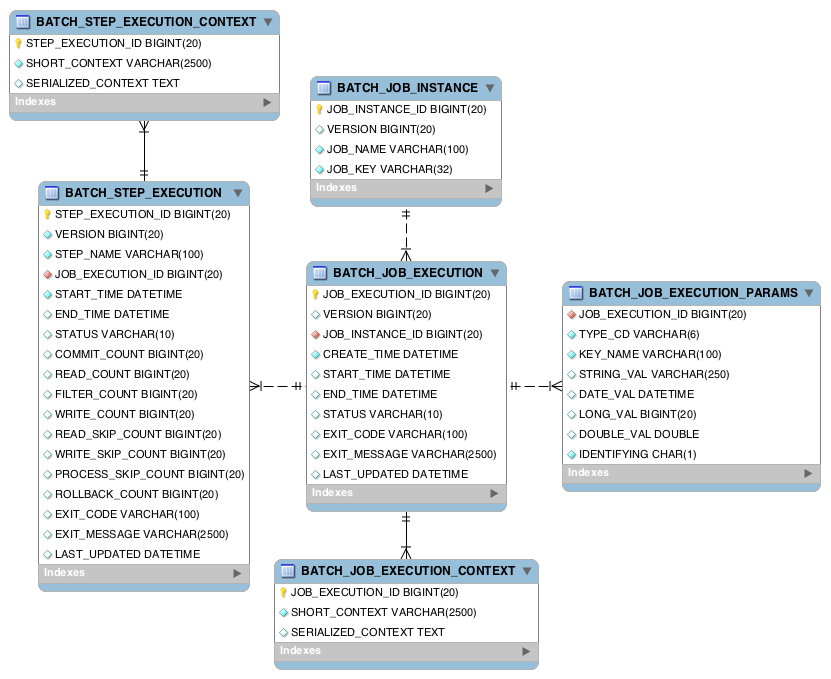
B.1.1 DDL 脚本示例
Spring Batch Core JAR 文件包含用于为多个数据库平台创建关系表的示例脚本(依次由作业存储库工厂 Bean 或等效名称空间自动检测到)。这些脚本可以按原样使用,也可以根据需要使用其他索引和约束进行修改。文件名的格式为schema-*.sql,其中“ *”是目标数据库平台的简称。脚本位于org.springframework.batch.core包中。
B.1.2 Version
本附录中讨论的许多数据库表都包含一个 version 列。该列很重要,因为 Spring Batch 在处理数据库更新时采用了乐观锁定策略。这意味着每次“触摸”(更新)一条记录时,version 列中的值就会增加 1.当存储库返回尝试保存值时,如果版本号已更改,它将抛出OptimisticLockingFailureException,表示并发访问存在错误。该检查是必需的,因为即使不同的批处理作业可能在不同的计算机上运行,它们都使用相同的数据库表。
B.1.3 Identity
BATCH_JOB_INSTANCE,BATCH_JOB_EXECUTION 和 BATCH_STEP_EXECUTION 均包含以_ID 结尾的列。这些字段充当其各自表的主键。但是,它们不是数据库生成的密钥,而是由单独的序列生成的。这是必要的,因为在将一个域对象插入数据库后,需要在实际对象上设置给出的密钥,以便可以在 Java 中对其进行唯一标识。较新的数据库驱动程序(Jdbc 3.0 及更高版本)通过数据库生成的密钥支持此功能,但并非必需使用序列。模式的每个变体将包含以下形式:
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_SEQ;
许多数据库供应商不支持序列。在这些情况下,将使用变通方法,例如以下针对 MySQL 的方法:
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_SEQ values(0);
在上述情况下,将使用表格代替每个序列。然后,Spring 核心类MySQLMaxValueIncrementer将按此 Sequences 递增一列,以提供类似的功能。
B.2 BATCH_JOB_INSTANCE
BATCH_JOB_INSTANCE 表保存与JobInstance相关的所有信息,并用作整个层次结构的顶部。以下通用 DDL 语句用于创建它:
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_NAME VARCHAR(100) NOT NULL ,
JOB_KEY VARCHAR(2500)
);
下面是表格中各列的说明:
- JOB_INSTANCE_ID:将标识实例的唯一 ID,它也是主键。此列的值应通过在
JobInstance上调用getId方法来获取。 - 版本:请参见上一节。
- JOB_NAME:从
Job对象获得的作业的名称。因为需要标识实例,所以它不能为 null。 - JOB_KEY:
JobParameters的序列化,可以唯一地标识同一作业的单独实例。 (具有相同作业名称的JobInstances必须具有不同的JobParameters,并因此具有不同的 JOB_KEY 值)。
B.3 BATCH_JOB_EXECUTION_PARAMS
BATCH_JOB_EXECUTION_PARAMS 表保存与JobParameters对象有关的所有信息。它包含传递给Job的 0 个或多个键/值对,并用作运行作业的参数的记录。对于有助于生成作业身份的每个参数,将 IDENTIFYING 标志设置为 true。应该注意的是,该表已被规范化。没有为每种类型创建单独的表,而是有一个表,其中的一列指示类型:
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);
以下是每列的说明:
- JOB_EXECUTION_ID:来自 BATCH_JOB_EXECUTION 表的外键,指示参数条目所属的作业执行。应当注意,每次执行可能存在多个行(即键/值对)。
- TYPE_CD:存储的值类型的字符串表示形式,可以是字符串,日期,长整数或双精度型。因为必须知道类型,所以不能为 null。
- KEY_NAME:参数键。
- STRING_VAL:参数值(如果类型为字符串)。
