Spring中的问题
Spring中的循环依赖
什么是循环依赖?
很简单,就是A对象依赖了B对象,B对象依赖了A对象。
比如:
// A依赖了B
class A{
public B b;
}
// B依赖了A
class B{
public A a;
}
那么循环依赖是个问题吗?
如果不考虑Spring,循环依赖并不是问题,因为对象之间相互依赖是很正常的事情。
比如
A a = new A();
B b = new B();
a.b = b;
b.a = a;
这样,A,B就依赖上了。
但是,在Spring中循环依赖就是一个问题了,为什么?
因为,在Spring中,一个对象并不是简单new出来了,而是会经过一系列的Bean的生命周期,就是因为Bean的生命周期所以才会出现循环依赖问题。当然,在Spring中,出现循环依赖的场景很多,有的场景Spring自动帮我们解决了,而有的场景则需要程序员来解决,下文详细来说。
要明白Spring中的循环依赖,得先明白Spring中Bean的生命周期。
Bean的生命周期
这里不会对Bean的生命周期进行详细的描述,只描述一下大概的过程。
Bean的生命周期指的就是:在Spring中,Bean是如何生成的?
被Spring管理的对象叫做Bean。Bean的生成步骤如下:
- Spring扫描class得到BeanDefinition
- 根据得到的BeanDefinition去生成bean
- 首先根据class推断构造方法
- 根据推断出来的构造方法,反射,得到一个对象(暂时叫做原始对象)
- 填充原始对象中的属性(依赖注入)
- 如果原始对象中的某个方法被AOP了,那么则需要根据原始对象生成一个代理对象
- 把最终生成的代理对象放入单例池(源码中叫做singletonObjects)中,下次getBean时就直接从单例池拿即可
可以看到,对于Spring中的Bean的生成过程,步骤还是很多的,并且不仅仅只有上面的7步,还有很多很多,比如Aware回调、初始化等等,这里不详细讨论。
可以发现,在Spring中,构造一个Bean,包括了new这个步骤(第4步构造方法反射)。
得到一个原始对象后,Spring需要给对象中的属性进行依赖注入,那么这个注入过程是怎样的?
比如上文说的A类,A类中存在一个B类的b属性,所以,当A类生成了一个原始对象之后,就会去给b属性去赋值,此时就会根据b属性的类型和属性名去BeanFactory中去获取B类所对应的单例bean。如果此时BeanFactory中存在B对应的Bean,那么直接拿来赋值给b属性;如果此时BeanFactory中不存在B对应的Bean,则需要生成一个B对应的Bean,然后赋值给b属性。
问题就出现在第二种情况,如果此时B类在BeanFactory中还没有生成对应的Bean,那么就需要去生成,就会经过B的Bean的生命周期。
那么在创建B的Bean的过程中,如果B类中存在一个A类的a属性,那么在创建B的Bean的过程中就需要A类对应的Bean,但是,触发B类Bean的创建的条件是A类Bean在创建过程中的依赖注入,所以这里就出现了循环依赖:
ABean创建–>依赖了B属性–>触发BBean创建—>B依赖了A属性—>需要ABean(但ABean还在创建过程中)
从而导致ABean创建不出来,BBean也创建不出来。
这是循环依赖的场景,但是上文说了,在Spring中,通过某些机制帮开发者解决了部分循环依赖的问题,这个机制就是三级缓存。
三级缓存
三级缓存是通用的叫法。
一级缓存为:singletonObjects
二级缓存为:earlySingletonObjects
三级缓存为:singletonFactories
先稍微解释一下这三个缓存的作用,后面详细分析:
- singletonObjects中缓存的是已经经历了完整生命周期的bean对象。
- earlySingletonObjects比singletonObjects多了一个early,表示缓存的是早期的bean对象。早期是什么意思?表示Bean的生命周期还没走完就把这个Bean放入了earlySingletonObjects。
- singletonFactories中缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的。
解决循环依赖思路分析
先来分析为什么缓存能解决循环依赖。
上文分析得到,之所以产生循环依赖的问题,主要是:
A创建时—>需要B—->B去创建—>需要A,从而产生了循环
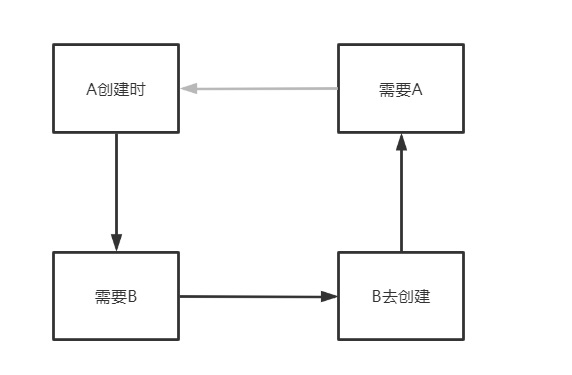
那么如何打破这个循环,加个中间人(缓存)
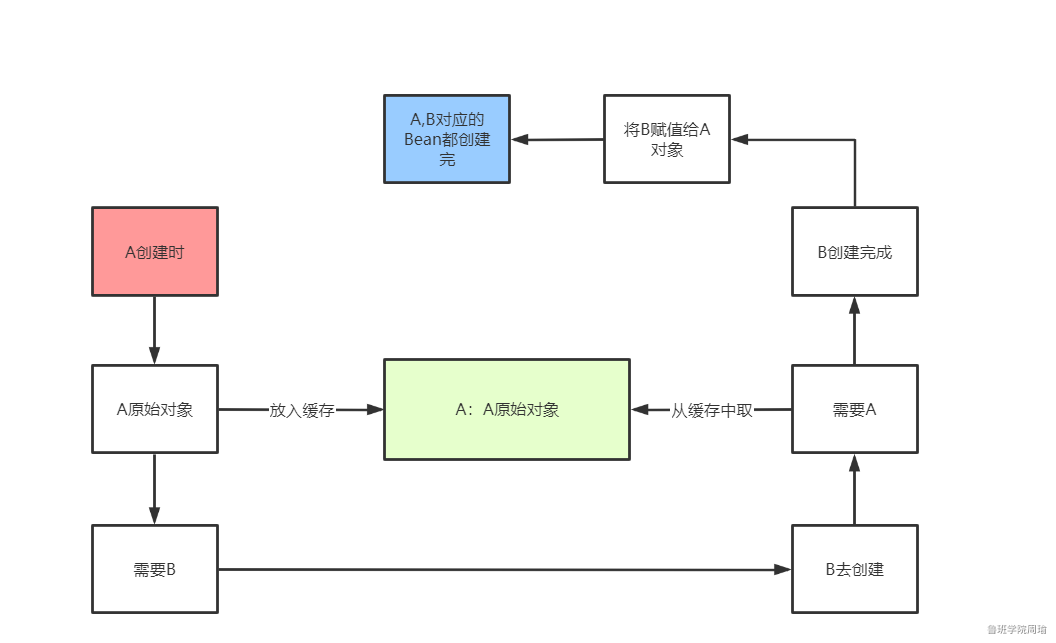
A的Bean在创建过程中,在进行依赖注入之前,先把A的原始Bean放入缓存(提早暴露,只要放到缓存了,其他Bean需要时就可以从缓存中拿了),放入缓存后,再进行依赖注入,此时A的Bean依赖了B的Bean,如果B的Bean不存在,则需要创建B的Bean,而创建B的Bean的过程和A一样,也是先创建一个B的原始对象,然后把B的原始对象提早暴露出来放入缓存中,然后在对B的原始对象进行依赖注入A,此时能从缓存中拿到A的原始对象(虽然是A的原始对象,还不是最终的Bean),B的原始对象依赖注入完了之后,B的生命周期结束,那么A的生命周期也能结束。
因为整个过程中,都只有一个A原始对象,所以对于B而言,就算在属性注入时,注入的是A原始对象,也没有关系,因为A原始对象在后续的生命周期中在堆中没有发生变化。
从上面这个分析过程中可以得出,只需要一个缓存就能解决循环依赖了,那么为什么Spring中还需要singletonFactories呢?
这是难点,基于上面的场景想一个问题:如果A的原始对象注入给B的属性之后,A的原始对象进行了AOP产生了一个代理对象,此时就会出现,对于A而言,它的Bean对象其实应该是AOP之后的代理对象,而B的a属性对应的并不是AOP之后的代理对象,这就产生了冲突。
B依赖的A和最终的A不是同一个对象。
那么如何解决这个问题?这个问题可以说没有办法解决。
因为在一个Bean的生命周期最后,Spring提供了BeanPostProcessor可以去对Bean进行加工,这个加工不仅仅只是能修改Bean的属性值,也可以替换掉当前Bean。
举个例子:
@Component
public class User {
}
@Component
public class LubanBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
// 注意这里,生成了一个新的User对象
if (beanName.equals("user")) {
System.out.println(bean);
User user = new User();
return user;
}
return bean;
}
}
** **
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext context =
new AnnotationConfigApplicationContext(AppConfig.class);
User user = context.getBean("user", User.class);
System.out.println(user);
}
}
运行main方法,得到的打印如下:
com.luban.service.User@5e025e70
com.luban.service.User@1b0375b3
所以在BeanPostProcessor中可以完全替换掉某个beanName对应的bean对象。
而BeanPostProcessor的执行在Bean的生命周期中是处于属性注入之后的,循环依赖是发生在属性注入过程中的,所以很有可能导致,注入给B对象的A对象和经历过完整生命周期之后的A对象,不是一个对象。这就是有问题的。
所以在这种情况下的循环依赖,Spring是解决不了的,因为在属性注入时,Spring也不知道A对象后续会经过哪些BeanPostProcessor以及会对A对象做什么处理。
Spring到底解决了哪种情况下的循环依赖
虽然上面的情况可能发生,但是肯定发生得很少,我们通常在开发过程中,不会这样去做,但是,某个beanName对应的最终对象和原始对象不是一个对象却会经常出现,这就是AOP。
AOP就是通过一个BeanPostProcessor来实现的,这个BeanPostProcessor就是AnnotationAwareAspectJAutoProxyCreator,它的父类是AbstractAutoProxyCreator,而在Spring中AOP利用的要么是JDK动态代理,要么CGLib的动态代理,所以如果给一个类中的某个方法设置了切面,那么这个类最终就需要生成一个代理对象。
一般过程就是:A类—>生成一个普通对象–>属性注入–>基于切面生成一个代理对象–>把代理对象放入singletonObjects单例池中。
而AOP可以说是Spring中除开IOC的另外一大功能,而循环依赖又是属于IOC范畴的,所以这两大功能想要并存,Spring需要特殊处理。
如何处理的,就是利用了第三级缓存singletonFactories。
首先,singletonFactories中存的是某个beanName对应的ObjectFactory,在bean的生命周期中,生成完原始对象之后,就会构造一个ObjectFactory存入singletonFactories中。这个ObjectFactory是一个函数式接口,所以支持Lambda表达式:() -> getEarlyBeanReference(beanName, mbd, bean)
上面的Lambda表达式就是一个ObjectFactory,执行该Lambda表达式就会去执行getEarlyBeanReference方法,而该方法如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
该方法会去执行SmartInstantiationAwareBeanPostProcessor中的getEarlyBeanReference方法,而这个接口下的实现类中只有两个类实现了这个方法,一个是AbstractAutoProxyCreator,一个是InstantiationAwareBeanPostProcessorAdapter,它的实现如下:
// InstantiationAwareBeanPostProcessorAdapter
@Override
public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {
return bean;
}
// AbstractAutoProxyCreator
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return wrapIfNecessary(bean, beanName, cacheKey);
}
所以很明显,在整个Spring中,默认就只有AbstractAutoProxyCreator真正意义上实现了getEarlyBeanReference方法,而该类就是用来进行AOP的。上文提到的AnnotationAwareAspectJAutoProxyCreator的父类就是AbstractAutoProxyCreator。
那么getEarlyBeanReference方法到底在干什么?
