技术面试指导
本文从“必备项”和“加分项”两个角度分析。
一、必备项
0.自我介绍
表达流畅,不要太差即可
1.基础
坑:【答案很标准】面试时的回答,一定不要背网上《面试大全》中的标准答案,一定要有自己的思想 (哪怕有少量错误) 。
常见的题,一定要提前准备好。例如,以下列举的几乎都是必考题目:
arraylist/hashmap的源码、实现原理 ,冒泡排序/快速排序、 单例模式/工厂模式/动态工厂、谈谈你对面向对象的理解, 事务ACID/隔离级别 ,Spring IOC/AOP
建议:自己的理解 ,或者搜博客/githug上大神的博文。也就是说,可以将 面试题中的问题 在博客、github上搜答案,而不要死记“XXX面试大全”中附带的答案(那些答案往往很浅)。总之,要在自己写答案时,向面试官传达“我的答案是自己写的,我是一个有独立思维的人,而不是网上抄的”。
2.技术列表
掌握程度
坑:“精通” (3年以内的开发者,几乎没人敢说“精通”哪一门技术)
建议:掌握、熟练、理解 ,会使用
坑:个人掌握的技能过于“标准化”,明显就是培训、或者看某套视频学出来。如:java + 数据库+web前端+jsp/servlet+ssm +boot/cloud
建议:一般而言,自学成才的人比培训出来的学生 更具有独立思考的能力,因此在相同的条件下,企业更喜欢没有参加过培训的学生。
建议写上2-3门非培训机构标配课程,如service mesh、netty等(最好写与高并发、分布式有关的,技术的名字相对“少见”但又很重要的)。
对面试而言,这些“少见”的技术,只要你写上了,并且能把其中任意一个核心知识点说明白,就已经非常加分了。(假设Spring是一个“少见”的技术,那么你只要在面试时解释一下什么是IoC就可以了)
坑:简历上写一大堆牛B的技术,显得自己很厉害
建议:技术点宁可少写,也别多写。面试官经常都很忙,没时间精心准备对你的面试,甚至有时候是一边神游一边在提问,所以很可能从你简历里随便挑几个你写上的技术来问你。因此简历上写到的技术,都很可能被问到。
(本条建议与上一个“2-3门非标准课程”并不冲突)
3.项目
坑:项目名叫“Xxx电商项目”、“Xxx管理系统”,这些“项目”简直就是培训机构的标配,缺乏真实项目的感觉
建议:
(1)提前准备好回答“项目”的剧本。
“你做过什么样的项目?”或者根据你简历中的项目来提问,几乎是技术面试官必须做、并且非常喜欢做的事。所以,如果你没有充足的项目经验,就提前准备好台词吧。
(2)关于项目,经常会被问到的点是:某个技术本身的不足,以及如何弥补。因为这样问,能够检验你是否真的做过这个“项目”,至少能说明你是否深入思考过。举例如下:
a.你项目中用到了Mysql :如果数据超过的Mysql的容量怎么处理?(弥补MySQL自身的不足)
b.你做的这个项目是高并发吧?缓存用了吗?在哪些场景 你见过缓存失效?怎么解决?(还是在问你缓存自身的问题如何解决)
c.看你的项目用到了MQ?MQ可以用来解耦合,具体讲讲你项目中到底哪些场景用到了解耦合?(在考你的项目是真的,还是假的)
(3)项目的重难点。
每个项目都有自己的重难点,这些重难点也就是必问点,
举例如下:
a.分布式项目:如何共享数据?什么是CAP原则?分布式锁、分布式事务、分布式缓存怎么实现?
b.高并发项目:几级缓存,如何限流,如何熔断,用docker了没?
(4)真实性:实际的使用场景
a.简历上写的“用到了人脸识别技术” :哪些场景用到了?人脸识别是自己公司写的,还是调用的三方API?自己写的话,用的什么算法?调用API的话,每次调用需要付费多少钱?识别时的光线强度有什么要求?
b.多线程、设计模式、算法:用来处理什么业务?场景?
c.大数据的项目:数据从哪来的?d.项目能否访问?
(5)描述方式:技术列表 + 文字 (如果绘图功底不错,可以加上架构图)
项目周期:半年以上
简历上的项目个数:3个以内(如果是才毕业3年以内,写1-2个就可以了)
4.表达沟通能力
二、加分项
1.高并发/分布式/调优
a.多线程(juc、aqs、线程安全、锁机制、生产消费者、线程依赖问题)
b.数据处理SQL优化 , 常见高性能数据库架构(如mysql+mycat+haproxy+keepalived)
c.JVM调优
2.实际的解决问题能力
这点需要自己在面试时主动将话题引入。
例如在回答项目时,主动说一下你在做项目时遇到过什么问题。具体是如何发现、排查、分析、解决问题的。
3.绝杀
ACM竞赛、蓝桥杯等全国性竞赛(学生专享)
有过书籍、论文等出版物在github发布过项目(star很多)
博客、微信公众号公众号、 个人在阿里云等部署的可访问项目(这一条大部分人都能做到)。如果是电子简历,附上链接地址;如果是纸质简历,将链接封装在二维码里。
研究过JDK/spring/mybatis等源码
三、注意/建议事项
1.在描述时,多使用“数字”:几个项目、几篇博客 、排名第几
2.工资:不要写面议 ,至少给个薪资范围,如1.5w - 2.0w3.简历:1-2页(每一页写满,尽量不要空半页),不要包书皮,
格式使用PDF(不要wps或word,可能出现兼容问题),
外观简洁大方即可,不要太过绚丽
4.细节:毕业时间、年龄、工作履历、期望薪资等要相互匹配。例如,不要“毕业5年”,但“工作履历加起来只有3年”。
5.沟通:注意人文素养 ,不要抱怨问题, 要体现解决问题、愿意承担责任的态度建议:个人解决问题的能力、团队感、沟通能力
技术面试 - Java SE
背景:秋招 有些同学 没找到offer
1.自己知识储备不足
2.准备OK,但是仍然没找到offer
面试技巧(重点)、代码讲解
招聘岗位10, 50个人 : 10 + 40
不会脱颖而出
主题: 出奇制胜
1.反对和所有应聘者 千篇一律
积累: 阿里巴巴 编程规范 , 《effective java》
2.反对和所有《面试宝典》 千篇一律
建议: 只看宝典里的题目,不看答案(答案自己写)
只看题目 + github/知乎/博客
线程通信 wait()、notify()/notifyAll()
Semaphore、google guava类库Monitor
3.源码级解决问题
产生一个问题?百度、谷歌、问老师。
面试官问: 请讲讲ArrayList如何库容的?
我最初看书(看博客、文档),上面它的底层是动态数组,会在add()时 如果发现已满,则自动扩容1.5 。我还查阅了源码进行了验证,发现是在数组已满扩容,并且是通过 位移运算符扩容。
int newCapacity = oldCapacity + (oldCapacity >> 1);
4.找对时机,秀技能
每个人都有一些 独到的经验,要想办法在面试的时候 讲给面试官。
“聊聊自己的项目经验” ,讲项目,讲完的时候 加一句:我在做这个项目的时候 曾经遇到了一个bug,当时ArrayList.asList()返回一个List,当时通过阅读源码 发现 返回的LIst不是 Collection中的那个List。
5.比较通过的 秀点
优化类(JVM、SQL优化)
jvm优化:1.项目做完时,我用jmeter进行了压力测试,结果发现相应时间太慢(或者内存利用率太高) ,然后我用jvisualvm分析了下JVM的内存情况。分析后,进一步发现项目中的小对象太多了,并且发现这些小对象都是生命周期比较短的对象。然后我猜测可能就是由于短对象太多,造成了堆中新生代容量不足,进而让很多短对象逃逸到了老年代中。这样一来,新生代和老年代中的对象都会很多,就会加速GC的回收频率,从而降低系统的性能。对此,我调大了新生代的内存大小,并且调高了新生代 逃逸到老年代的 阈值。之后再测试,发现性能平稳了许多。
PS:以上短短200字,就告诉了面试官你有性能测试的良好习惯、会发现问题、分析问题,并且会JVM调优!
2.项目做完时,我用jmeter进行了压力测试,结果发现响应时间太慢。然后我用mysqldumslow工具查找到了项目中执行时间最长的那个SQL语句,因此猜测是这条SQL的性能太低,拖累了整个系统。然后我用explain查看了SQL执行计划,发现这个SQL根本没有写索引并且是大表驱动了小表,所以特别慢。之后,我给它后面的where查询字段加上了索引,并且改为了小表驱动大表。然后再次测试,响应时间就缩短了很多。
PS:这个秀点是“SQL优化”,具体流程是:定位慢SQL->使用explain查询SQL执行计划,用于分析SQL执行慢的原因->SQL优化。上述中的“小表驱动大表”等是SQL优化时的术语。
算法类的:字符串算法 (KMP算法)
6.技术沉淀
数据支撑: github、博客、专栏、微信公众号、项目发布到阿里云
7.大厂的区别
bat ,美团,字节调动,google facebook
数据结构和算法、操作系统、网络、设计模式、分布式、逻辑思维(8+11 ?)
8.心态建设
回答正确,但被面试官“否定”
1.答案来自于面试宝典,千篇一律
2.面试官自己在秀技术 ,调整好心态,不要受干扰。
正常面试官: 引导你来回答,而不是想方设法吓唬你
有没有用过List? 哪些常见子类?数组?动态扩容,不越界?
3.如果问到 自己不会的?一定要答出自己的想法/答类似的框架, 虽然没用过这个新框架,但是我用过同类产品,并且相信他们是差不多的,然后就答这个同类产品的 实现原理。
mybatis \jpa
新dao框架 ? 映射文件/注释: 实体类-表, 然后通过框架本身的api的进行crud….