- DATE_VAL:参数值(如果类型为日期)。
- LONG_VAL:参数值(如果类型为 long)。
- DOUBLE_VAL:参数值(如果类型为 double)。
- IDENTIFYING:标志,指示参数是否促成相关
JobInstance的身份。
值得注意的是,该表没有主键。这仅仅是因为该框架没有用,因此不需要它。如果用户选择这样做,则可以添加一个数据库生成的密钥,而不会引起框架本身的任何问题。
B.4 BATCH_JOB_EXECUTION
BATCH_JOB_EXECUTION 表包含与JobExecution对象有关的所有信息。每次运行Job时,此表中总会有一个新的JobExecution和一个新行:
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
EXIT_CODE VARCHAR(20),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED TIMESTAMP,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INSTANCE_EXECUTION_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ;
以下是每列的说明:
- JOB_EXECUTION_ID:主键唯一标识此执行。可通过调用
JobExecution对象的getId方法获得此列的值。 - 版本:请参见上一节。
- JOB_INSTANCE_ID:来自 BATCH_JOB_INSTANCE 表的外键,指示此执行所属的实例。每个实例可能有多个执行。
- CREATE_TIME:表示创建执行时间的时间戳。
- START_TIME:表示执行开始时间的时间戳。
- END_TIME:时间戳,表示执行完成的时间,无论成功或失败。即使作业当前未在运行,此列中的值为空也表明存在某种类型的错误,并且框架无法执行最后的保存,然后再失败。
- 状态:表示执行状态的字符串。可以是 COMPLETED,STARTED 等。此列的对象表示形式是
BatchStatus枚举。 - EXIT_CODE:表示执行的退出代码的字符串。对于命令行作业,可以将其转换为数字。
- EXIT_MESSAGE:表示作业如何退出的更详细描述的字符串。在发生故障的情况下,这可能包括尽可能多的堆栈跟踪。
- LAST_UPDATED:时间戳记,表示最后一次执行被持久化的时间。
B.5 BATCH_STEP_EXECUTION
BATCH_STEP_EXECUTION 表包含与StepExecution对象有关的所有信息。该表在许多方面与 BATCH_JOB_EXECUTION 表非常相似,并且对于每个JobExecution创建的每个JobExecution总是至少存在一个条目:
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME TIMESTAMP NOT NULL ,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(20) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP,
constraint JOB_EXECUTION_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
以下是每列的说明:
- STEP_EXECUTION_ID:主键,唯一标识此执行。该列的值应该可以通过调用
StepExecution对象的getId方法来获得。 - 版本:请参见上一节。
- STEP_NAME:此执行所属的步骤的名称。
- JOB_EXECUTION_ID:来自 BATCH_JOB_EXECUTION 表的外键,指示此 StepExecution 所属的 JobExecution。对于给定的
Step名称,给定的JobExecution可能只有一个StepExecution。 - START_TIME:表示执行开始时间的时间戳。
- END_TIME:时间戳,表示执行完成的时间,无论成功或失败。即使作业当前未在运行,此列中的值为空也表明存在某种类型的错误,并且框架无法执行最后的保存,然后再失败。
- 状态:表示执行状态的字符串。可以是 COMPLETED,STARTED 等。此列的对象表示形式是