首先得到一个cachekey,cachekey就是beanName。
然后把beanName和bean(这是原始对象)存入earlyProxyReferences中
调用wrapIfNecessary进行AOP,得到一个代理对象。
那么,什么时候会调用getEarlyBeanReference方法呢?回到循环依赖的场景中
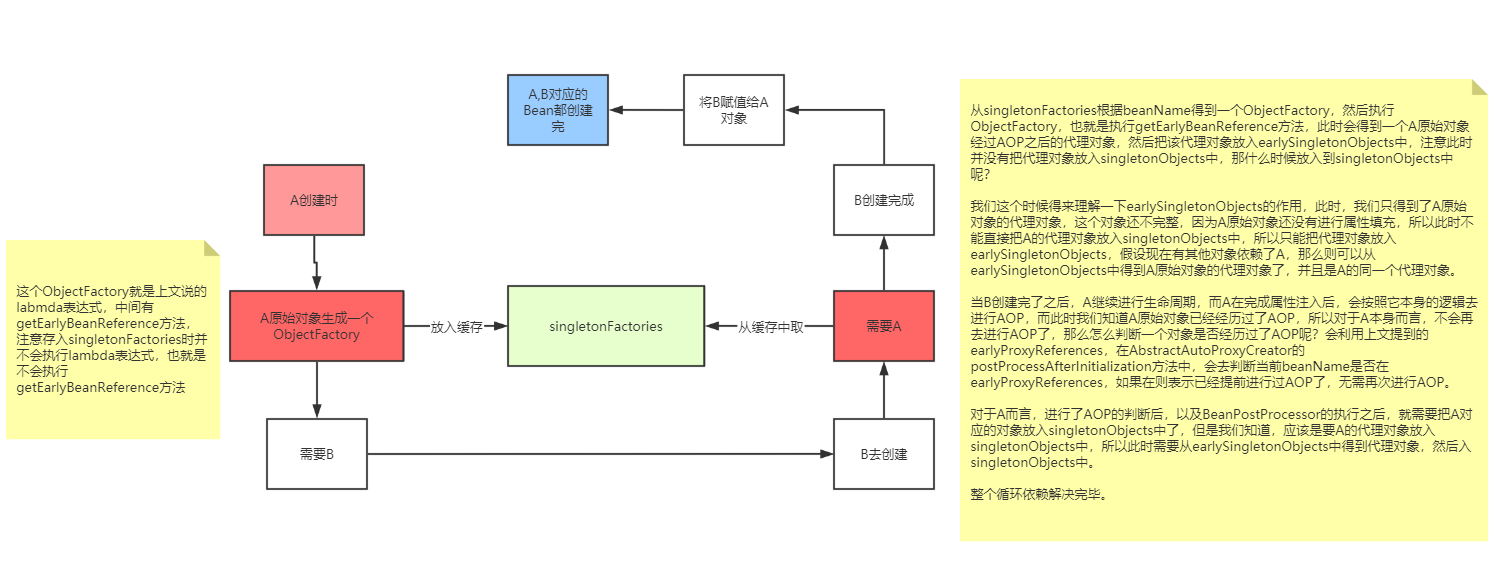
左边文字:
这个ObjectFactory就是上文说的labmda表达式,中间有getEarlyBeanReference方法,注意存入singletonFactories时并不会执行lambda表达式,也就是不会执行getEarlyBeanReference方法
右边文字:
从singletonFactories根据beanName得到一个ObjectFactory,然后执行ObjectFactory,也就是执行getEarlyBeanReference方法,此时会得到一个A原始对象经过AOP之后的代理对象,然后把该代理对象放入earlySingletonObjects中,注意此时并没有把代理对象放入singletonObjects中,那什么时候放入到singletonObjects中呢?
我们这个时候得来理解一下earlySingletonObjects的作用,此时,我们只得到了A原始对象的代理对象,这个对象还不完整,因为A原始对象还没有进行属性填充,所以此时不能直接把A的代理对象放入singletonObjects中,所以只能把代理对象放入earlySingletonObjects,假设现在有其他对象依赖了A,那么则可以从earlySingletonObjects中得到A原始对象的代理对象了,并且是A的同一个代理对象。
当B创建完了之后,A继续进行生命周期,而A在完成属性注入后,会按照它本身的逻辑去进行AOP,而此时我们知道A原始对象已经经历过了AOP,所以对于A本身而言,不会再去进行AOP了,那么怎么判断一个对象是否经历过了AOP呢?会利用上文提到的earlyProxyReferences,在AbstractAutoProxyCreator的postProcessAfterInitialization方法中,会去判断当前beanName是否在earlyProxyReferences,如果在则表示已经提前进行过AOP了,无需再次进行AOP。
对于A而言,进行了AOP的判断后,以及BeanPostProcessor的执行之后,就需要把A对应的对象放入singletonObjects中了,但是我们知道,应该是要A的代理对象放入singletonObjects中,所以此时需要从earlySingletonObjects中得到代理对象,然后入singletonObjects中。
整个循环依赖解决完毕。
总结
至此,总结一下三级缓存:
- singletonObjects:缓存某个beanName对应的经过了完整生命周期的bean
- earlySingletonObjects:缓存提前拿原始对象进行了AOP之后得到的代理对象,原始对象还没有进行属性注入和后续的BeanPostProcessor等生命周期
- singletonFactories:缓存的是一个ObjectFactory,主要用来去生成原始对象进行了AOP之后得到的代理对象,在每个Bean的生成过程中,都会提前暴露一个工厂,这个工厂可能用到,也可能用不到,如果没有出现循环依赖依赖本bean,那么这个工厂无用,本bean按照自己的生命周期执行,执行完后直接把本bean放入singletonObjects中即可,如果出现了循环依赖依赖了本bean,则另外那个bean执行ObjectFactory提交得到一个AOP之后的代理对象(如果有AOP的话,如果无需AOP,则直接得到一个原始对象)。
- 其实还要一个缓存,就是earlyProxyReferences,它用来记录某个原始对象是否进行过AOP了。
源码解读
首先,有两种Bean的注入方式,构造器注入和属性注入,对于构造器注入的循环依赖,Spring处理不了,会直接抛出BeanCurrentlyCreationException异常,对于属性注入的循环依赖(单例模式下)是通过三级缓存来处理循环依赖的。而非单例对象的循环依赖则无法处理,下面分析单例模式下属性注入的循环依赖怎么处理的。首先bean单例对象的初始化大致分为三步;
- createBeanInstance:实例化bean,使用构造方法创建对象,为对象分配内存
- populateBean:进行依赖注入
- initializeBean:初始化bean
Spring为了解决单例的循环依赖的问题,使用了三级缓存:
- singletonObjects:完成了初始化的单例对象map
- earlySingletonObjects:完成实例化未初始化的单例对象map
- singletonFactories:单例对象工厂map,单例对象实例化完成后加入singletonFactories。
在调用createBeanInstance进行实例化后,会调用addSingletonFactories,将单例对象放到singletonFactories中。假如A依赖了B的实例对象,同时B也依赖了A的实例对象。
- A首先完成了实例化,并且将自己添加到singletonFactories中
- 接着继续宁依赖注入,发现自己依赖对象B,此时就会尝试去get(B)
- 发现B还没有被实例化,对B进行实例化
- 然后B在初始化时发现自己依赖了对象A于是调用get(A),在一级缓存singletonObjects和二级缓存earlySingletonObjects中进行查找找不到尝试从三级缓存singletonFactories中查找,由于A初始化的时候把自己加到singletonFactories中了,所以B可以拿到A对象,然后将A从三级缓存移动到二级缓存中
- B拿到A的对象后顺利完成了初始化,然后将自己放到一级缓存中,
- 此时返回A,A此时能拿到B的对象,顺利完成初始化
所以属性注入的循环依赖主要是通过将实例化完成的bean添加到singletonFactories中来实现的,而使用构造器依赖注入的bean在实例化的时候进行依赖注入,不会被添加到singletonFactories中
bean的初始化方法
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean
...............
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); //存放到SingletonFactorys中
}
..............
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
...........
}
}
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return wrapIfNecessary(bean, beanName, cacheKey);
}
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 先从singletonObjects中找
Object singletonObject = this.singletonObjects.get(beanName);
// singletonObjects中没有,并且是正在创建的bean
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 从earlySingletonObjects中获取
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 从 singletonFactories中获取执行getObject方法获取早期经过aop的代理对象
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
正在创建的bean
public boolean isSingletonCurrentlyInCreation(String beanName) {
return this.singletonsCurrentlyInCreation.contains(beanName);
}
在属性注入的时候,会先从singletonObject中获取,如果里面没有,并且这个bean正在创建(有一个map中存放了所有正在创建的bean),表示发生了循环依赖。然后会从earlySingletonObjects中获取,如果这里也没有,并且允许创建早期对象的话,会从singletonFactories中获取,如果有旧调用getObject方法,创建一个早期的并且经过aop的对象,并把它加到earlySingletonObjects中,移出singletonFactories
Spring中一些概念的总结
对象和Bean的区别?
个人观点:所谓的bean也是一个java对象,只不过这个对象是通过spring定义的,而一开始就是通过
普通对象和Bean对象还有其他区别,因为Bean对象是由Spring生成的,Spring在生成Bean对象的过程中,会历经很多其他步骤,比如属性注入,aop,new实例,调用初始化方法。
如何理解BeanDefinition?
顾名思义,BeanDefinition是用来描述一个Bean的,Spring会根据BeanDefinition来生成一个Bean。
BeanFactory和FactoryBean的区别
BeanFactory
BeanFactory是Spring IOC容器的顶级接口,其实现类有XMLBeanFactory,DefaultListableBeanFactory以及AnnotationConfigApplicationContext等。BeanFactory为Spring管理Bean提供了一套通用的规范。接口中提供的一些方法如下:
boolean containsBean(String beanName)
Object getBean(String)
Object getBean(String, Class)
Class getType(String name)
boolean isSingleton(String)
String[] getAliases(String name)
可以通过BeanFactory获得Bean。
FactoryBean
FactoryBean首先也是一个Bean,但不是简单的Bean,而是一个能生产对象的工厂Bean,可以通过定义FactoryBean中的getObject()方法来创建生成过程比较复杂的Bean。
如何理解BeanFactoryPostProcessor?
BeanFactoryPostProcessor也叫做BeanFactory后置处理器。这里包括两个概念,一个是BeanFactory,一个是后置处理器。
BeanFactory表示Bean工厂,可以基于BeanDefinition来生成Bean对象,所以在BeanFactory中存在所有的BeanDefinition。
后置处理器可以理解为:当某物品生产好了以后,可以进一步通过后置处理器来对此物品进行处理。
所以BeanFactoryPostProcessor可以理解为,可以得到BeanFactory对象并对它进行处理,比如修改它其中的某个BeanDefinition,或者直接向BeanFactory中添加某个对象作为bean。
如何理解BeanDefinitionRegistryPostProcessor?
BeanDefinitionRegistryPostProcessor是一个接口,继承了BeanFactoryPostProcessor,所以它也是一个BeanFactory后置处理器,所以它可以操作BeanFactory。
它特殊的地方在于,它拥有的功能比BeanFactoryPostProcessor多,比如BeanFactoryPostProcessor是不能向BeanFactory中添加BeanDefinition的(只能添加Bean对象),但是BeanDefinitionRegistryPostProcessor是可以向BeanFactory中添加BeanDefinition的。
如何理解@Import与ImportBeanDefinitionRegistrar?