MQ:rabitmq rocketmq kafka\新MQ
SSM和开源框架
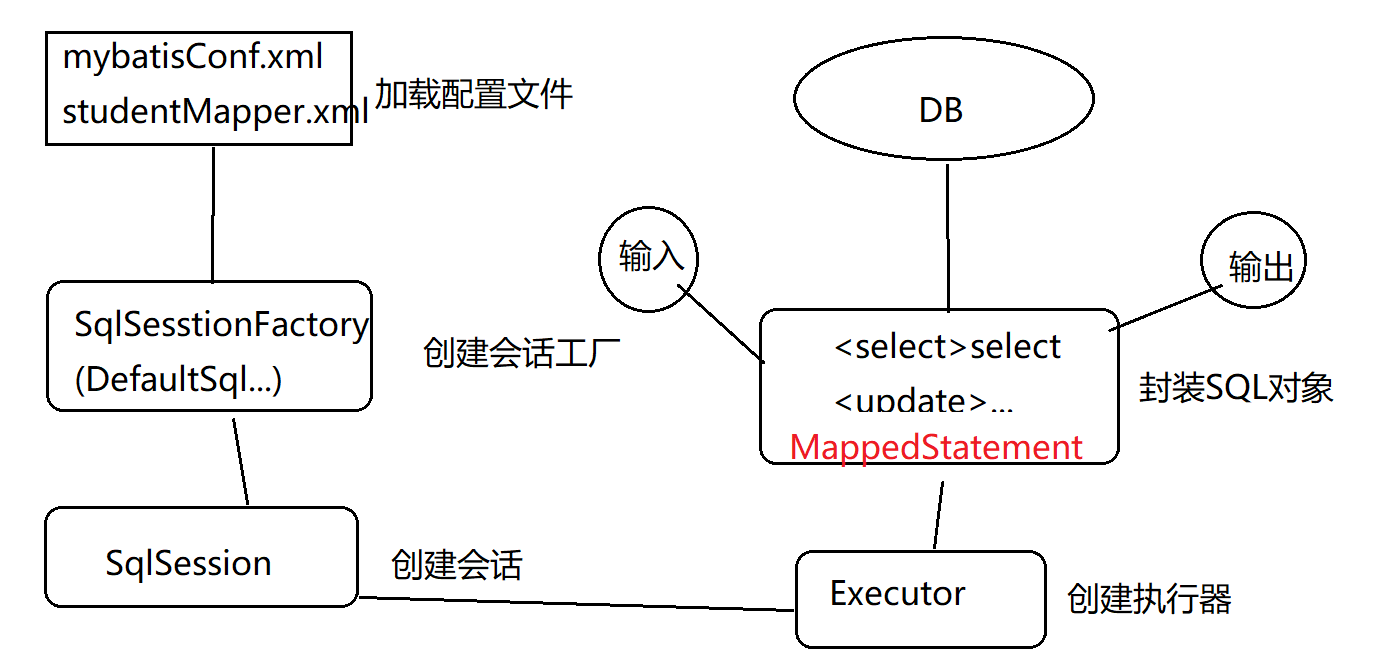
MyBatis重要组件:
- Mapper配置: 实体类Student.java - 数据表student , XML或注解
- Mapper接口: DAO层接口。 (只需要写接口,不用写实现类 :需要遵循约定)
Mapper接口在编写时 需要遵循约定:
1.方法名和SQL配置文件(studentMapper.xml)中的id值必须相同
2.方法的输入参数,必须和SQL配置文件的 parameterType的类型相同;
3.方法的返回值,必须和SQL配置文件的resultType的类型相同
SQL配置文件
<select id="queryStudentByNo" parameterType="int" resultType="lanqiao.entity.Student" >
select * from student where stuNo = #{stuNo}
</select>
接口
<select id=" queryStudentByNo" parameterType="int" resultType="Student">
select * from student where stuNo=#{stuNo}
</select>
根据约定,编写接口
public interface StudentMapper
{
Student queryStudentByNo(int stuNO)
List<Student> queryStudentByNo()
}
特殊:
1.如果不存在parameterType ,则代表是一个无参方法
2.如果不存在resultType,则代表返回值是void
3.如果方法的返回值是一个集合类型,则实际resultType仍然是元素类型,而不是集合类型。
MyBatis开发时的常用对象
1.SqlSessionFactory:SqlSesssion工厂。通过SqlSessionFactory:SqlSesssion中的openSession()产生SqlSesssion对象。
2.SqlSesssion:SqlSesssion对象(类似于JDBC中的Connection)
3.Executor:MyBatis中所有Mapper语句的执行 都是通过Executor进行的。
MyBatis四大核心对象
1.StatementHandler(负责sql语句):数据库的处理对象 select… from where id = #{} ..
2.PrameterHandler(负责sql中的参数):处理SQL中的参数对象
3.Executor
4.ResultSetHandler:处理SQL的返回结果集
MyBatis四大处理器
StatementHandler、PrameterHandler、ResultSetHandler
剩下一个:TypeHandler (类型转换器)

执行流程
一对一、一对多,延迟加载
一对一
使用<resultMap>中<association>
一对一的延迟加载:
使用<resultMap>中<association>的select属性指定延迟加载的sql语句
<resultMap>
<association select="延迟加载的sql语句" >
<<association>>
</resultMap>
一对多:将一对一中的
Spring
IOC/DI:控制反转/依赖注入
目的:解耦合
Student2 student = new Student2() 使用new会造成耦合度较高 ->工厂模式
类- >new ->对象
类- > 工厂模式->对象 ,可以实现解耦,问题是:需要自己编写工厂
IOC:IoC帮我们提供了一个工厂。 1.向工厂中注入对象 (配置[xml、注解]) 2.从工厂中获取对象
总结:Ioc可以让我们通过“配置的方式”来创建对象
AOP:面向方面编程
OOP的补充,不是替代。
使用oop的不足:
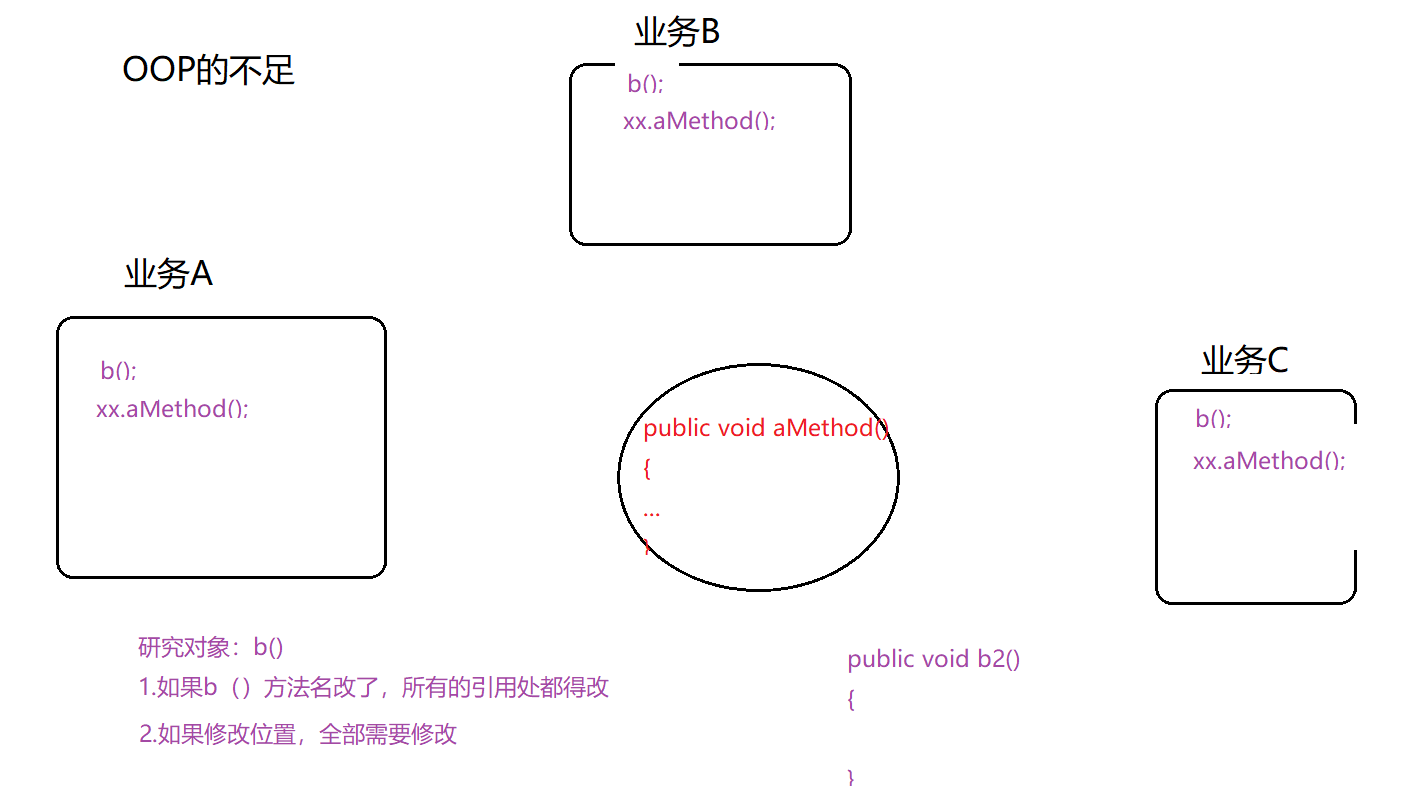
以上OOP两个不足,可以通过AOP进行改进。
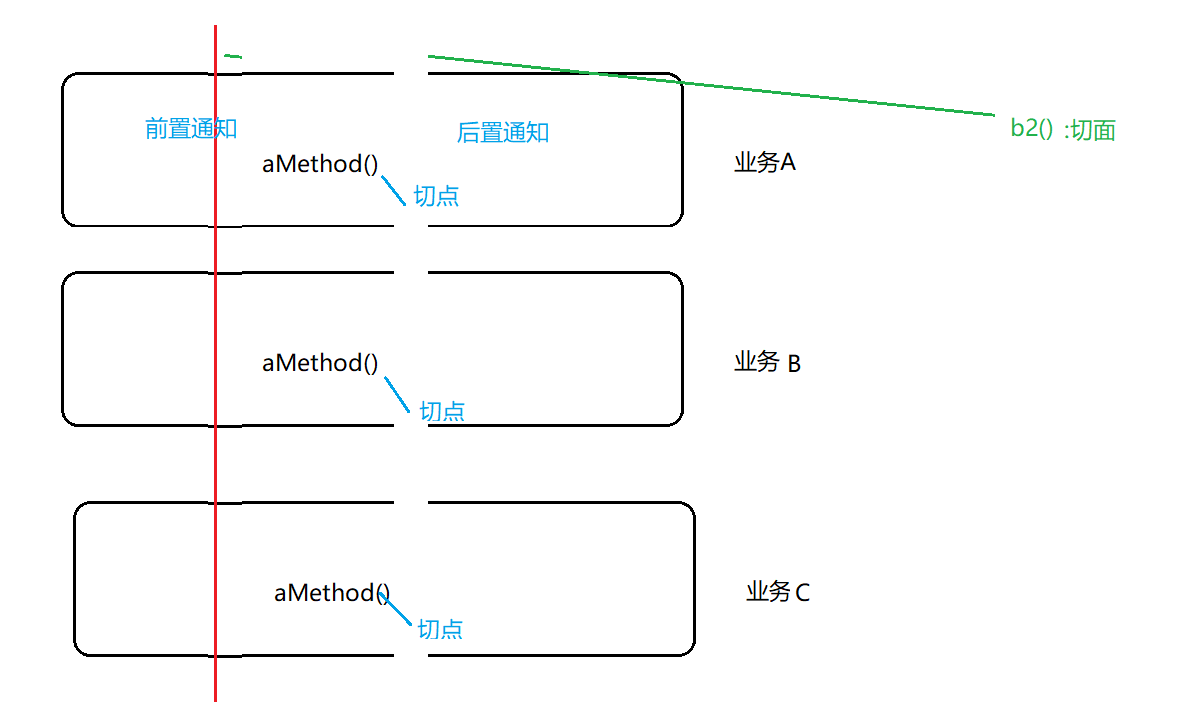
使用AOP的实际场景:
日志、安全统一校验
Spring用到了那些设计模式
工厂模式:创建bean、获取bean
单例模式/原型模式: 创建bean时,设置作用域 ,singleton/prototype
监听模式:自定义事件发布,监听模式。如ApplicationListener,当某个动作触发时,就会自动执行一个通知。
以前(不用spring boot),需要自己配置框架的配置文件。
spring,mybatis ,SSM整合等情况 需要编写一大堆配置文件。
如果使用Spring Boot,则可以省略配置 。 好处:将开发重点放在业务逻辑上,而不是配置上。
自动装配的原理? 约定优于配置 (核心:将一些配置功能,前置到源码底层实现好)
自动装配两个特点:
1.版本仲裁中心:因此,以后引入依赖时,不用再写版本号。好处:1.不用记 2.避免冲突(防止引入多个引来时,由于各个依赖的版本不兼容造成的冲突)
2.提供了很多starter(场景启动器) :批量jar。
假设开发web项目 ( json.jar tomcat.jar hibernate-validator.jar, spring-web.jar … ) => spring-boot-starter-web.