BatchStatus枚举。 - COMMIT_COUNT:在此执行过程中步骤提交事务的次数。
- READ_COUNT:在此执行期间读取的 Item 数。
- FILTER_COUNT:从该执行中筛选出的 Item 数。
- WRITE_COUNT:在此执行期间写入和提交的 Item 数。
- READ_SKIP_COUNT:在此执行期间读取时跳过的 Item 数。
- WRITE_SKIP_COUNT:在此执行期间写入时跳过的 Item 数。
- PROCESS_SKIP_COUNT:在此执行期间的处理过程中跳过的 Item 数。
- ROLLBACK_COUNT:此执行期间的回滚数。请注意,此计数包括每次回滚发生的时间,包括用于重试的回滚和跳过恢复过程中的回滚。
- EXIT_CODE:表示执行的退出代码的字符串。对于命令行作业,可以将其转换为数字。
- EXIT_MESSAGE:表示作业如何退出的更详细描述的字符串。在发生故障的情况下,这可能包括尽可能多的堆栈跟踪。
- LAST_UPDATED:时间戳记,表示最后一次执行被持久化的时间。
B.6 BATCH_JOB_EXECUTION_CONTEXT
BATCH_JOB_EXECUTION_CONTEXT 表保存与Job的ExecutionContext相关的所有信息。每个JobExecution恰好有一个Job ExecutionContext,并且它包含特定作业执行所需的所有作业级别数据。该数据通常表示故障后必须检索的状态,以便JobInstance可以从“中断处开始”。
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
以下是每列的说明:
- JOB_EXECUTION_ID:表示上下文所属的
JobExecution的外键。与给定执行相关联的行可能不止一个。 - SHORT_CONTEXT:SERIALIZED_CONTEXT 的字符串版本。
- SERIALIZED_CONTEXT:整个上下文,已序列化。
B.7 BATCH_STEP_EXECUTION_CONTEXT
BATCH_STEP_EXECUTION_CONTEXT 表保存与Step的ExecutionContext相关的所有信息。每个StepExecution恰好有一个ExecutionContext,并且它包含执行特定步骤所需要保留的所有数据。此数据通常表示故障后必须检索的状态,以便JobInstance可以从中断处开始。
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ;
以下是每列的说明:
- STEP_EXECUTION_ID:外键,表示上下文所属的
StepExecution。与给定执行相关联的行可能不止一个。 - SHORT_CONTEXT:SERIALIZED_CONTEXT 的字符串版本。
- SERIALIZED_CONTEXT:整个上下文,已序列化。
B.8 Archiving
因为每次运行批处理作业时多个表中都有条目,所以通常为元数据表创建一个归档策略。这些表本身旨在显示过去发生的情况的记录,并且通常不会影响任何作业的运行,但有几个与重新启动有关的显着异常:
- 框架将使用元数据表来确定是否已运行过特定的 JobInstance。如果已运行,并且该作业不可重新启动,则将引发异常。
- 如果未成功完成就删除 JobInstance 的条目,则框架将认为作业是新的,而不是重新启动。
- 如果重新启动作业,则框架将使用已持久保存到 ExecutionContext 的所有数据来还原作业的状态。因此,从表中删除所有未成功完成的作业的条目将阻止它们在正确的位置重新启动。
B.9 国际字符和多字节字符
如果您在业务处理中使用多字节字符集(例如 Chines 或 Cyrillic),那么这些字符可能需要保留在 Spring Batch 模式中。许多用户发现,只需将架构更改为VARCHAR列的长度的两倍就足够了。其他人更喜欢用max-varchar-length配置一半的max-varchar-length列长度就足够了。一些用户还报告说,他们在架构定义中使用NVARCHAR代替VARCHAR。最佳结果将取决于数据库平台和在本地配置数据库服务器的方式。
B.10 为元数据表构建索引的建议