Import注解
@Import首先是一个注解,在Spring中是用来向Spring容器中导入Bean的。换个角度理解,就是我们一般都是通过在某个类上加上@Component注解来标志一个bean的,但如果我们希望以一种更灵活的方式去定义bean的话,就可以利用@Import注解。
@Import注解所指定的类,在Spring启动过程中会对指定的类进行判断,判断当前类是不是实现了比较特殊的接口,比如ImportBeanDefinitionRegistrar,如果存在特殊的接口就执行特殊的逻辑,如果没有则生成该类对应的BeanDefinition并放入BeanFactory中。
ImportBeanDefinitionRegistrar
通过Import注解可以注册bean,虽然它也支持同时注册多个bean,但是不方便,特别是当我们想通过实现一些复杂逻辑来注册bean的话,仅仅通过Import注解是不方便的,这时就可以使用ImportBeanDefinitionRegistrar这个接口来动态的注册bean了,我这里说的注册bean指的是:通过生成BeanDefinition,并且把BeanDefinition放入BeanFactory中。
如何理解BeanDefinitionRegistry和BeanFactory?
BeanFactory表示Bean工厂,可以利用BeanFactory来生成bean。
BeanDefinitionRegistry表示BeanDefinition的注册表,可以用来添加或移除BeanDefinition。
Spring依赖注入原理分析(未完成)
Spring中有几种依赖注入的方式?
** **
这是一个面试高频题,但是我在面程序员的时候,听过很多种答案。那么标准答案是什么?我们先不说,一步步来分析。
什么是依赖注入
首先,我们得知道什么是依赖注入?就是填充属性。
一个对象通常都会有属性,比如:
public class OrderService {
private UserService userService;
public UserService getUserService() {
return userService;
}
}
OrderService中有一个属性UserService, UserService就是OrderService的依赖。
那么Spring的依赖注入,就是Spring框架去进行属性的填充。那么我们就要站在Spring的角度去思考:如果你是Spring的开发者,如果实现对一个对象的属性进行填充?
** **
在进行属性填充之前,我们得先知道:在一个对象中,哪些属性可以进行填充?
肯定是需要业务开发者去告诉程序员的,比如在属性上加一个特定的注解,比如Spring中的@Autowired。当Spring遇到该属性时,发现该属性存在这个注解,Spring就会对当前这个属性进行填充。那么怎么填充呢?
填充其实就是对属性进行赋值,那么Spring能怎么对这个属性进行赋值呢?赋的什么值呢?
假设赋的值是xx。我们先考虑如果把这个xx赋值给OrderService对象。
可能我们立马能想到的就是:
orderService.userService = xx;
这个思路没错,但是不能满足所有情况,因为orderService这个对象是在Spring中实例化的,userService这个属性的权限修饰符是private,所以在Spring中不能直接进行赋值,但是可以通过反射,比如:
// 随便new一个表示xx,Spring中寻找要注入的值是一个比较复杂的过程
UserService xx = new UserService();
Class c= Class.forName("com.luban.service.OrderService");
Object cInstance = c.newInstance();
Field[] fields = c.getDeclaredFields();
fields[0].setAccessible(true); // fields[0]表示的就是userServce属性
fields[0].set(cInstance, xx);
System.out.println(((OrderService)cInstance).getUserService());
这样,通过反射就能对属性进行赋值了。那么怎么寻找到准确的应该赋值给该属性的值呢?
上文中的xx肯定也是一个对象,也就是说是Spring中的一个bean,那么Spring该如何根据当前属性去找到对应的bean呢?只有两种方式:
- 根据属性的名字
- 根据属性的类型
根据属性的名字去Spring容器中去找bean,要么找不到,要么就能找到一个bean,因为Spring中的beanName是唯一的。
格局属性的类型去Spring容器中去找bean,要么找不到,要么可能找到一个或多个bena,因为Spring容器中的bean实际就是一个对象,而一个类型是可以有多个对象的,在Spring容器中也是如此。
那么Spring针对这两种方式会如何选择呢?二选一,还是二合一。
答案很明显,肯定是二合一,一种方式找不到就利用另外一个方式去找。那么两种方式中会优先利用哪种方式去找?
答案很明显,肯定是先利用属性的名字,因为利用名字去找更精确。
byName
根据属性名,去
byType
Spring整合Mybatis原理
在介绍Spring整合Mybatis原理之前,我们得先来稍微介绍Mybatis的工作原理。
Mybatis的基本工作原理
在Mybatis中,我们可以使用一个接口去定义要执行sql,简化代码如下:
定义一个接口,@Select表示要执行查询sql语句。
public interface UserMapper {
@Select("select * from user where id = #{id}")
User selectById(Integer id);
}
以下为执行sql代码:
InputStream inputStream = Resources.getResourceAsStream("mybatis.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
// 以下使我们需要关注的重点
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Integer id = 1;
User user = mapper.selectById(id);
Mybatis的目的是:使得程序员能够以调用方法的方式执行某个指定的sql,将执行sql的底层逻辑进行了封装。
** **
这里重点思考以下mapper这个对象,当调用SqlSession的getMapper方法时,会对传入的接口生成一个代理对象,而程序要真正用到的就是这个代理对象,在调用代理对象的方法时,Mybatis会取出该方法所对应的sql语句,然后利用JDBC去执行sql语句,最终得到结果。
分析需要解决的问题
Spring和Mybatis时,我们重点要关注的就是这个代理对象。因为整合的目的就是:把某个Mapper的代理对象作为一个bean放入Spring容器中,使得能够像使用一个普通bean一样去使用这个代理对象,比如能被@Autowire自动注入。
** **
比如当Spring和Mybatis整合之后,我们就可以使用如下的代码来使用Mybatis中的代理对象了:
@Component
public class UserService {
@Autowired
private UserMapper userMapper;
public User getUserById(Integer id) {
return userMapper.selectById(id);
}
}
** **
UserService中的userMapper属性就会被自动注入为Mybatis中的代理对象。如果你基于一个已经完成整合的项目去调试即可发现,userMapper的类型为:org.apache.ibatis.binding.MapperProxy@41a0aa7d。证明确实是Mybatis中的代理对象。
好,那么现在我们要解决的问题的就是:如何能够把Mybatis的代理对象作为一个bean放入Spring容器中?
要解决这个,我们需要对Spring的bean生成过程有一个了解。
Spring中Bean的产生过程
Spring启动过程中,大致会经过如下步骤去生成bean
- 扫描指定的包路径下的class文件
- 根据class信息生成对应的BeanDefinition
- 在此处,程序员可以利用某些机制去修改BeanDefinition
- 根据BeanDefinition生成bean实例
- 把生成的bean实例放入Spring容器中
假设有一个A类,假设有如下代码:
一个A类:
@Component
public class A {
}
一个B类,不存在@Component注解
public class B {
}
执行如下代码:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
System.out.println(context.getBean("a"));
输出结果为:com.luban.util.A@6acdbdf5
A类对应的bean对象类型仍然为A类。但是这个结论是不确定的,我们可以利用BeanFactory后置处理器来修改BeanDefinition,我们添加一个BeanFactory后置处理器:
@Component
public class LubanBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
BeanDefinition beanDefinition = beanFactory.getBeanDefinition("a");
beanDefinition.setBeanClassName(B.class.getName());
}
}
这样就会导致,原本的A类对应的BeanDefiniton被修改了,被修改成了B类,那么后续正常生成的bean对象的类型就是B类。此时,调用如下代码会报错:
context.getBean(A.class);
但是调用如下代码不会报错,尽管B类上没有@Component注解:
context.getBean(B.class);
并且,下面代码返回的结果是:com.luban.util.B@4b1c1ea0
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
System.out.println(context.getBean("a"));
之所以讲这个问题,是想说明一个问题:在Spring中,bean对象跟class没有直接关系,跟BeanDefinition才有直接关系。
那么回到我们要解决的问题:如何能够把Mybatis的代理对象作为一个bean放入Spring容器中?
** **
在Spring中,如果你想生成一个bean,那么得先生成一个BeanDefinition,就像你想new一个对象实例,得先有一个class。
** **
解决问题
继续回到我们的问题,我们现在想自己生成一个bean,那么得先生成一个BeanDefinition,只要有了BeanDefinition,通过在BeanDefinition中设置bean对象的类型,然后把BeanDefinition添加给Spring,Spring就会根据BeanDefinition自动帮我们生成一个类型对应的bean对象。
所以,现在我们要解决两个问题:
- Mybatis的代理对象的类型是什么?因为我们要设置给BeanDefinition
- 我们怎么把BeanDefinition添加给Spring容器?
** **
注意:上文中我们使用的BeanFactory后置处理器,他只能修改BeanDefinition,并不能新增一个BeanDefinition。我们应该使用Import技术来添加一个BeanDefinition。后文再详细介绍如果使用Import技术来添加一个BeanDefinition,可以先看一下伪代码实现思路。
假设:我们有一个UserMapper接口,他的代理对象的类型为UserMapperProxy。
那么我们的思路就是这样的,伪代码如下:
BeanDefinitoin bd = new BeanDefinitoin();
bd.setBeanClassName(UserMapperProxy.class.getName());
SpringContainer.addBd(bd);
但是,这里有一个严重的问题,就是上文中的UserMapperProxy是我们假设的,他表示一个代理类的类型,然而Mybatis中的代理对象是利用的JDK的动态代理技术实现的,也就是代理对象的代理类是动态生成的,我们根本无法确定代理对象的代理类到底是什么。
所以回到我们的问题:Mybatis的代理对象的类型是什么?
** **
本来可以有两个答案:
- 代理对象对应的代理类
- 代理对象对应的接口
** **
那么答案1就相当于没有了,因为是代理类是动态生成的,那么我们来看答案2:代理对象对应的接口
如果我们采用答案2,那么我们的思路就是:
BeanDefinition bd = new BeanDefinitoin();
// 注意这里,设置的是UserMapper
bd.setBeanClassName(UserMapper.class.getName());
SpringContainer.addBd(bd);
但是,实际上给BeanDefinition对应的类型设置为一个接口是行不通的,因为Spring没有办法根据这个BeanDefinition去new出对应类型的实例,接口是没法直接new出实例的。
那么现在问题来了,我要解决的问题:Mybatis的代理对象的类型是什么?
两个答案都被我们否定了,所以这个问题是无解的,所以我们不能再沿着这个思路去思考了,只能回到最开始的问题:如何能够把Mybatis的代理对象作为一个bean放入Spring容器中?