以后使用web项目,只需要引入spring-boot-starter-web
自动装配的应用时: @EnableAutoConfiguration 就是springboot提供自动装配的 注解。
Spring Cloud
Spring Cloud:微服务治理框架
内置了许许多多的组件
Eureka
服务注册中,类似于dubbo中的zookeeper.
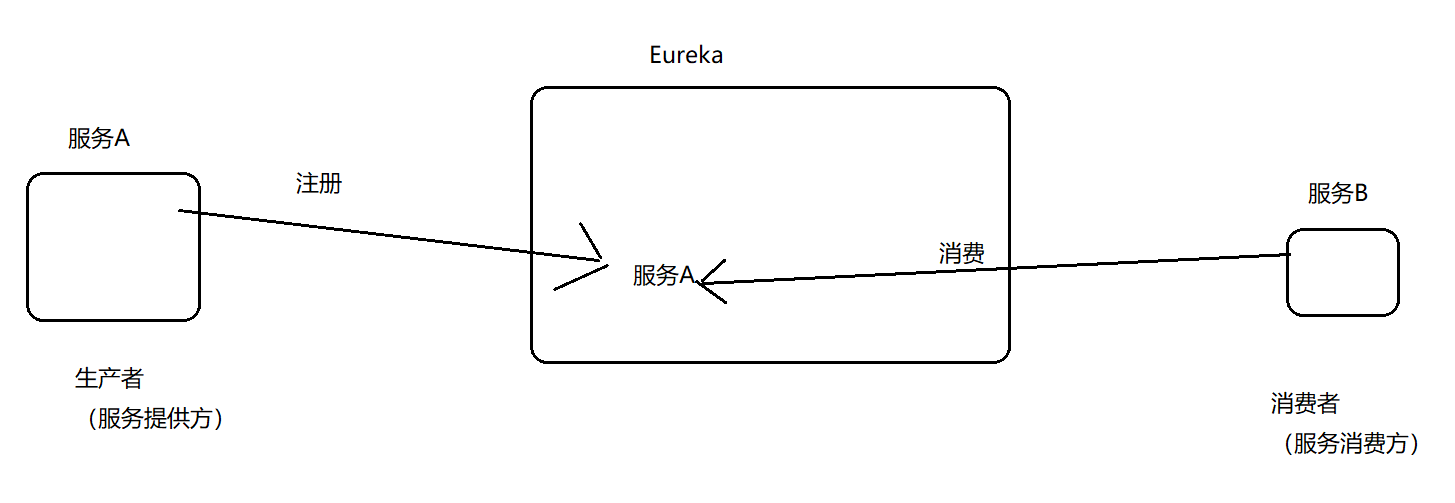
换个角度:Eureka也可以理解为 两个组件 Eureka Server和Eureka Client。
需要注意:Eureka Client有两个角度:如果站在eureka来看,是一个 客户端;如果站在系统角度来看,是一个服务端。
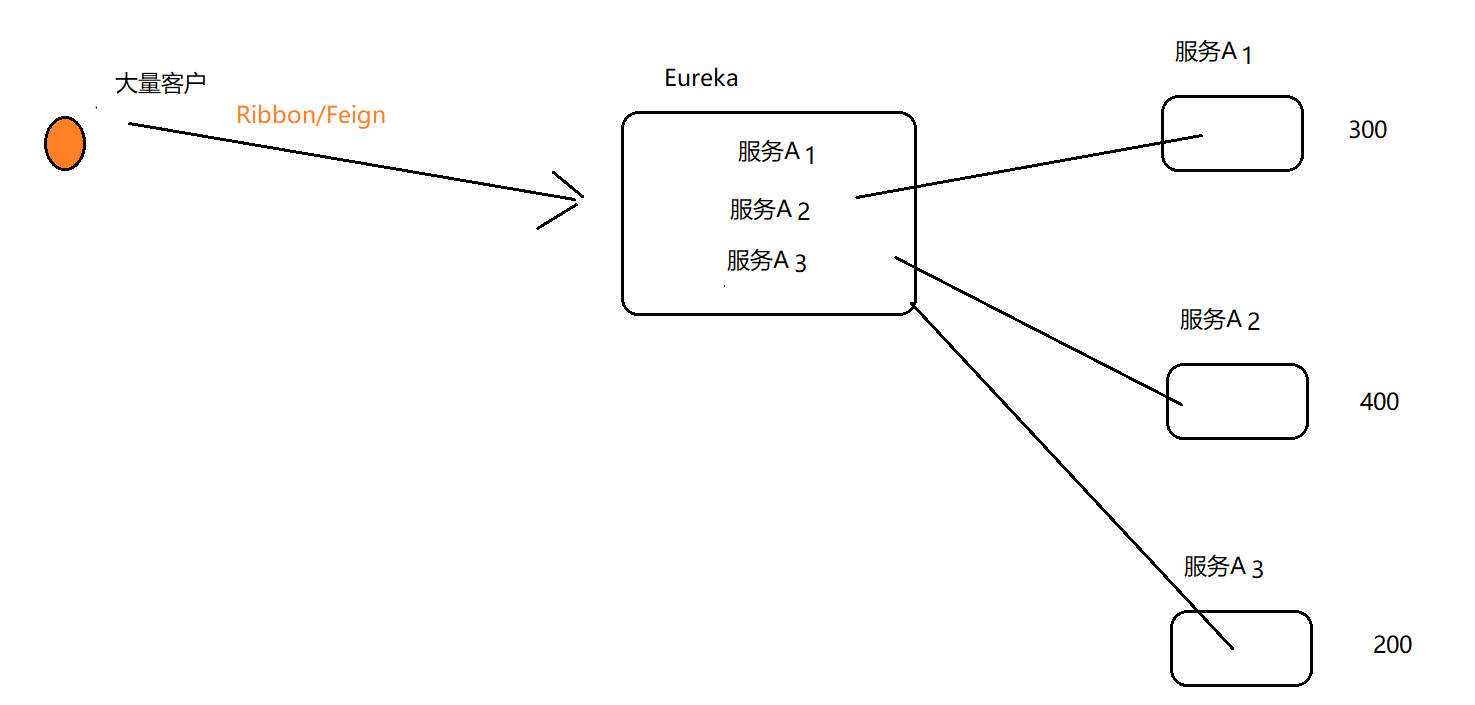
Ribbon
客户端负载均衡工具
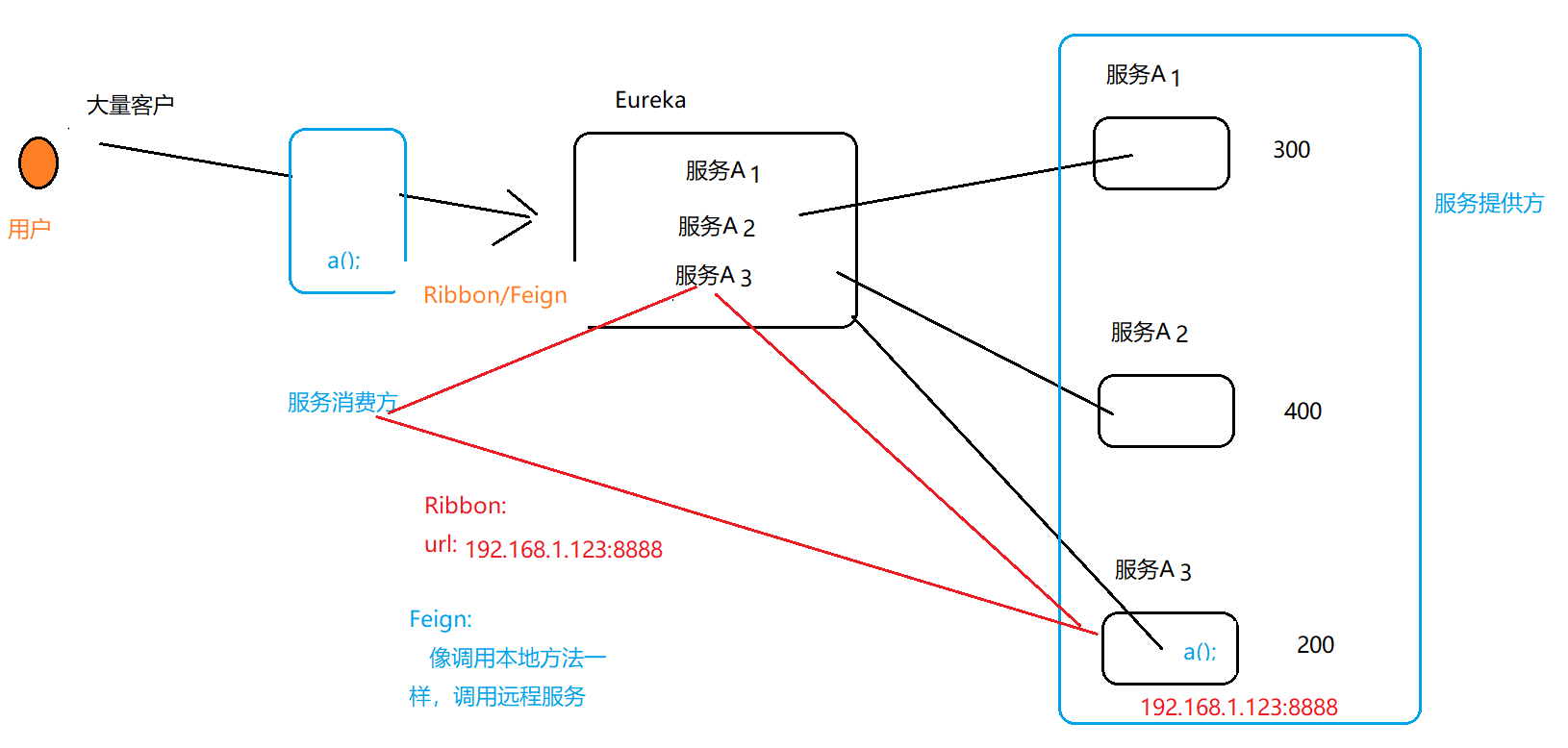
Feign
声明式客户端负载均衡工具
Feign是建立在Ribbon之上。
Feign与Ribbon的区别: Ribbon面向URI地址的;Feign面向接口的
熔断器
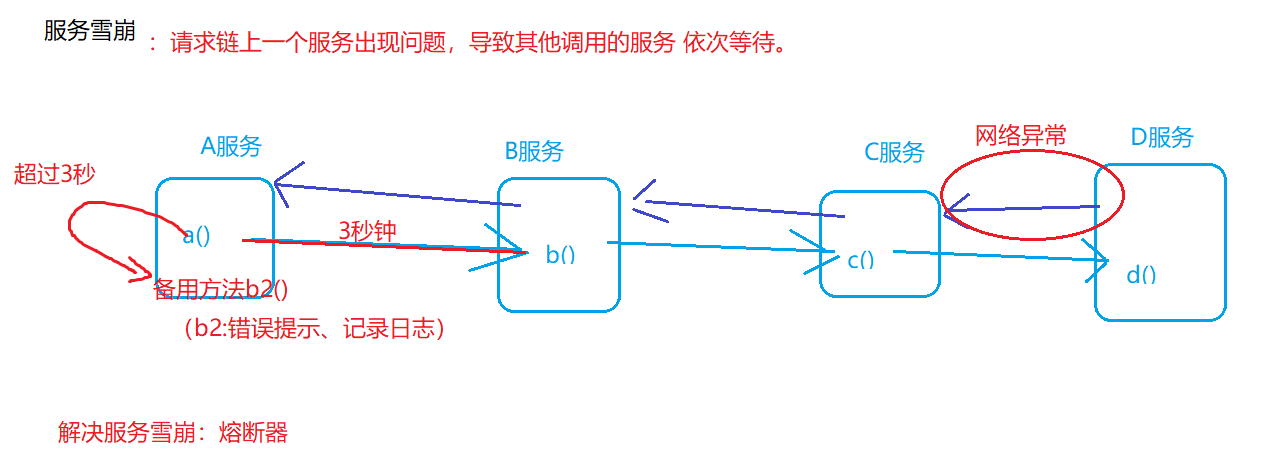
熔断器:Hystrix
@HystrixCommand(fallbackMethod="b2")
public void a()
{
b();//远程
}
puyblic void b2()
{
...
}
分布式核心设计
简介
最火?
大数据、人工智能、区块链、边缘计算、微服务 -> 分布式
分布式:拆