Spring Batch 为几个常见数据库平台的 Core jar 文件中的元数据表提供了 DDL 示例。索引声明未包含在该 DDL 中,因为用户可能希望根据自己的精确平台,本地约定以及如何操作作业的业务要求来构建索引的方式有所不同。下表提供了一些指示,这些指示是 Spring Batch 提供的 Dao 实现将在 WHERE 子句中使用哪些列,以及它们的使用频率,以便各个 Item 可以对索引制定自己的想法。
表 B.1.SQL 语句中的 where 子句(不包括主键)及其大致使用频率.
| 默认表名 | Where Clause | Frequency |
|---|---|---|
| BATCH_JOB_INSTANCE | JOB_NAME =吗?和 JOB_KEY =? | 每次启动工作 |
| BATCH_JOB_EXECUTION | JOB_INSTANCE_ID =? | 每次重新启动作业 |
| BATCH_EXECUTION_CONTEXT | EXECUTION_ID =吗?和 KEY_NAME =吗? | 在提交间隔上,也就是大块 |
| BATCH_STEP_EXECUTION | 版本=? | 在提交间隔上,又称为块(以及步骤的开始和结束) |
| BATCH_STEP_EXECUTION | STEP_NAME =吗?和 JOB_EXECUTION_ID =? | 在执行每个步骤之前 |
附录 C.批处理和事务
C.1 简单批处理,不重试
考虑以下不重试的嵌套批处理的简单示例。这是批处理的非常常见的情况,在这种情况下,将处理 Importing 源直到用尽,但是我们会在“大块”处理结束时定期提交。
1 | REPEAT(until=exhausted) {
|
2 | TX {
3 | REPEAT(size=5) {
3.1 | input;
3.2 | output;
| }
| }
|
| }
Importing 操作(3.1)可以是基于消息的接收(例如 JMS),也可以是基于文件的读取,但是要恢复并 continue 处理并有可能完成整个作业,它必须是事务性的。同样适用于(3.2)处的操作-它必须是事务性的或幂等的。
如果由于(3.2)处的数据库异常而导致 REPEAT(3)处的块失败,则 TX(2)将回滚整个块。
C.2 简单 Stateless 重试
将重试用于非事务性操作(例如对 Web 服务或其他远程资源的调用)也很有用。例如:
0 | TX {
1 | input;
1.1 | output;
2 | RETRY {
2.1 | remote access;
| }
| }
实际上,这是重试最有用的应用程序之一,因为远程调用比数据库更新更有可能失败并且可以重试。只要远程访问(2.1)最终成功,事务 TX(0)就会提交。如果远程访问(2.1)最终失败,则保证事务 TX(0)回滚。
C.3 典型的重试模式
在“简单批处理”示例中,最典型的批处理模式是将重试添加到块的内部块。考虑一下:
1 | REPEAT(until=exhausted, exception=not critical) {
|
2 | TX {
3 | REPEAT(size=5) {
|
4 | RETRY(stateful, exception=deadlock loser) {
4.1 | input;
5 | } PROCESS {
5.1 | output;
6 | } SKIP and RECOVER {
| notify;
| }
|
| }
| }
|
| }
内部 RETRY(4)块被标记为“有状态”-有关有状态重试的说明,请参见典型用例。这意味着,如果 retry PROCESS(5)块失败,则 RETRY(4)的行为如下。
- 引发异常,在块级回滚事务 TX(2),并允许将该 Item 重新呈现到 Importing 队列中。
- 重新出现该 Item 时,可能会根据适当的重试策略对其进行重试,然后再次执行 PROCESS(5)。第二次和随后的尝试可能会再次失败并重新引发异常。
- 最终,该 Item 在最后一次重新出现:重试策略不允许再次尝试,因此永远不会执行 PROCESS(5)。在这种情况下,我们遵循 RECOVER(6)路径,有效地“跳过”了已接收并正在处理的 Item。
请注意,以上计划中用于 RETRY(4)的表示法清楚地表明,Importing 步骤(4.1)是重试的一部分。它也清楚地表明,有两个备用处理路径:正常情况由 PROCESS(5)表示,恢复路径是一个单独的块 RECOVER(6)。两条替代路径是完全不同的:在正常情况下,只有一条可以采用。