总结上面的推理:我们想通过设置BeanDefinition的class类型,然后由Spring自动的帮助我们去生成对应的bean,但是这条路是行不通的。
终极解决方案
那么我们还有没有其他办法,可以去生成bean呢?并且生成bean的逻辑不能由Spring来帮我们做了,得由我们自己来做。
FactoryBean
有,那就是Spring中的FactoryBean。我们可以利用FactoryBean去自定义我们要生成的bean对象,比如:
@Component
public class LubanFactoryBean implements FactoryBean {
@Override
public Object getObject() throws Exception {
Object proxyInstance = Proxy.newProxyInstance(LubanFactoryBean.class.getClassLoader(), new Class[]{UserMapper.class}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 执行代理逻辑
return null;
}
}
});
return proxyInstance;
}
@Override
public Class<?> getObjectType() {
return UserMapper.class;
}
}
** **
我们定义了一个LubanFactoryBean,它实现了FactoryBean,getObject方法就是用来自定义生成bean对象逻辑的。
执行如下代码:
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
System.out.println("lubanFactoryBean: " + context.getBean("lubanFactoryBean"));
System.out.println("&lubanFactoryBean: " + context.getBean("&lubanFactoryBean"));
System.out.println("lubanFactoryBean-class: " + context.getBean("lubanFactoryBean").getClass());
}
}
将打印:
lubanFactoryBean: com.luban.util.LubanFactoryBean$1@4d41cee
&lubanFactoryBean: com.luban.util.LubanFactoryBean@3712b94
lubanFactoryBean-class: class com.sun.proxy.$Proxy20
从结果我们可以看到,从Spring容器中拿名字为”lubanFactoryBean”的bean对象,就是我们所自定义的jdk动态代理所生成的代理对象。
所以,我们可以通过FactoryBean来向Spring容器中添加一个自定义的bean对象。上文中所定义的LubanFactoryBean对应的就是UserMapper,表示我们定义了一个LubanFactoryBean,相当于把UserMapper对应的代理对象作为一个bean放入到了容器中。
但是作为程序员,我们不可能每定义了一个Mapper,还得去定义一个LubanFactoryBean,这是很麻烦的事情,我们改造一下LubanFactoryBean,让他变得更通用,比如:
@Component
public class LubanFactoryBean implements FactoryBean {
// 注意这里
private Class mapperInterface;
public LubanFactoryBean(Class mapperInterface) {
this.mapperInterface = mapperInterface;
}
@Override
public Object getObject() throws Exception {
Object proxyInstance = Proxy.newProxyInstance(LubanFactoryBean.class.getClassLoader(), new Class[]{mapperInterface}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 执行代理逻辑
return null;
}
}
});
return proxyInstance;
}
@Override
public Class<?> getObjectType() {
return mapperInterface;
}
}
改造LubanFactoryBean之后,LubanFactoryBean变得灵活了,可以在构造LubanFactoryBean时,通过构造传入不同的Mapper接口。
实际上LubanFactoryBean也是一个Bean,我们也可以通过生成一个BeanDefinition来生成一个LubanFactoryBean,并给构造方法的参数设置不同的值,比如伪代码如下:
BeanDefinition bd = new BeanDefinitoin();
// 注意一:设置的是LubanFactoryBean
bd.setBeanClassName(LubanFactoryBean.class.getName());
// 注意二:表示当前BeanDefinition在生成bean对象时,会通过调用LubanFactoryBean的构造方法来生成,并传入UserMapper
bd.getConstructorArgumentValues().addGenericArgumentValue(UserMapper.class.getName())
SpringContainer.addBd(bd);
特别说一下注意二,表示表示当前BeanDefinition在生成bean对象时,会通过调用LubanFactoryBean的构造方法来生成,并传入UserMapper的Class对象。那么在生成LubanFactoryBean时就会生成一个UserMapper接口对应的代理对象作为bean了。
到此为止,其实就完成了我们要解决的问题:把Mybatis中的代理对象作为一个bean放入Spring容器中。只是我们这里是用简单的JDK代理对象模拟的Mybatis中的代理对象,如果有时间,我们完全可以调用Mybatis中提供的方法区生成一个代理对象。这里就不花时间去介绍了。
Import
到这里,我们还有一个事情没有做,就是怎么真正的定义一个BeanDefinition,并把它添加到Spring中,上文说到我们要利用Import技术,比如可以这么实现:
定义如下类:
public class LubanImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition();
AbstractBeanDefinition beanDefinition = builder.getBeanDefinition();
beanDefinition.setBeanClass(LubanFactoryBean.class);
beanDefinition.getConstructorArgumentValues().addGenericArgumentValue(UserMapper.class);
// 添加beanDefinition
registry.registerBeanDefinition("luban"+UserMapper.class.getSimpleName(), beanDefinition);
}
}
并且在AppConfig上添加@Import注解:
@Import(LubanImportBeanDefinitionRegistrar.class)
public class AppConfig {
这样在启动Spring时就会新增一个BeanDefinition,该BeanDefinition会生成一个LubanFactoryBean对象,并且在生成LubanFactoryBean对象时会传入UserMapper.class对象,通过LubanFactoryBean内部的逻辑,相当于会自动生产一个UserMapper接口的代理对象作为一个bean。
总结
总结一下,通过我们的分析,我们要整合Spring和Mybatis,需要我们做的事情如下:
- 定义一个LubanFactoryBean
- 定义一个LubanImportBeanDefinitionRegistrar
- 在AppConfig上添加一个注解@Import(LubanImportBeanDefinitionRegistrar.class)
优化
这样就可以基本完成整合的需求了,当然还有两个点是可以优化的
第一,单独再定义一个@LubanScan的注解,如下:
@Retention(RetentionPolicy.RUNTIME)
@Import(LubanImportBeanDefinitionRegistrar.class)
public @interface LubanScan {
}
这样在AppConfig上直接使用@LubanScan即可
第二,在LubanImportBeanDefinitionRegistrar中,我们可以去扫描Mapper,在LubanImportBeanDefinitionRegistrar我们可以通过AnnotationMetadata获取到对应的@LubanScan注解,所以我们可以在@LubanScan上设置一个value,用来指定待扫描的包路径。然后在LubanImportBeanDefinitionRegistrar中获取所设置的包路径,然后扫描该路径下的所有Mapper,生成BeanDefinition,放入Spring容器中。
所以,到此为止,Spring整合Mybatis的核心原理就结束了,再次总结一下:
- 定义一个LubanFactoryBean,用来将Mybatis的代理对象生成一个bean对象
- 定义一个LubanImportBeanDefinitionRegistrar,用来生成不同Mapper对象的LubanFactoryBean
- 定义一个@LubanScan,用来在启动Spring时执行LubanImportBeanDefinitionRegistrar的逻辑,并指定包路径
以上这个三个要素分别对象org.mybatis.spring中的:
- MapperFactoryBean
- MapperScannerRegistrar
- @MapperScan
JVM底层
Java的跨平台是如何实现的
Java是基于虚拟机栈运行的,
new不是原子性操作
JVM的四大模块
- 类加载子系统
- 内存模型
- 本地方法栈
- 虚拟机栈
- 程序计数器
- 堆
- 方法区
- 执行引擎
垃圾回收期
CPU位数︰32位、g64位
操作系统派系:Windows派系、Unix派系
- Unix派系:Mac、Centos、Ubuntu、Android
- 汇编指令:Intel汇编、AT&T汇编、ARM汇编
- 内存模型
Java文件首先要编译成class文件,那么在32位机和64位机器上编译的结果肯定是不一样
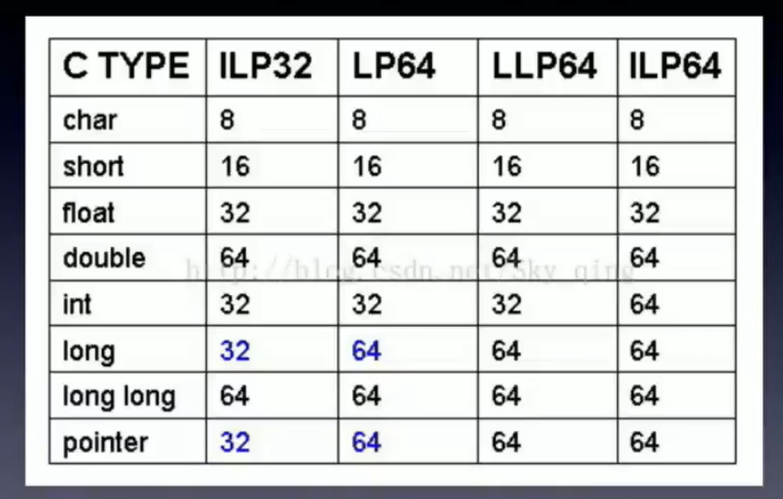
跨平台的本质就是汇编语言的不同

两种汇编风格(还有ARM汇编:主要用在移动设备上,手提电脑,手机,平板,叫做嵌入式系统)
Java底层的char是基于short的
Java的执行引擎是如何实现的:
字节码解析器:java代码—>C++代码—>汇编:效率太低,不如C++
模板解析器:java字节码–>汇编语言(效率提高了)
Java程序包括了
- 硬编码
- java字节码
- java程序
我们运行java程序run的时候发生了什么
- 调用javac编译整个java程序
- 调用java命令
jvm的初始化
- class文件
- 硬盘上的.class文件
- class content
- 内存中的一块区域,将.class读到内存中。放在直接内存中
- class对象
- 类加载子系统基于《Java虚拟机规范》进行解析
- class对象放在哪?
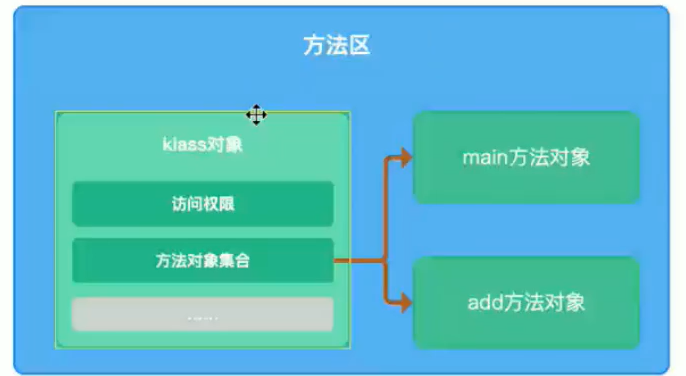
- 方法区:InstanceKlass存的是元信息:字符串,常量池,方法信息等
- 堆区:InstanceMirrorKlass:镜像类,是一个C++对象
- 对象
- new生成的对象(或反射等等方法)
方法区
经常会跟永久代,元空间放在一起,他们之间的关系是
- 方法区是规范,永久代、元空间是具体实现
- 方法区是接口,永久代、元空间是实现类
永久代、元空间是否同时存在同一个JVM中?否
永久代
- jdk8以前方法区的实现
- 堆中的
元空间
- jdk8以后方法区的实现
- 直接内存中的
为什么以元空间取代永久代?
- oom:元空间存放的是Klass文件信息,不可避免的会占用一些空间
- gc:既有对象,又有源信息。垃圾回收判断你很困难
- 受硬件限
- 32位机4G
- 内核2G
- 应用层2G
- 64位机= 16 +48(16位作为保留位,48位作为实际使用的位数)
- 2的64次方
- 2的48次方256T
- 32位机4G
元空间有什么缺点?
- 动态生成
元空间的调优
java -XX:+PrintFlagsFinal -version | grep ThreadStack
最小20.75M
最大 256T
元空间的调优
- 最大、最小设置成一样,防止内存抖动
- 大小设置成物理机器的1/32
- arthas、visualyM..
- 保存20% -30%的空间空余
本地方法栈
运行JNI程序需要的栈
虚拟机栈
数据结构栈有什么区别
一个是规范,一个是实现
JVM中有几个虚拟机栈?
- 一个线程一个,随线程的创建而创建,随线程的结束而销毁
- 线程独享
- 线程安全
一个虚拟机栈中有几个栈帧?