微服务&分布式
分布式:拆了就行
微服务:纵向拆分(根据业务逻辑拆分,电商:用户、支付、购物…)、最小化拆分
横向:jsp/servlet -> service->dao
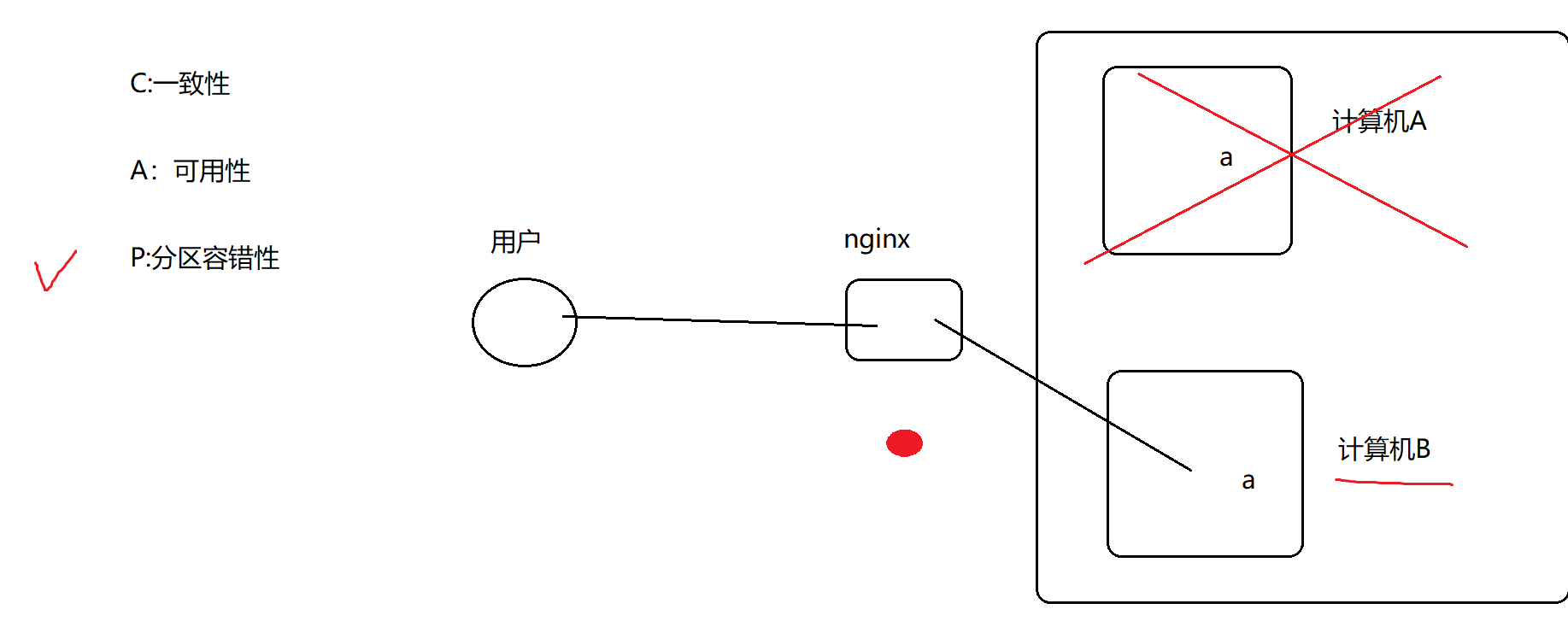
CAP理论
任何一个分布式系统 都必须重点考虑的原则。
C:一致性(强一致性):所有子节点中的数据 时刻保持一致
A:可用性:整体能用
P:分区容错性 :允许部分失败
CAP理论:在任何分布式系统中,C\A\P不可能共存,只能存在两个。
基础知识:一般而言,至少要保证P可行,因为分布式 经常会出现 弱网环境。因此 就需要在C和A之间二选一。
BASE理论
为了弥补CAP的不足。
尽最大努力 近似的实现 CAP三者:最终一致性 代替强一致性C
前置: 强一致性(时时刻刻一致、短时间内一致)、最终一致性(只要最后一致即可)
BASE理论:首选满足A\P, 因此不能满足C。但是可以用 最终一致性 来代替C。
BASE:Basically Available 基本可用
软状态:多个节点时,允许中间某个时刻数据不一致。
最终一致性
分布式缓存
缓存问题(会提前将数据库中的数据放到缓存中(可以使用redis—–设置过期时间))
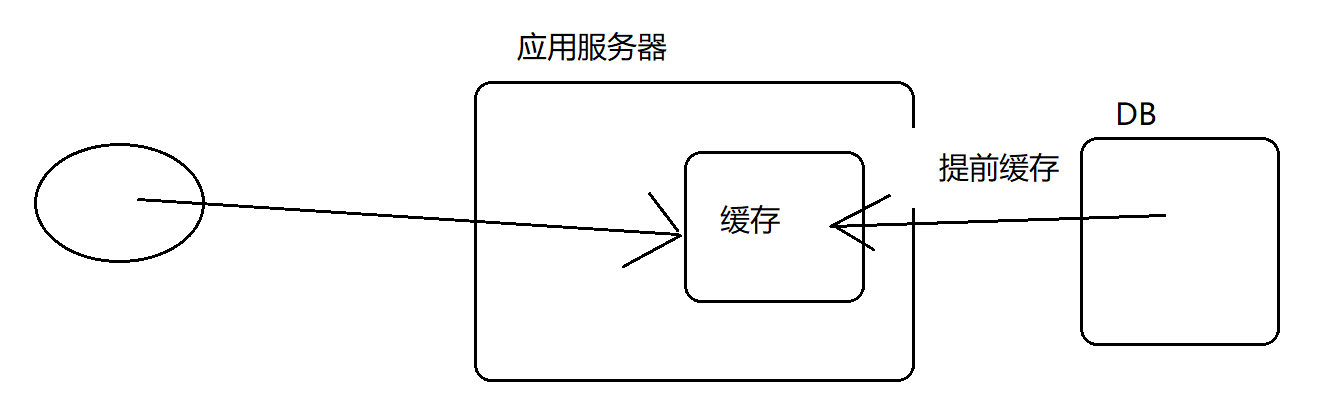
缓存击穿:某一个热点数据过期,造成大量用户请求直奔DB的现象。
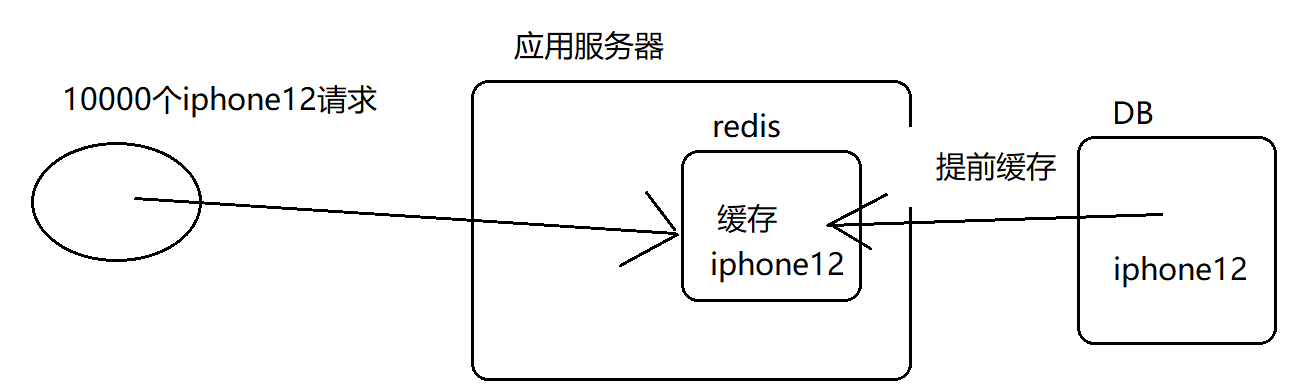
解决:1.监控线程(数据快过期了,再重新加载一份) 2.提前设置好时间,保证热点数据在 高峰期 不过期