在特殊情况下(例如,特殊的TranscationValidException类型),重试策略可能能够确定 RECOVER(6)路径可以在 PROCESS(5)刚刚失败之后的最后一次尝试中采用,而不必 await 该 Item 被重新呈现。这不是默认行为,因为它需要详细了解 PROCESS(5)块内发生的情况,而这通常是不可用的,例如如果输出在失败之前包含写访问权限,则应重新抛出异常以确保事务完整性。
外部的 REPEAT(1)中的完成策略对于上述计划的成功至关重要。如果 output(5.1)失败,则可能引发异常(如所描述的,通常会发生异常),在这种情况下,事务 TX(2)失败,并且异常可能会通过外部批处理 REPEAT(1)向上传播。我们不希望整个批处理都停止,因为如果再次尝试,RETRY(4)可能仍然会成功,所以我们向外部 REPEAT(1)添加了 exception = critical。
但是请注意,如果 TX(2)失败,并且我们*根据外部完成策略再次尝试,则内部 REPEAT(3)中下一个处理的 Item 不能保证是失败了可能不错,但这取决于 input(4.1)的实现。因此,output(5.1)可能在新 Item 或旧 Item 上再次失败。批处理的 Client 不应假定每次 RETRY(4)尝试都将处理与最后一个失败的 Item 相同的 Item。例如。如果 REPEAT(1)的终止策略在 10 次尝试后失败,则它将在 10 次连续尝试后失败,但不一定在同一 Item 上。这与整体重试策略是一致的:内部 RETRY(4)知道每个 Item 的历史记录,并可以决定是否对其进行其他尝试。
C.4 异步块处理
通过将外部批处理配置为使用AsyncTaskExecutor,可以同时执行上述典型示例中的内部批处理或块。外部批处理在完成之前 await 所有块完成。
1 | REPEAT(until=exhausted, concurrent, exception=not critical) {
|
2 | TX {
3 | REPEAT(size=5) {
|
4 | RETRY(stateful, exception=deadlock loser) {
4.1 | input;
5 | } PROCESS {
| output;
6 | } RECOVER {
| recover;
| }
|
| }
| }
|
| }
C.5 异步 Item 处理
典型情况下,典型情况下大块中的单个 Item 也可以同时处理。在这种情况下,事务边界必须移至单个 Item 的级别,以便每个事务都在单个线程上:
1 | REPEAT(until=exhausted, exception=not critical) {
|
2 | REPEAT(size=5, concurrent) {
|
3 | TX {
4 | RETRY(stateful, exception=deadlock loser) {
4.1 | input;
5 | } PROCESS {
| output;
6 | } RECOVER {
| recover;
| }
| }
|
| }
|
| }
该计划牺牲了简单计划所具有的优化优势,即将所有事务资源分块在一起。仅当处理(5)的成本比事务 Management(3)的成本高得多时,它才有用。
C.6 批处理与事务传播之间的相互作用
重试和发送 Management 之间的耦合比我们理想的紧密。特别是,Stateless 重试不能用于不支持 NESTED 传播的事务 Management 器重试数据库操作。
对于使用重试而不重复的简单示例,请考虑以下事项:
1 | TX {
|
1.1 | input;
2.2 | database access;
2 | RETRY {
3 | TX {
3.1 | database access;
| }
| }
|
| }
同样,出于相同的原因,即使 RETRY(2)最终成功,内部事务 TX(3)也会导致外部事务 TX(1)失败。
不幸的是,如果存在以下情况,则相同的效果会从重试块渗入周围的重复批处理中:
1 | TX {
|
2 | REPEAT(size=5) {
2.1 | input;
2.2 | database access;
3 | RETRY {
4 | TX {
4.1 | database access;
| }
| }
| }
|
| }
现在,如果 TX(3)回滚,它将污染 TX(1)的整个批次,并强制其在最后回滚。
非默认传播呢?