- 函数调用次数
栈中也会出现OOM
stackoverflow:所以也需要进行调优
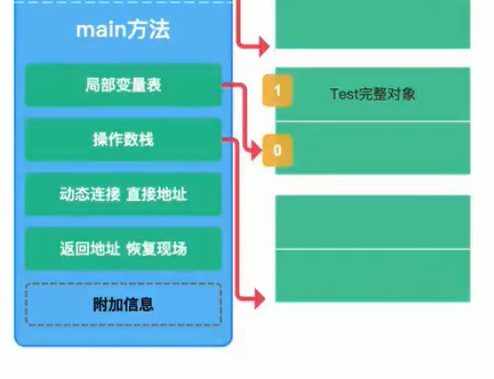
栈中的几个区域
- 局部变量表:
- 操作数栈
- 动态链接 直接地址:该方法在方法区中地址,方法的对象的指针
- 返回地址 恢复现场:(java中没有指针的概念,不像C和C++那样能直接指向硬件地址)
- 附加信息
轻量级锁(sync),也是基于栈
程序计数器
软件:OD
Java虚拟机时通过软件模拟出来的,C和C++是直接在硬件上运行的(基于寄存器)
寄存器中有一块区域叫EIP指的就是程序计数器,而java是通过程序模拟出来的我们没有程序计数器,在java中程序计数器就是java字节码前面的索引
程序计数器是由执行引擎进行改动的
main方法调用add方法栈帧发生了变化
- 创建add方法的栈帧
- main方法的程序计数器压入栈
- 局部表开始指针指向add方法栈帧中的局部变量表开始位置
- 操作数栈指针,指向add方法站怎中的操作数栈开始位置
逆向操作
add方法执行完后,发生了什么:
- 重置操作数栈指针
- 重置局部表指针
- 程序计数器赋值
- 返回值压入main方法的操作数栈中
- 销毁栈帧
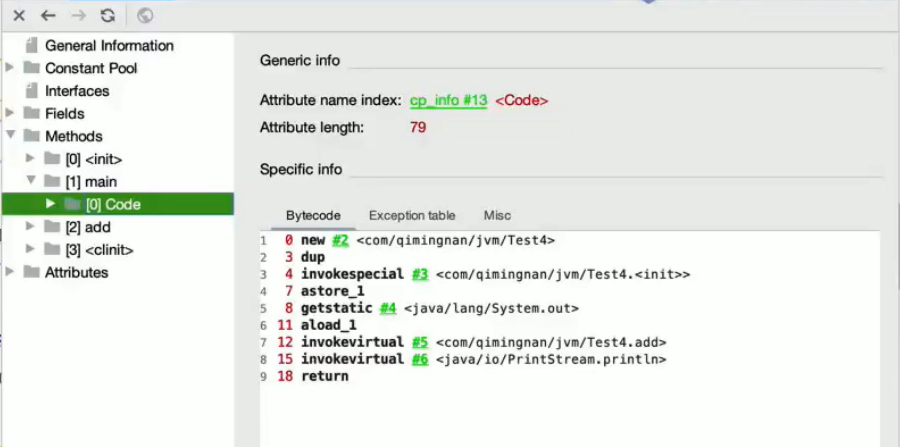
new一个对象的流程
//slot 插槽_模拟机栈里面每个格子
public class Test4 {
public static Test4 test4 = newTest4();
//形参、形式参数
//实参、实际参数
public static void main(String[] args) {
Test4 demo = new Test4();
//调用默认构造函数
class<Test4> clazz = Test4.class;
System.out.println(demo.add());
}
public int add() {
int a = 10;
int b = 20;
return a + b;
}
}
百度搜:字节码手册
0 new #2 <com/qimingnan/jvm/Test4>
创建空对象
3 dup
1、赋值栈顶元素
2、重新压入栈(为什么呢?后面的方法当this指针用)
4 invokespecial #3<com/qimingnan/jvm/Test4.<init>>
执行默认构造方法
完整对象
7 astore_1
1、将完整对象的指针pop出来
2、赋值给局部变量表中index=1的位置
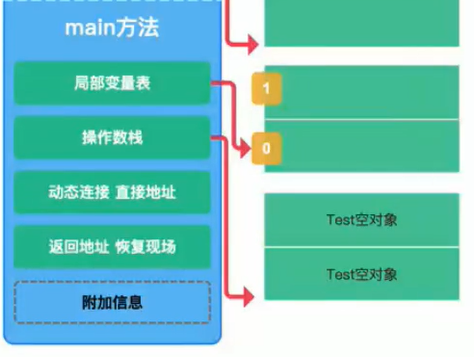
执行完构造方法后,对象在堆中创建
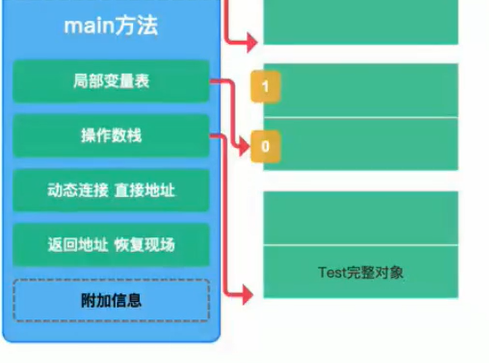
最后一步,pop出来赋值给index为1的位置
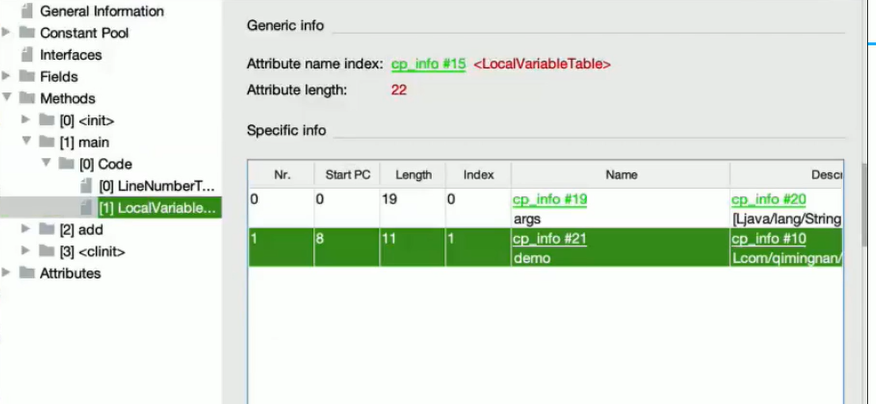
而局部变量表index为1的位置变量为demo,既Test4 demo = new Test4();执行完
这就可以解释为什么new 不是线程安全的,在字节码中它是由四步组成的
运行时数据区中的关系
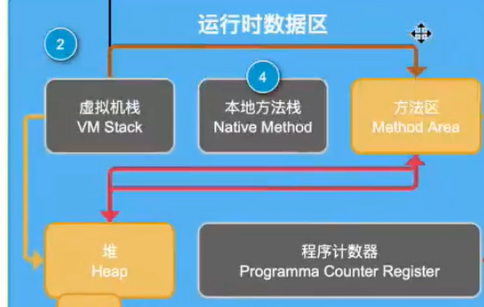
虚拟机栈指向方法区,该怎么理解?动态连接
虚拟机栈指向堆区,该怎么理解?对象引用
堆区指向方法区,该怎么理解?对象的内存布局
new出来的一个对象存储在堆中保存的样子是什么样子的?
其中的类型指针(Klass Pointer)堆区所有对象头中都有一个kp,这个kp指向方法区
方法区指向堆区,该如何理解?静态变量
常量池
- class文件中的常量池
- 运行时常量池
- 全局字符串引用
堆区最主要的就是调优
- 计算对象大小
- 指针压缩
- 调优实战
- 空间担保机制
- 动态年龄判断
java的根加载器其实不纯是c++实现的(C++ + Java来实现的)
调优
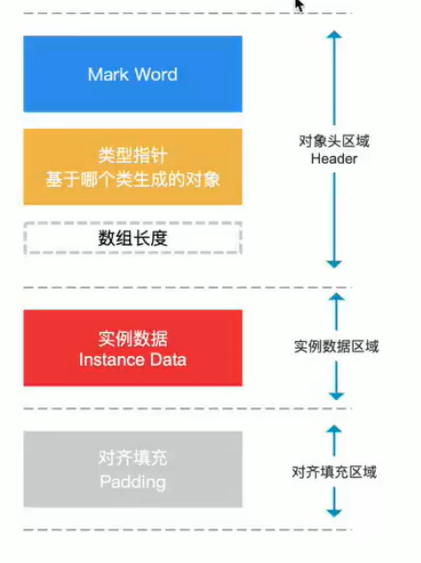
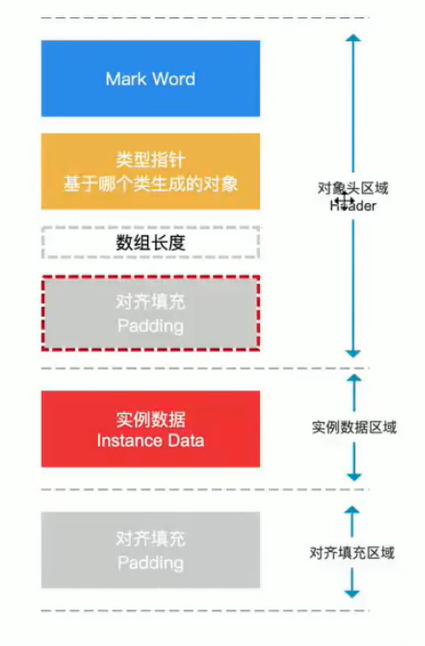
对象的内存布局
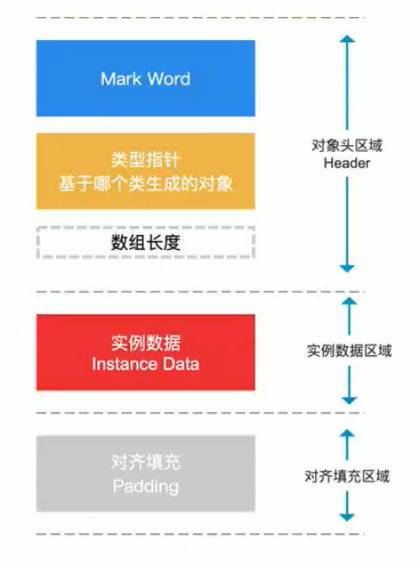
对象头(锁就与它有关)
64位机为例
- mark word:8字节 64bit
- 类型指针: 8字节(会变成4字节,在开启指针压缩的时候)
- 数组长度:4个字节(不是数组对象就为0)
- 实例数据:类的普通属性(不包括静态变量)
- 对齐填充:
java中所有的对象都是8字节对齐的
类型指针:对象所属类的class对象的内存地址
对其填充其实有两个部分组成
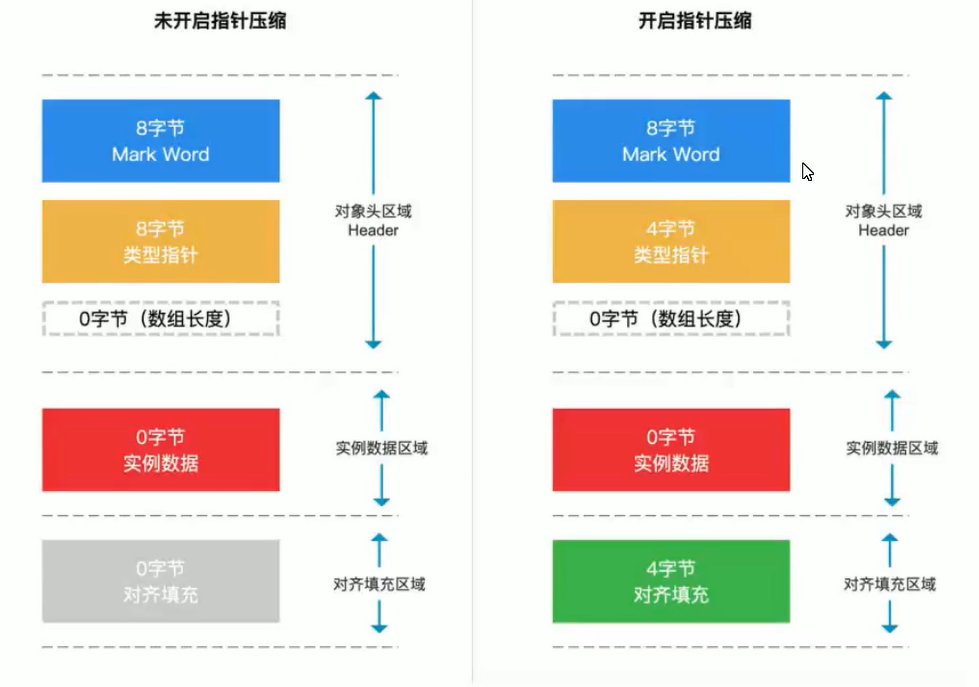
计算对象大小
指针压缩
jdk6默认是开启的
-XX:+/-UseCompressedOops
空对象占多少字节?