Redis的缓存穿透及解决方法——布隆过滤器BloomFilter
缓存雪崩:大量缓存全部失效 (给大量缓存设置了相同的过期时间 ; 缓存服务器故障)
解决:1.合理分配缓存的过期时间(加个随机时间) 2.搭建缓存集群
缓存穿透:恶意攻击。一般而言,不会缓存一些无意义的数据。但是如果恶意工具,就可以利用一些无意义的数据 反复发起请求。
解决:将无意义的数据也进行缓存,并且将过期时间设置的相对短一些。
以上的本质都是“缓存失效”,通用的解决方案:二级缓存(分布式缓存)
一般而言,本地缓存 是一级缓存,分布式缓存是二级缓存。
一致性hash
hash算法:映射
字符串、图片、对象 -> 数字
hash(a.png ) -> 12312313
一致性hash最初用于解决分布式缓存问题
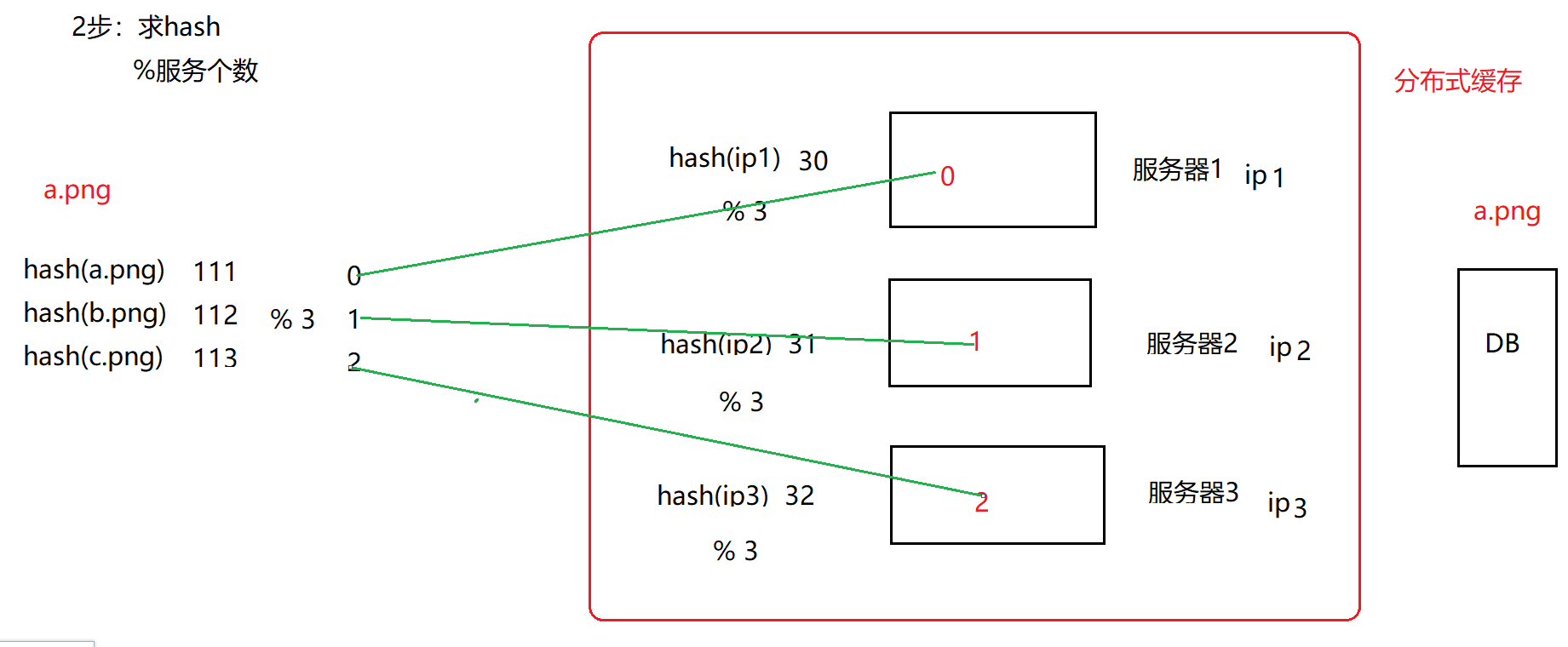
以上 将 数据 映射到 某个缓存服务器的做法 有一个问题: 当服务器个数发生改变时,缓存会失效。
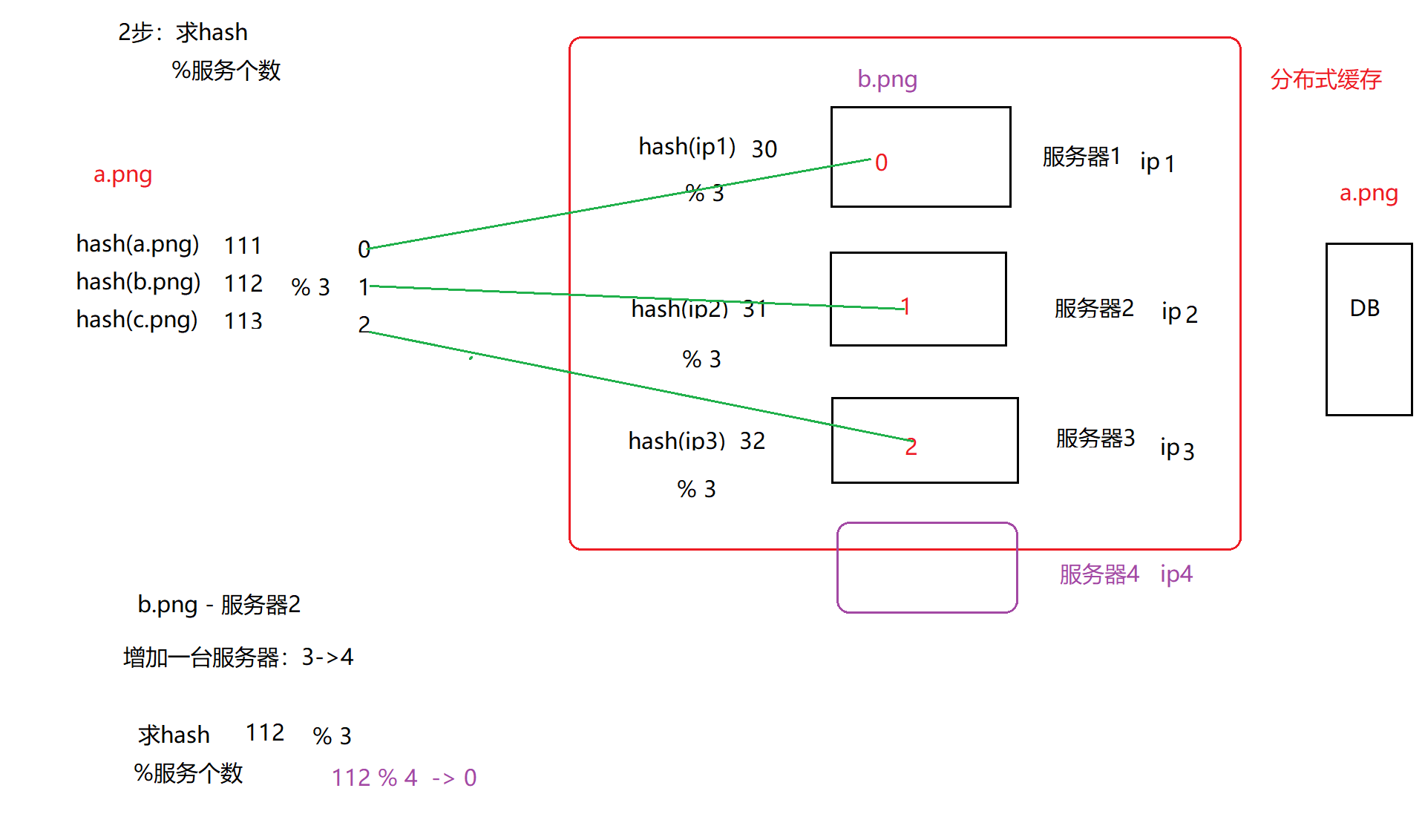
解决“服务器个数改变导致的问题”:一致性hash
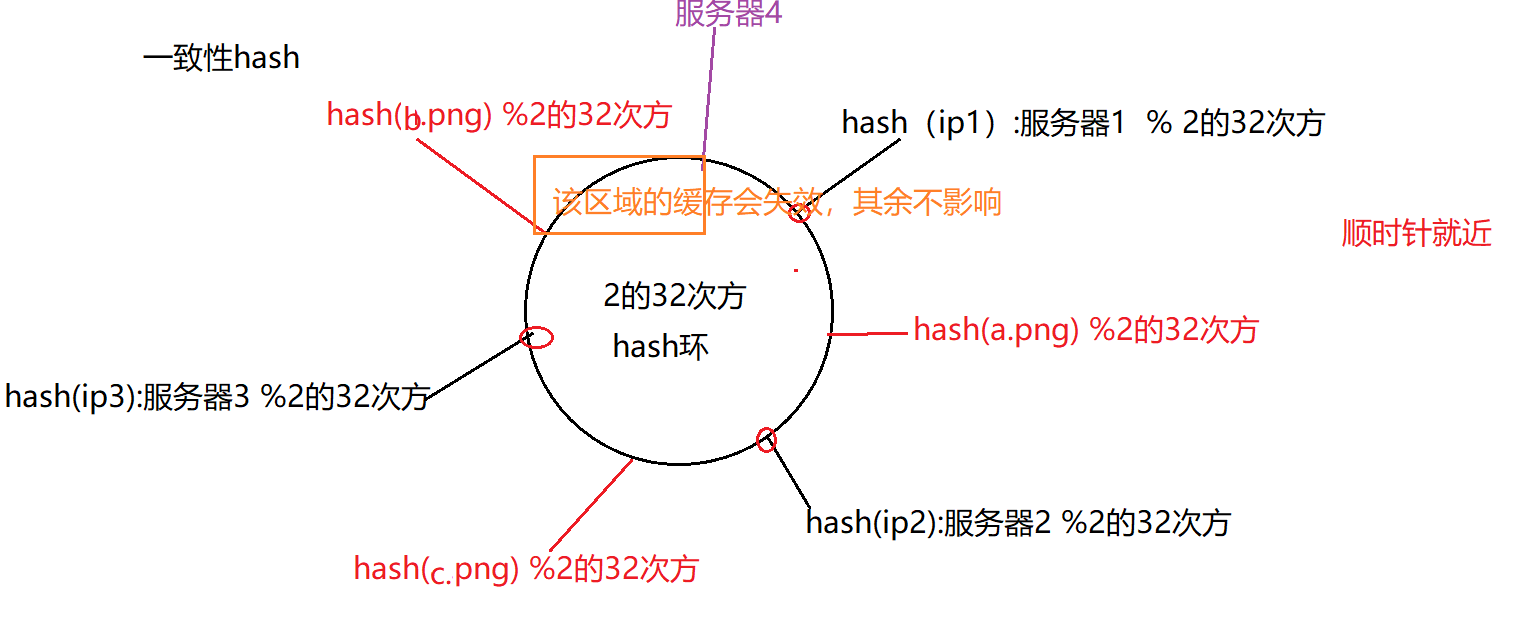
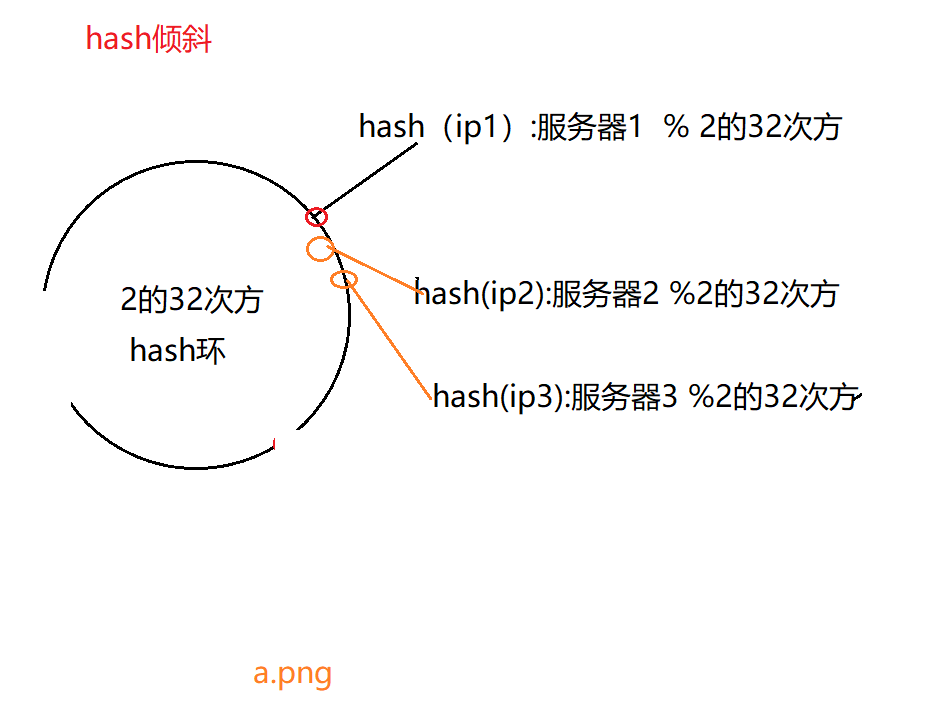
hash偏斜问题
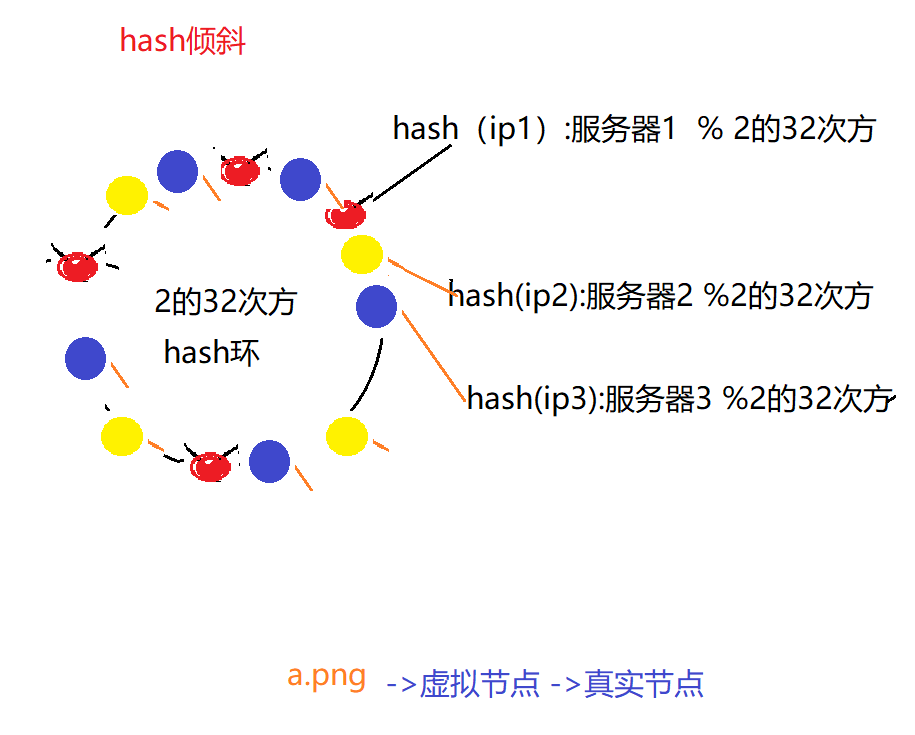
解决hash倾斜问题:虚拟节点
在环上生成多个 虚拟节点,后续 请求先找虚拟节点,然后在通过虚拟节点找到对应的真实节点
缓存一致性
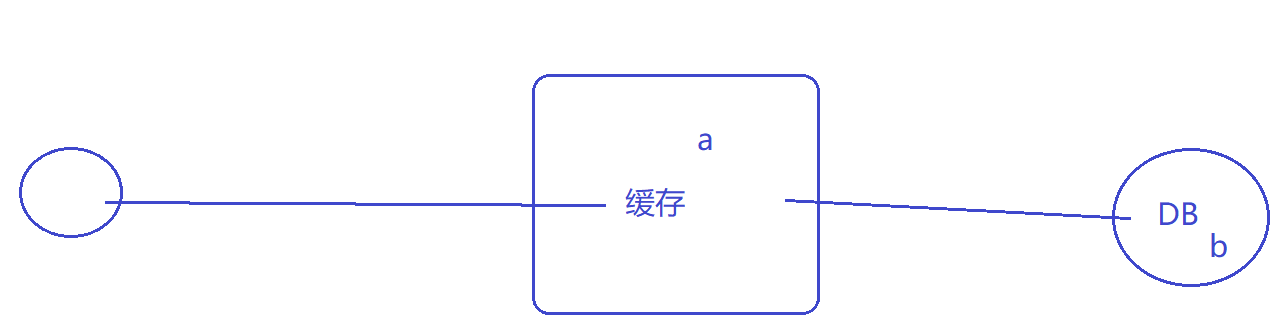