- 在最后一个示例中,如果两个事务最终都成功,则 TX(3)处的 PROPAGATION_REQUIRES_NEW 将防止外部 TX(1)被污染。但是,如果 TX(3)提交而 TX(1)回滚,则 TX(3)保持提交状态,因此我们违反了 TX(1)的事务 Contract。如果 TX(3)回滚,则 TX(1)不一定(但实际上可能会这样做,因为重试将抛出回滚异常)。
- TX(3)的 PROPAGATION_NESTED 可以按照我们在重试情况下(对于具有跳过的批处理)的要求进行工作:TX(3)可以提交,但随后由外部事务 TX(1)回滚。如果 TX(3)回滚,实际上 TX(1)也会回滚。此选项仅在某些平台上可用,例如不是 Hibernate 或 JTA,但它是唯一能够持续工作的软件。
因此,如果重试块包含任何数据库访问权限,则 NESTED 最好。
C.7 特例:具有正交资源的事务
对于没有嵌套数据库事务的简单情况,默认传播总是可以的。考虑一下(SESSION 和 TX 不是全局 XA 资源,因此它们的资源是正交的):
0 | SESSION {
1 | input;
2 | RETRY {
3 | TX {
3.1 | database access;
| }
| }
| }
这里有一个事务性消息 SESSION(0),但是它不与PlatformTransactionManager参与其他事务,因此在 TX(3)启动时不会传播。在 RETRY(2)块之外没有数据库访问权限。如果 TX(3)失败,然后最终重试成功,则 SESSION(0)可以提交(它可以独立于 TX 块执行此操作)。这类似于原始的“尽力而为一阶段提交”方案-可能发生的最坏情况是,当 RETRY(2)成功并且 SESSION(0)无法提交(例如,失败)时出现重复消息。因为消息系统不可用。
C.8Stateless 重试无法恢复
在上述典型示例中,Stateless 重试与有状态重试之间的区别很重要。实际上,最终是强制执行区分的事务性约束,并且该约束也使显而易见为什么存在区分。
我们首先观察到,除非将 Item 处理包装在事务中,否则无法跳过失败的 Item 并成功提交其余的块。因此,我们将典型的批处理执行计划简化如下:
0 | REPEAT(until=exhausted) {
|
1 | TX {
2 | REPEAT(size=5) {
|
3 | RETRY(stateless) {
4 | TX {
4.1 | input;
4.2 | database access;
| }
5 | } RECOVER {
5.1 | skip;
| }
|
| }
| }
|
| }
在这里,我们有一个 Stateless 的 RETRY(3)和 RECOVER(5)路径,该路径在最终尝试失败后会启动。 “Stateless”标签仅表示将重复执行该块,而不会将任何异常抛出任何上限。仅当事务 TX(4)具有传播嵌套时,此方法才起作用。
如果 TX(3)具有默认的传播属性并且回滚,它将污染外部 TX(1)。事务 Management 器认为内部事务破坏了事务资源,因此无法再次使用它。
对 NESTED 传播的支持非常罕见,我们选择在当前版本的 Spring Batch 中不支持 Stateless 重试的恢复。使用上面的典型模式始终可以达到相同的效果(以重复进行更多的处理为代价)。Glossary
Spring Batch 词汇
- Batch
- 随着时间的推移业务事务的积累。
- 批量申请样式