没有数据的对象叫空对象(没有普通属性)
- 开启指针压缩:16—–8(mark word)+4(类型指针)+4(填充空间)
- 未开启指针压缩:16
普通对象
public class Test{
int a=20;
int b=20;
}
- 开启:24(8+4+(4+4)+4)=24
- 关闭:24(8+8+(4+4))=24
指针压缩:将内存地址的8字节–>4字节,节省了空间,提升了寻址效率
public class Test{
int a=20;
int b=20;
static int[] arr={0,1,2};
}
- 开启:32
- 关闭:40
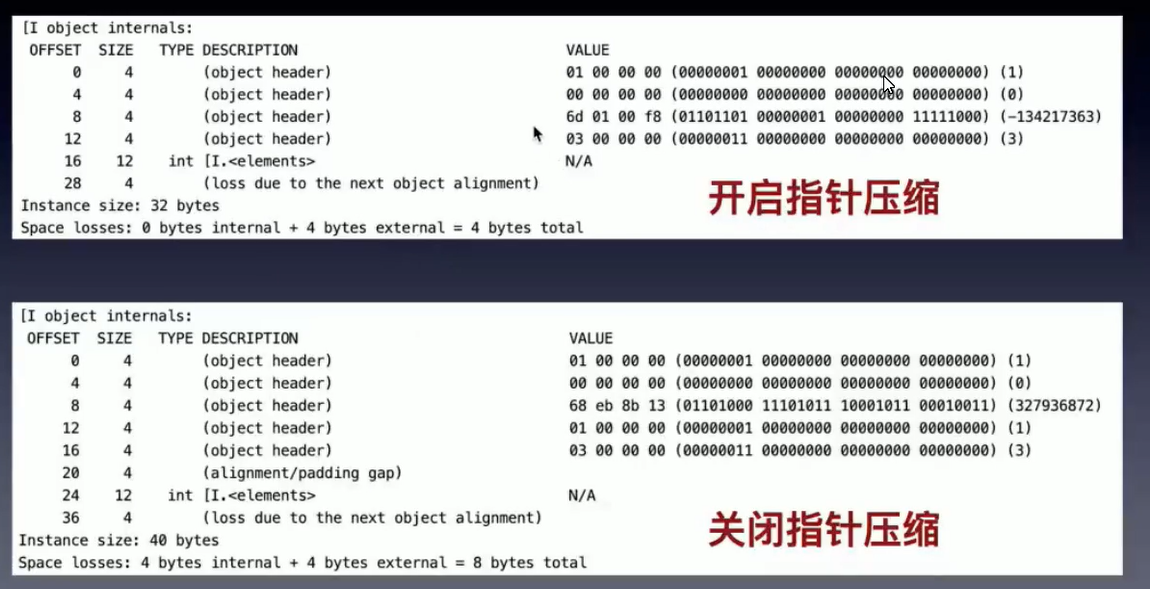
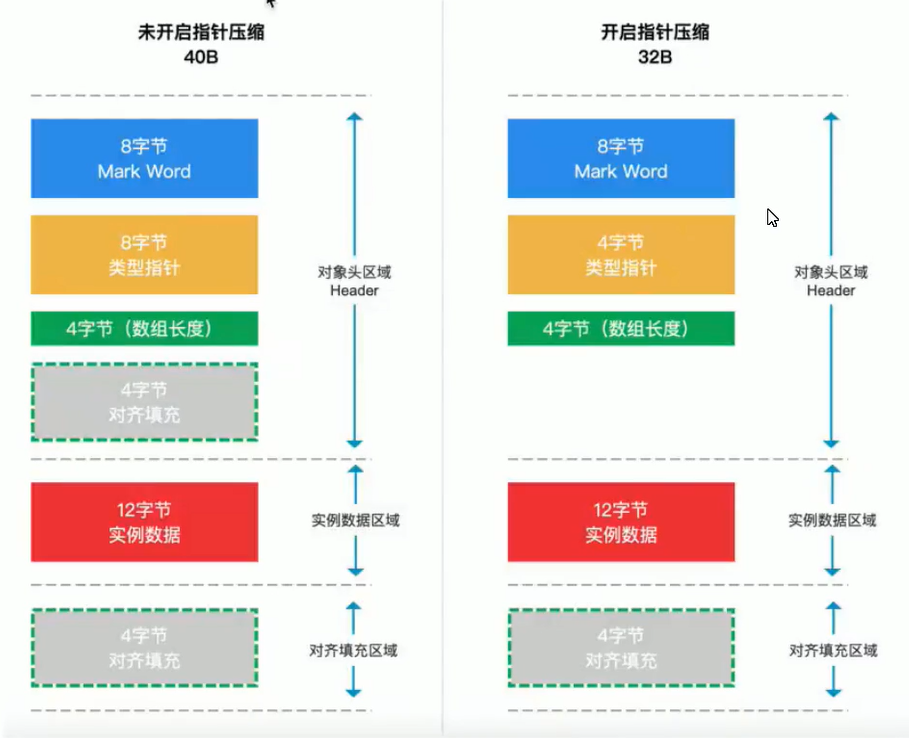
指针压缩
64bit机下,内存地址占8字节
8—>4到底是怎么存储的?使用过程中做了什么?
实现原理

test1=00 000
test2=10 000
test3=110 000
8字节对齐后三位永远是0
在存储的时候,去除3为,高位补0
test1=00
test2=10
test3=110
再用的时候增加三位,低位补0
test1=00 000
test2=10 000
test3=110 000
那么只是移动的3位,还少一位呢?
8字节–>4字节之后与32位机器又有什么差别呢?
我们使用了这样的技术
- 我们的性能一定要高于32位机器
- 留有一定的扩容的退路
对象实际上是占35位,按32位存储
oop不是面向对象的意思是对象指针的意思(ordinary object pointer)
oops:
开启指针压缩内存地址占4字节 32位,在使用的时候增加三位32+3
一个oop能支持的最大堆空间是多少?2^35
如何扩容?16字节对齐,
这个扩容是修改操作系统代码还是openjdk代码?openjdk
调优阶段
- 上线前
- 项目运行阶段
- 线上出现OOM
亿级流量秒杀系统JVM调优
一亿次访问
一个uv->20pv
访客=1亿/ 20约=500w
访客数/下单数
转化率是在10%
500w * 10% = 50w
40%的订单是在前两分钟完成下单的
50*30%= 15w订单
15w / 120s= 1200笔
从下单到支付完成,生成的对象占用多少内存
商品信息、订单信息、物流信息、积分信息、优惠券信息….
20KB
每秒系统生成的对象·200M = 1200 *20K
下单到支付对象要存在2s
32G内存机器 堆最大=8G(1/4)
新生代:2.7G
Eden:2.2G
from:270M
to:270M
老年代:5.3G
1G = 1000M
2700M
14s就会出发young gc
400M内存无法回收,from,to区只有200多M无法放下,会空间担保放到老年代中
400M进入老年代
一分钟左右老年代就会充满,出发full gc—
如何做调优?
不触发空间担保
GC
计算机在设计的时候分为了四层,但是在实际的使用的时候(win、linux)实际使用的是第0和第3层即(R0内核态,R3用户态)。那么在分配内存的时候为什么要从用户态切换到内核态呢?
内存中的 数据是存在内存条上面的,内存条是操作系统借助驱动去操作的,而我们应用层程序是没有能力去操作硬件的,所以只要你分配内存读写数据,都需要内核来起到一些作用,那么就必然需要从用户态切换到内核态。当你分配完内存,读写完数据的时候就要返回一些数据,那么就必然需要从内核态转为用户态
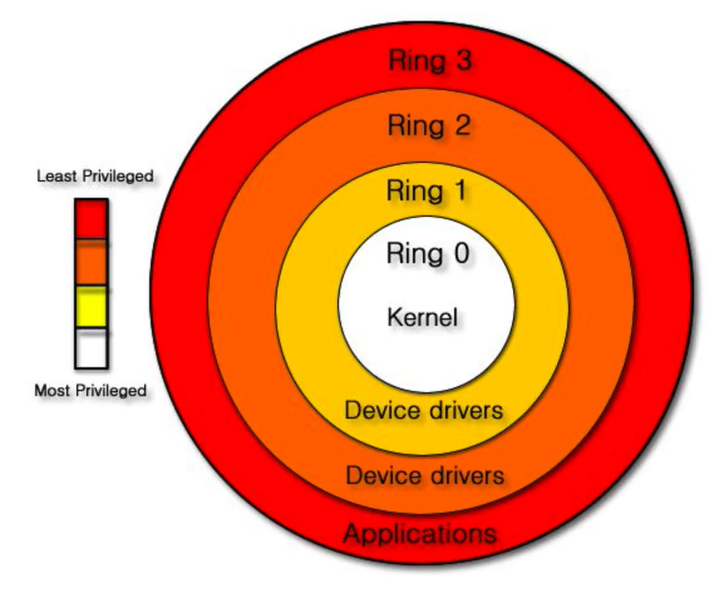
物理地址:一套算法将内存条映射成一套物理地址
线性地址:我们现在无论是进行分配内存还是引用传值传到内存啊,其实都是线性地址
线性地址又与物理地址之间有一层映射
内存池的结构
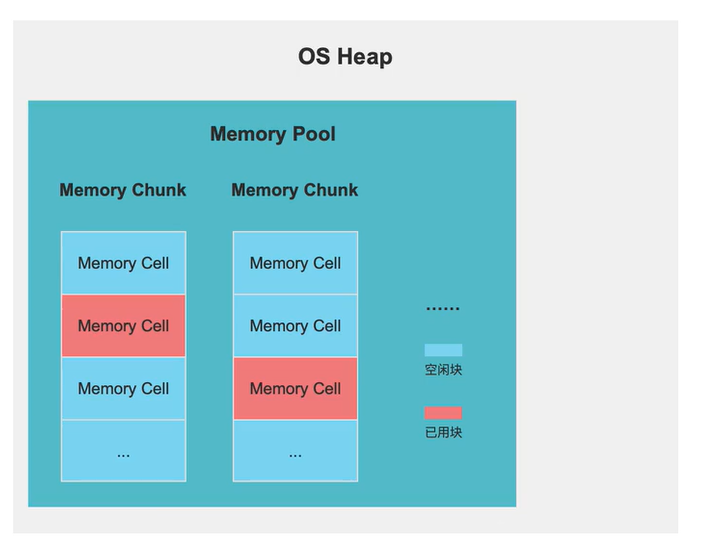
在分配内存的时候是在操作系统的堆上面来分配内存的,
memory pool:内存之,一个概念上的池子
memory chunk:操作系统块,一个内存池可以管理无数个内存块
内存池
class MemoryPool i
/**
*所有需要释放内存的成员
*/
pvate:
list<MemoryChunk*> m_chunks;//这个池子中所有的内存块
public:
~MemoryPool();
public:
/**
*创建新的Chunk
*@param mem_size
*@return
*/
MemoryChunk *new_chunk(uint mem_size);
public:
/**
*打印所有中Chunk
*/
void print_chunks();
/**
*释放所有Chunk占用的内存
*/
void free_chunks();
}
memory_chunk,真正操作系统分配的块
class MemoryChunk {
private:
/**
*创建Chunk的文件名,这个块是在哪一个文件中生成的
*/
char *m_filename;
/*
*创建Chunk的文件位置,块是在哪里被申请的
*/
uint m_line;
/**
*该Chunk的内存大小,内存块总体的大小
*/
uint m_size;
/**
*以多少字节对齐 一般是8字节对齐
*/
uint m_align_size;
/**
*该Chunk包含多少Cell
*/
uint m_cell_num;
/**
*被用了的Chunk数量
*/
uint m_used_cell_num;
/**
*需要释放内存的数据
*/
private:
/**
*存储数据的地方
*/
pvoid m_data;
list<Memorycell *> m_available_table;//记录还有多少内存可用
list<Memorycell *> m_used_table;//有多少被使用了
}
memory cell
class Memorycell {
private:
uint m_start;//cell从内存的哪里开始使用
uint m_end;//到哪里结束
╱**
*cell的数量,每个Cell占8字节
*/
uint m_size;
}
内存池快被用完了或者已经被用完了该怎么办?两种策略
- 进行内存的自动扩容
- 进行垃圾回收
GC算法
- 标记-清除算法:内存碎片化严重
- 标记-整理算法:会有stw(stop the world)问题
- 分代收集理论
- 标记-复制算法
- 基于Region的GC算法
内存池、GC算法、Java之间的关系
- JVM的内存结构是由它需要支持的GC算法决定的
- 根据GC算法理论,JVM的内存结构需要这样设计
GCroot对象,可达性分析
- 方法区中静态变量引用的对象
- 方法区中常量引用的对象
虚拟机栈中的局部变量表中引用的对象:把当前还在用的对象及对象引用的对象给扫出来
本地方法JNI引用的对象
Volatile
JVM三大执行引擎
- 字节码解释器
- 模板解释器
- JIT优化技术
证明可见性
public class Test3 i
//编译成java字节码
public static volatile int found = 0;
public static void main(String[] args){
new Thread(()-> {
System.out.println("筹基友送笔来...");
while (e == found){}
System.out.println("笔来了,开始写字...");
},"我线程").start();
new Thread(()->{
try {
Thread.sleep(2000);
}catch (InterruptedException e){
e.printstackTrace();
}
System.out.println("基友找到笔了,送过去...");
change();
},"基友线程").start();
}
public static void change(
found = 1;
}
}
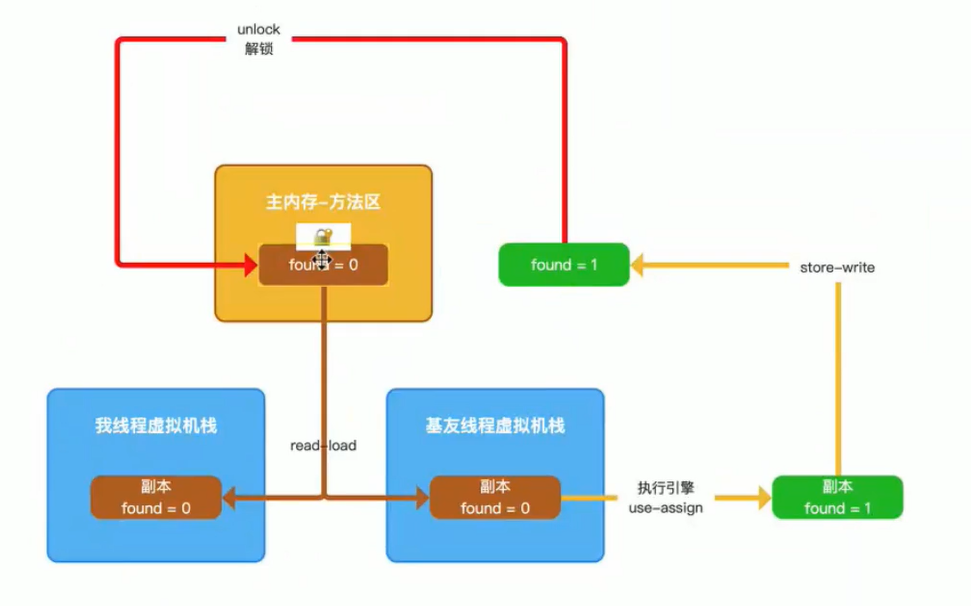
volatile是如何保证线程的可见性的? 加volatile,会写主内存
执行引擎的一般的结构
while() {
switch() {
case getstatic:
break;
case putstatic:
break;
}
}
读volatile修饰的变量getstatic
CASE(_getstatic):
if (cache->is_volatile(){
.....