(思考)
最容易想到,但也不推荐的做法: 当DB更新后,立刻更新缓存 ; 先删除缓存,在更新DB。
推荐: 当DB更新后,立刻删除缓存
分析:(反例)
当DB更新后,立刻更新缓存(不推荐)
问题:
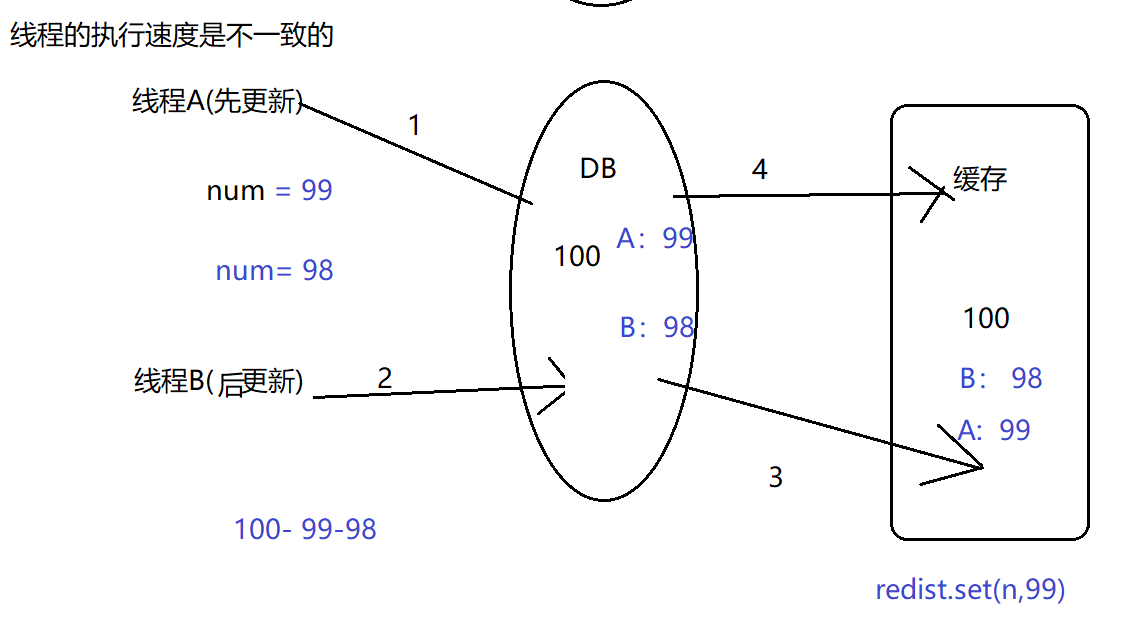
如果线程A先更新,线程B后更新,最终的结果 可能是A的结果。原因:线程的执行速度可能不一致。
推荐: 当DB更新后,立刻删除缓存 。因为:对于删除来说,没有速度的先后问题(没有速度不一致的问题)
(这种推荐的方式,仍然会存在 一个 极小概率 的错误情况)
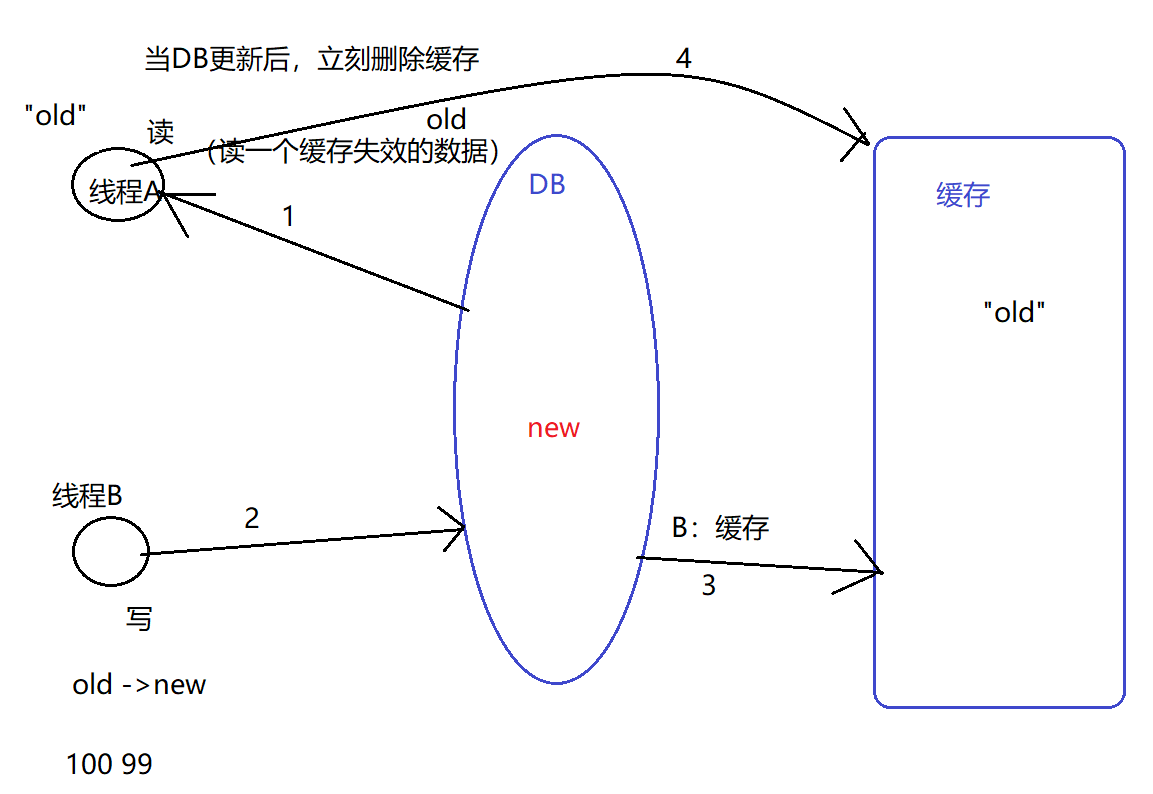
以上就是这个推荐方式的一个错误情况,但发生的概率是极小的:1.发生在“缓存失效”的前提下 2.发生的前提:写线程的速度 要 快于 读线程,基本不可能。
问:这个 极小的错误情况,能否避免?
答:能!以上错误发生的大前提:读操作 和写操作 交叉执行,解决思路:让二者 不要交叉。 加锁,或者读写分离。 但是一般建议,不用解决。(解决小概率的成本一般比较高,可能会超过犯错的成本)
能否调换顺序:删除缓存 , 再DB更新后
反例:
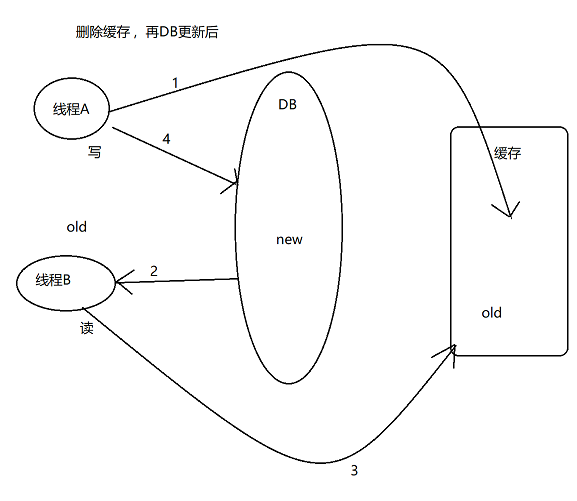
以上出错的前提:写慢,读快。因此发生的概率较大。
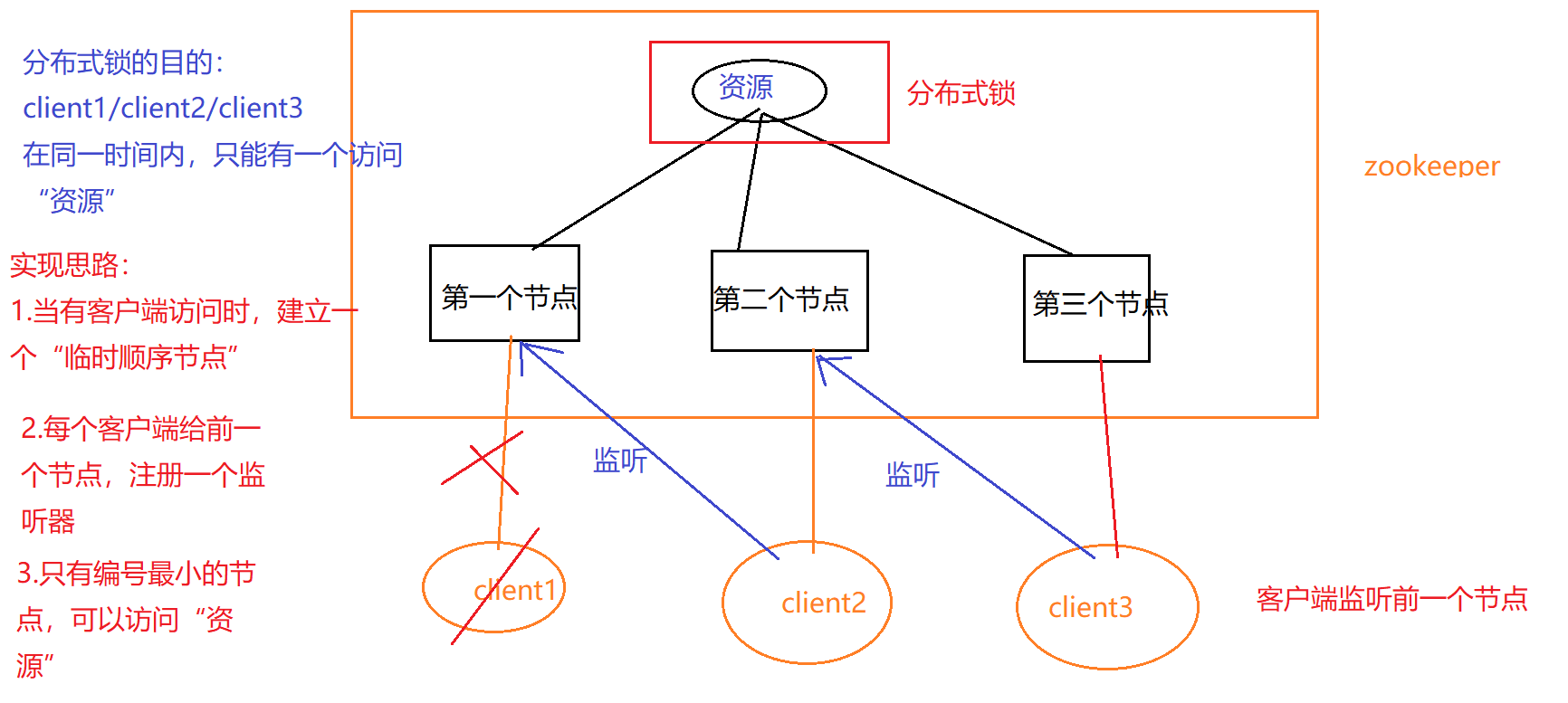
分布式锁
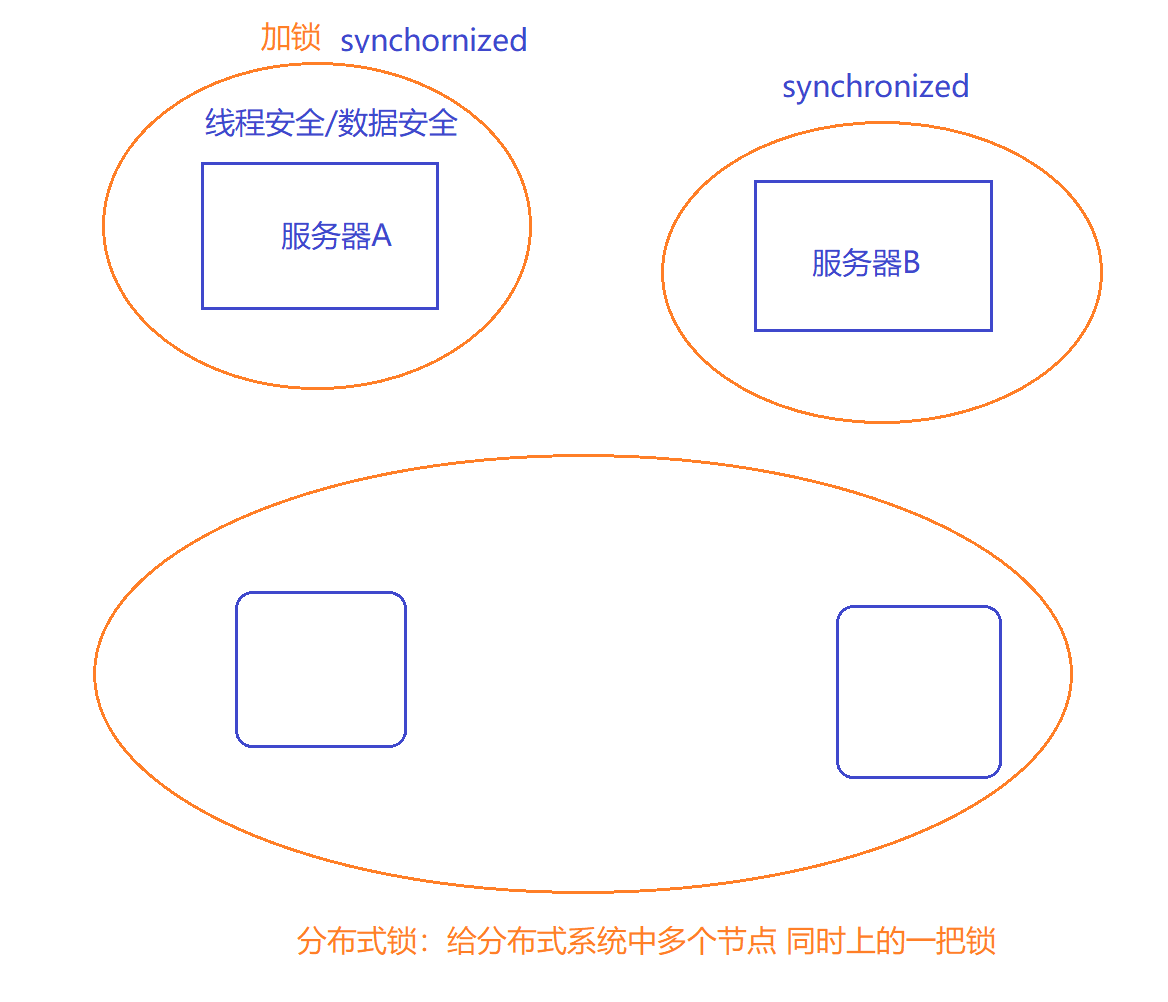
分布式锁:数据库的唯一约束、redis、Zookeeper