- 用于单独将批处理指定为应用程序样式的术语,类似于在线,Web 或 SOA。它具有 Importing,验证,信息到业务模型的转换,业务处理和输出的标准元素。另外,它需要在宏级别进行监视。
- Batch Processing
- 处理一段时间内(例如一小时,一天,一周,一个月或一年)积累的一批许多业务事务。它是一种过程或一组过程以重复且可预测的方式应用于许多数据实体或对象,没有手动元素,也没有单独的手动元素用于错误处理。
- Batch Window
- 批处理作业必须完成的时间范围。这可能会受到其他联机系统,需要执行的其他依赖作业或特定于批处理环境的其他因素的限制。
- Step
- 它是主要的批处理任务或工作单位控制器。它初始化业务逻辑,并根据提交间隔设置等控制事务环境。
- Tasklet
- 由应用程序开发人员创建的组件,用于处理步骤的业务逻辑。
- 批处理作业类型
- 作业类型描述了特定处理类型的作业应用。常见的领域是界面处理(通常是平面文件),表单处理(用于在线 pdf 生成或打印格式),报告处理。
- Driving Query
- 驾驶查询可识别工作要做的工作集;然后,工作将工作分解为各个工作单元。例如,识别所有状态为“待传输”的金融事务,并将其发送到我们的合作伙伴系统。驾驶查询返回一组记录 ID 进行处理;每个记录 ID 便成为一个工作单元。驾驶查询可能涉及联接(如果选择标准属于两个或多个表),或者可能与单个表一起使用。
- Item
- 一个 Item 代表要处理的最小完整数据量。用最简单的术语来说,这可能意味着文件中的一行,数据库表中的一行或 XML 文件中的特定元素。
- 逻辑工作单元(LUW)
- 批处理作业通过驾驶查询(或其他 Importing 源,例如文件)进行迭代,以执行该作业必须完成的一组工作。所执行的每个工作迭代都是一个工作单元。
- Commit Interval
- 在单个事务中处理的一组 LUW。
- Partitioning
- 将作业拆分为多个线程,其中每个线程负责要处理的全部数据的子集。执行线程可以在同一 JVM 内,也可以跨越支持工作负载平衡的群集环境中的 JVM。
- Staging Table
- 一个在处理临时数据时保留临时数据的表。
- Restartable
- 可以再次执行的作业,将具有与最初运行时相同的身份。在 othewords 中,它具有相同的作业实例 ID。
- Rerunnable
- 可重新启动的作业,并根据先前运行的记录处理来 Management 其自己的状态。可重新运行步骤的一个示例是基于驾驶查询的步骤。如果可以形成驱动查询,以使其在重新启动作业时限制了已处理的行,则它可以重新运行。这由应用程序逻辑 Management。通常情况下,条件会添加到 where 语句中,以限制驾驶查询返回的行的内容为“ and createdFlag!= true”。
- Repeat
- 批处理中最基本的单元之一,它定义可重复性,调用部分代码直到完成,并且没有错误。通常,只要有 Importing,批处理就可以重复。
- Retry
- 使用与处理事务输出异常最常相关的重试语义简化操作的执行。重试与重复稍有不同,重试是连续的,而不是连续调用代码块,它是有状态的,并使用相同的 Importing 连续调用相同的代码块,直到它成功或超过某种类型的重试限制为止。通常仅在后续操作调用可能成功(因为环境中的某些问题得到改善)时才有用。
- Recover
- 恢复操作以使重复过程能够 continue 的方式处理异常。
- Skip
- 跳过是一种恢复策略,常用于文件 Importing 源,作为忽略验证失败的错误 Importing 记录的策略。