if (tos_type =- atos) {
....
}else if (tos_type == itos){
SET_STACK_INT(obj->int_field_acquire(field_offset), -12;
}
每次读volatile修饰的共享变量都会从主内存中读取,然后在工作内存中生成一个副本
错误认知:读取volatile修饰的共享变量时会去判断工作内存中是否有这个变量,没有就拷贝生成副本,有就直接用
#define SET_STACK_INT(value,offset)
(*((jint*)&topOfStack[-(offset)]) = (value))
inline jint oopDesc::int_field_acquire(int offset) const {
return OrderAccess::load_acquire(int_field_addr(offset));
}
inline jbyte OrderAccess ::load_acquire(volatile jbyte* p){
return*p;
}
这种认知是错误的:
第一次读的时候,从主存中读取,然后在工作内存中生成副本以后读,会先判断工作内存中是否有该数值。栈只有入栈和出线,那么该如何去判断栈中有没有这个数值?
写volatile修饰的变量putstatic
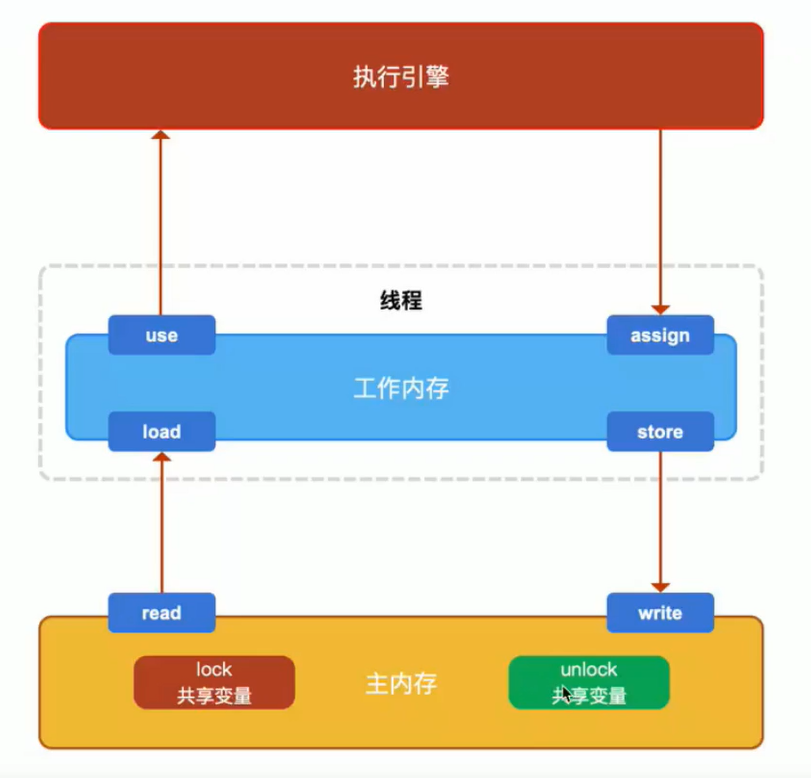
内存间交互操作
- lock(主内存,将一个变量标识为线程独占)
- unlock(主内存,释放一个处于锁定状态的变量)
- read(主内存,将变量从主内存传输到工作内存)
- load(工作内存,将read读到的值在工作内存中生成一个副本)
- use(工作内存,将工作内存中的变量传递给执行引擎)
- assign(工作内存,将执行引擎返回的值赋值给工作内存中的变量)
- store (工作内存,将工作内存中变量的值传输给主内存)
- ·write(主内存,将store操作从工作内存中传输的值写入主内存的变量中)
openjdk源码
CASE(_putfield):
CASE(_putstatic):
{
//Now store the result
......
int field_offset = cache->f2_as_index();
if (cache->is_volatile(){//判断是不是volatile
if (tos_type == itos){//是不是int类型的
obj->release_int_field_put(field_offset,STACK_INT(-1));
}
.....
OrderAccess::storeload();内存屏障
1、这边写的是哪个区域:1CPU缓存?2主内存?3工作内存? 2、解释概念︰主内存、工作内存
inline void OrderAccess::release_store(volatile juint* p,juint v){
*p = v;
}
inline void OrderAccess: :storeload{
fence();
}
inline void OrderAccess:: fence(){
if (os: :is_MP()){
//always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)": : : "cc" ,"memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)": : : "cc","memory");
#endif
}
}
inline void oopDesc::release_int_field_put(int offset,jint contents){
OrderAccess::release_store(int_field_addr(offset), contents);
}
cas是原子性操作,会交换8字节 是一个底层的指令,所以会保证原子性
读
每次都会从主内存中取数据
理解volatile,核心是理解volatile的写
写
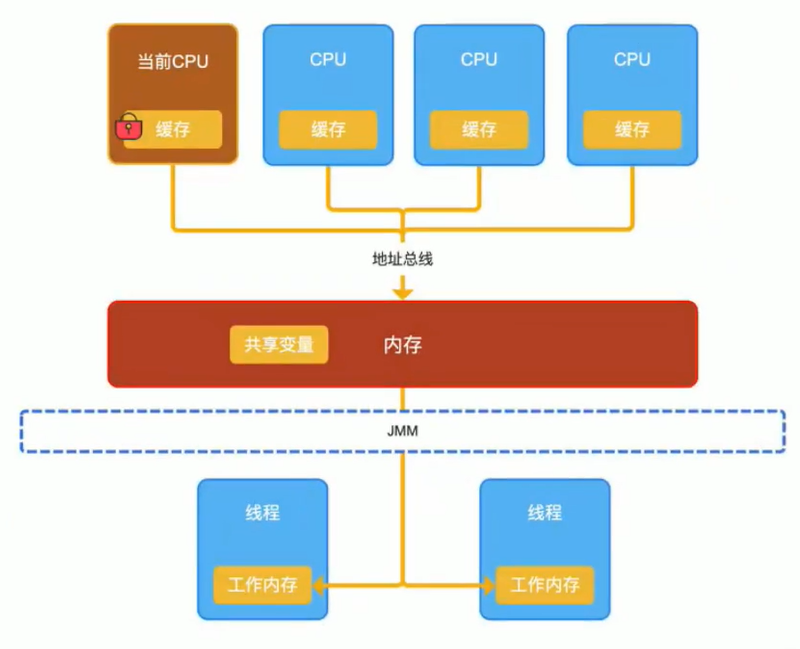
关于内存的几个名词
- 操作系统层面:操作系统内存、本地内存、native memory、OS内存
- JVM内存模型层面:堆、方法区、虚拟机栈、本地方法栈、程序计数器
- Java内存模型层面:主内存、工作内存
指的都是操作系统内存,只不过在不同的场景下面它的名词不一样而已
操作系统层面:内存条,物理内存
JVM内存模型,事实上就是操作系统的一个内存池,而jvm有将这个内存池划分成了各个区域,赋予了新的名词
主内存=堆区+方法区
工作内存=虚拟机栈
JVM内存模型:工作内存、主内存
JMM:java内存模型,在多线程方面。书===JSP-133规范,JMM是基于它的实现
volatile是如何保证有序性的
禁止指令重排
你能不能给我看看进制指令重排长啥样子?
加、不加volatile,你们觉得字节码是不是一样的?一样的
加volatile
0 iconst_1
1 putstatic #11 <com/qimingnan/concurrent/Test3.found>
4 return
不加volatile
0 iconst_1
1 putstatic #11 <com/qimingnan/concurrent/Test3.found>
4 return
那JVM是如何知道我写的是volatile修饰的变量?
内联汇编
asm__volatile ("lock; addl $0,0(%%rsp)" : : : "cc","memory");
即是编译屏障
既是编译屏障
也是内存屏障
class字节码文件
access flag 这个属性
cache->is_volatile() //会先判断这个变量是不是被volatile所修饰
没加volatile
加了volatile的变量
指令重排
编译期指令重排:
- Java字节码层面(没有做)
- openJDK源码层面(做了gcc -02这个优化)有些代码我不希望编译器做优化,需要编译器给我提供策略—>编译屏障
运行期指令重排
1. CPU乱序执行带来的(DCL+volatile来举例)
DCL为什么要加volatile?