在架构开发: 没有最好,只有比较合适的。
使用Zookeeper实现分布式锁
zookeeper:分布式协调框架, 组成结构是 一个颗树(类似于DOM树)
树种包含很多叶节点,在分布式锁中使用的 叶节点类型: 临时顺序节点。
zookeeper提供了以下两种支持:
- 监听器:可以监听某个节点的状态,当状态发生改变时 则触发相应的事件
- 临时节点的删除时机:当客户端与访问的临时节点 断开连接时
锁:同一个时间内,只能有一个线程/进程访问
分布式事务
本地事务:一个事务对于一个数据库连接。(事务:连接 = 1: 1)
凡是不符合上述1:1关系的,都不能使用本地事务,举例如下(以下都无法使用本地事务):
1.单节点中存在多个数据库实例。在本地 建立了2个数据库: 订单数据库、支付数据库。
下单操作 = 订单数据库+支付数据库
2.分布式系统中,部署在不同节点上的多个服务访问同一个数据库。
通过以上两点说明:本地事务的使用性 十分有限。
分布式事务实现
示例
下单操作 = 订单数据库 +支付数据库
服务器A: 下单操作 , 订单数据库
服务器B: 支付数据库
模拟分布式事务:下单操作
begin transaction:
1.执行 订单数据库;
2.执行 支付数据库
commit/rollback ;
以上,在分布式环境中存在问题:
begin transaction:
1.在本地(服务器A) 执行 订单数据库;
2.远程调用服务器B上的 支付数据库
commit/rollback ;
以上的错误情况:如果本地的订单服务 成功、远程的支付也成功,但是在 响应时由于网络等问题 无法响应,就会让用户以为 下单失败。