为什么new不是原子操作?
new的四步操作(正常流程,没有被乱序执行)
33 new #4 <com/qimingnan/concurrent/DCLTest>
在堆区(或TLAB)分配内存,生成一个不完全对象(空壳子)
将不完全对象的引用压入栈顶
36 dup
复制栈顶元素
将复制的数值压入栈顶(作为this指针来使用)
37 invokespecial #10 <com/qimingnan/concurrent/DCLTest.<init>>
执行构造方法,this指针
堆区(TLAB)中的对象就是一个完整的对象(执行了构造方法)
40 putstatic #3 <com/qimingnan/concurrent/DCLTest.instance>
将完整对象的引用赋值给方法区的共享变量instance
因为40跟37之间没有任何的联系,所以有一定的概率会发生指令重排。
有的线程拿到的对象引用其实是不完全对象的引用
这就是DCL+volatile的原因
CPU乱序执行,带来运行期的指令重排现象
- 有的代码可以乱序执行
- 有的代码不能乱序执行
有一个保证:as-if-serial语义
跟在单线程环境下的运行结果是一样的
int a = 0;
int b = 10;
a = 20;
int sum = a + b;
不能是这样的
int a = 0;
int b = 10;
int sum = a + b;
a = 20;
happens-before原则
JVM在设计的时候,有些逻辑的先后顺序是可以执行的,那在JVM实现的那刻,就内置在JVM中了。
比如:new的执行要先于finalize方法前执行完成
有些逻辑是无法提前知晓的
需要JVM提供机制,由程序猿根据业务去控制
这就引出了:内存屏障(jvm是借助cpu提供的机制封装实现出来的)
- 编译屏障(编译期的指令重排)
- 内存屏障(运行期的指令重排)
cpu的指令有:
- fence族:sfence、lfence、mfence(串行化读写,队列化读写)
- lock指令(JVM采用的)
- 领定地址总线
- 保证读写有序性
内存屏障锁的就是地址总线
内存屏障作用于CPU内部
为什么要设计内存屏障?
- 因为CPU写内存的机制(会有一定的延迟)
- write through异步写(cpu的主流做法)
- CPU讲写请求写入store buffer中
- CPU空闲的时候将写的数据输入内存
- write back 同步写
- CPU将写请求写入store buffer,然后再刷回内存
- write through异步写(cpu的主流做法)
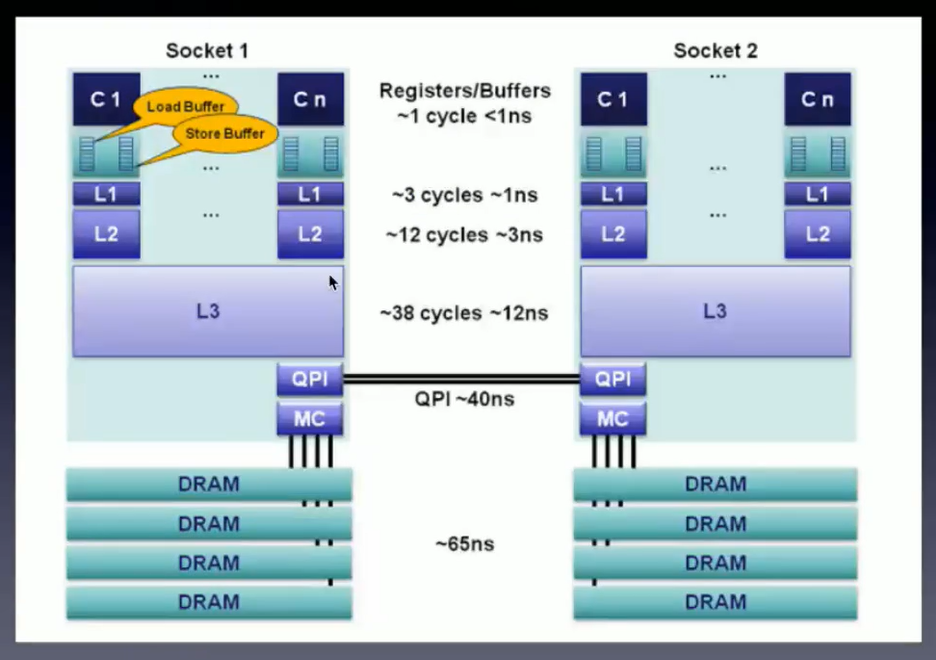
加了内存屏障,保证了读写的有序性,异步写,达到了同步写的效果,这就是为什么需要内存屏障?内存屏障作用于CPU内部,内存屏障的两个功能
Synchronized
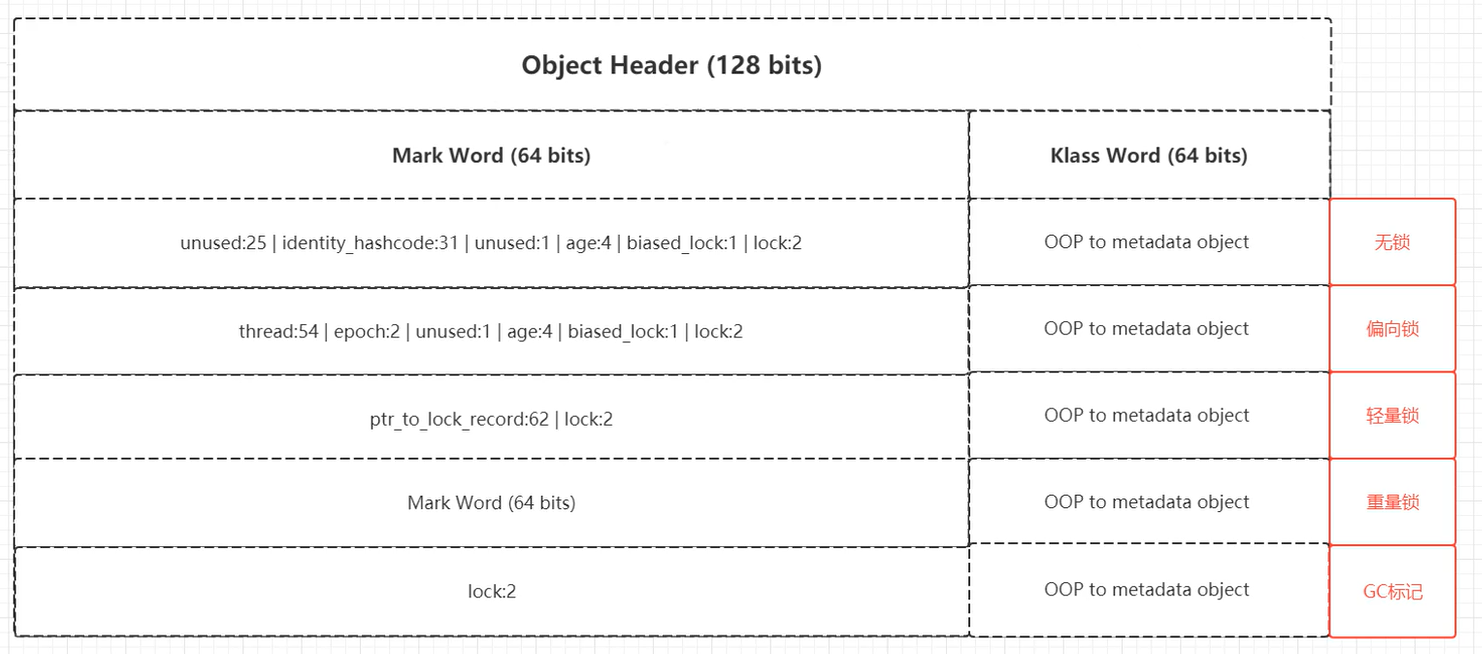
Synchronized锁的一定是对象,而不是代码块。锁加在了对象(对象头,实例数据、对齐填充组成)的对象头
使用jol工具包可以打印一个对象的信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
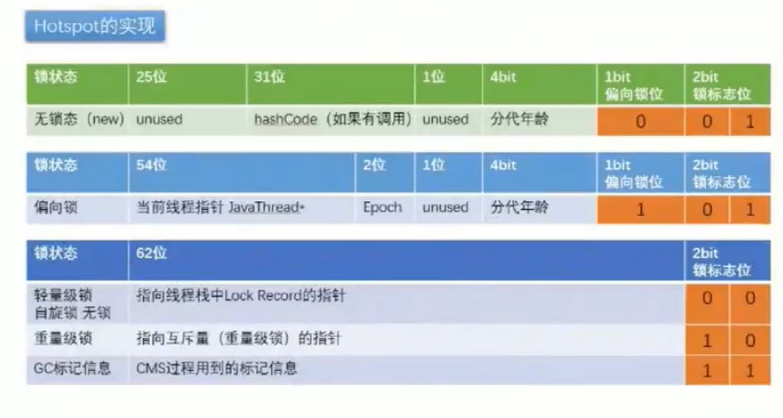
对象头中有什么?(由12个固定长度的字节组成)
- Markword(64b)
- Klass pointer(32b)

32位的结构
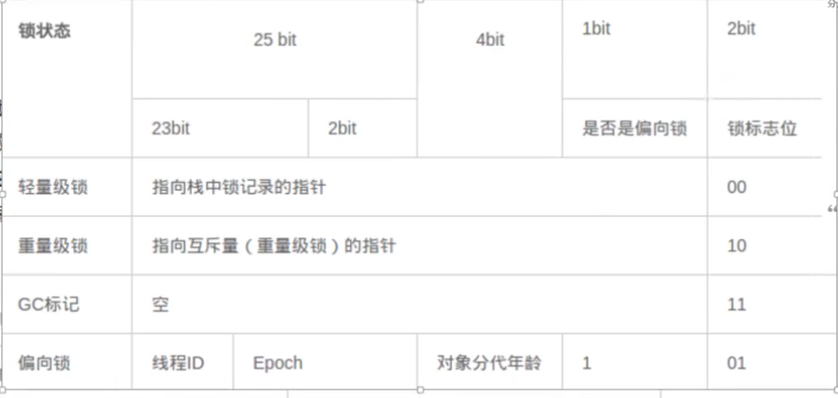
对象有一些什么状态
- 偏向锁
- 轻量锁
- 重量锁
- 无锁
- GC标记
由源码得知

java虚拟机默认开启了指针压缩
- 垃圾回收开销变小
- cpu执行效率提高
cpu存储又分为大端(高地址高字节)和小端(intel存处理器使用 高地址低字节(字节码是反着来的))
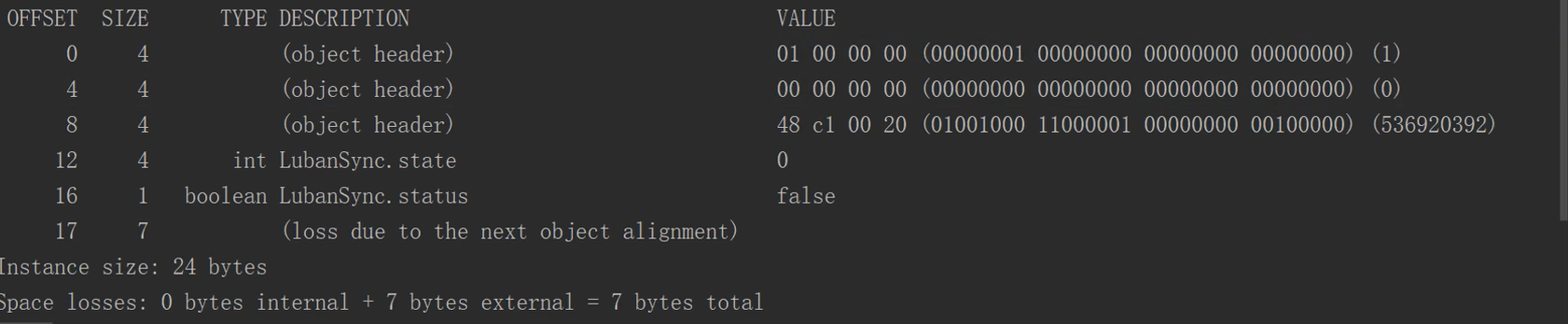
hashcode真的存在吗?(用于确定对象的地址)
为什么分代年龄一但超过15就会被放入老年区(分代年龄占4位,最大表示到15)
锁膨胀是可逆的(批量撤销)