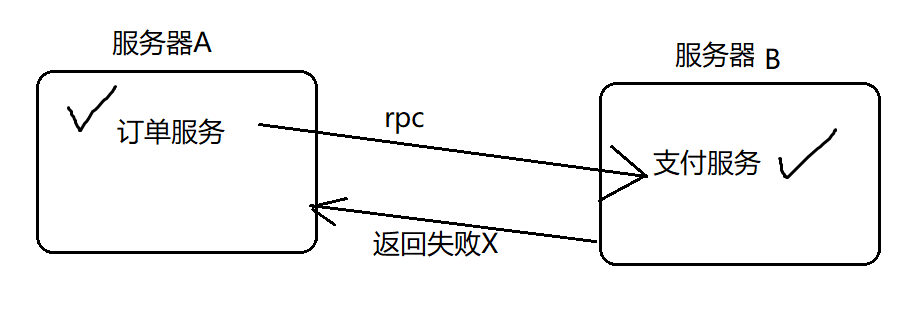
以上,本地事务无法操作的情况,就可以使用分布式事务。可以使用幂等性解决
使用2PC实现分布式事务
2pc:2 phase commit ,由一个协调者 和多个 参与者组成 (类似master-slave结构)
协调者: 事务管理器,TM
参与者: 资源管理器,RM
两阶段指的是:
准备阶段(Prepare阶段):当事务开始时,协调者向所有的参与者发送 Prepare消息,请求执行事务。参与者接收到消息后,要么同意,要么拒绝。如果同意,就会在本地执行事务,记录日志,但是不提交。
提交阶段(commit阶段):如果所有的参与者都同意,协调者再次给全部参与者发送 提交请求。否则进行回滚。
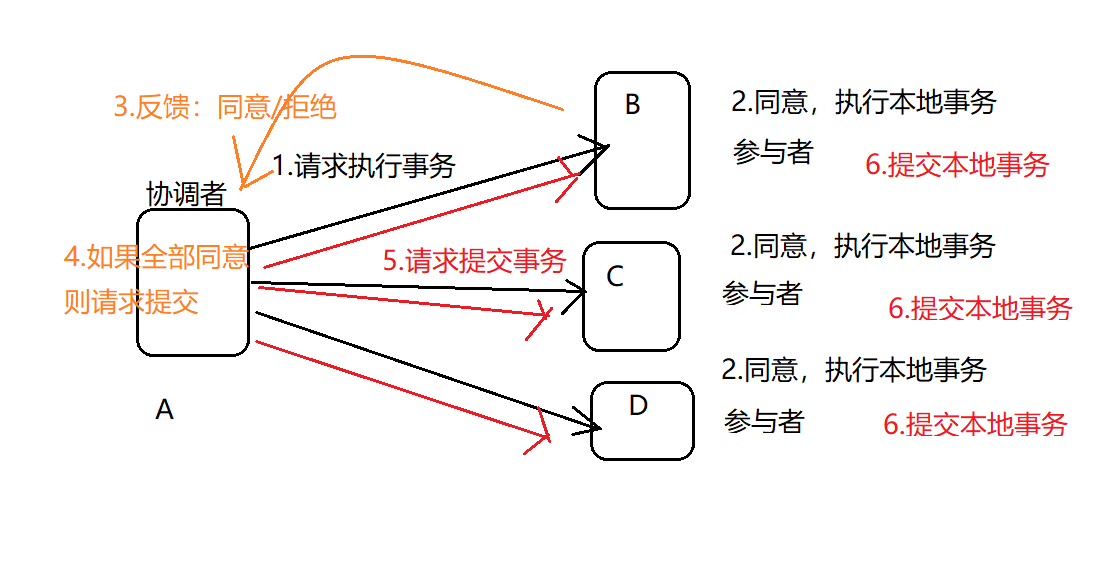
总体思路: 将一个任务(多个步骤) 进行2步操作: 1.请求各个节点执行 ; 2.如果大家都同意,请求一起提交
2pc缺点:1.分布式事务在执行期间是阻塞式的,因此会带来延迟 2.如果协调在第“5”步遇到弱网环境,可能造成一部分节点 没有commit的情况。 3.中心化架构,单点灾难。
其他分布式事务解决方案:三阶段提交,使用TCC实现分布式事务,使用消息队列实现分布式事务
注意:如果要严格的保证事务一致性:paxos算法。 google chubby作者
分布式认证 &分布式授权
认证方式:系统自己开发 、 三方平台
系统自己开发:分布式认证
三方平台:分布式授权 (SSO单点认证)
分布式授权: OAuth2.0授权协议 ,该协议的流程如下:
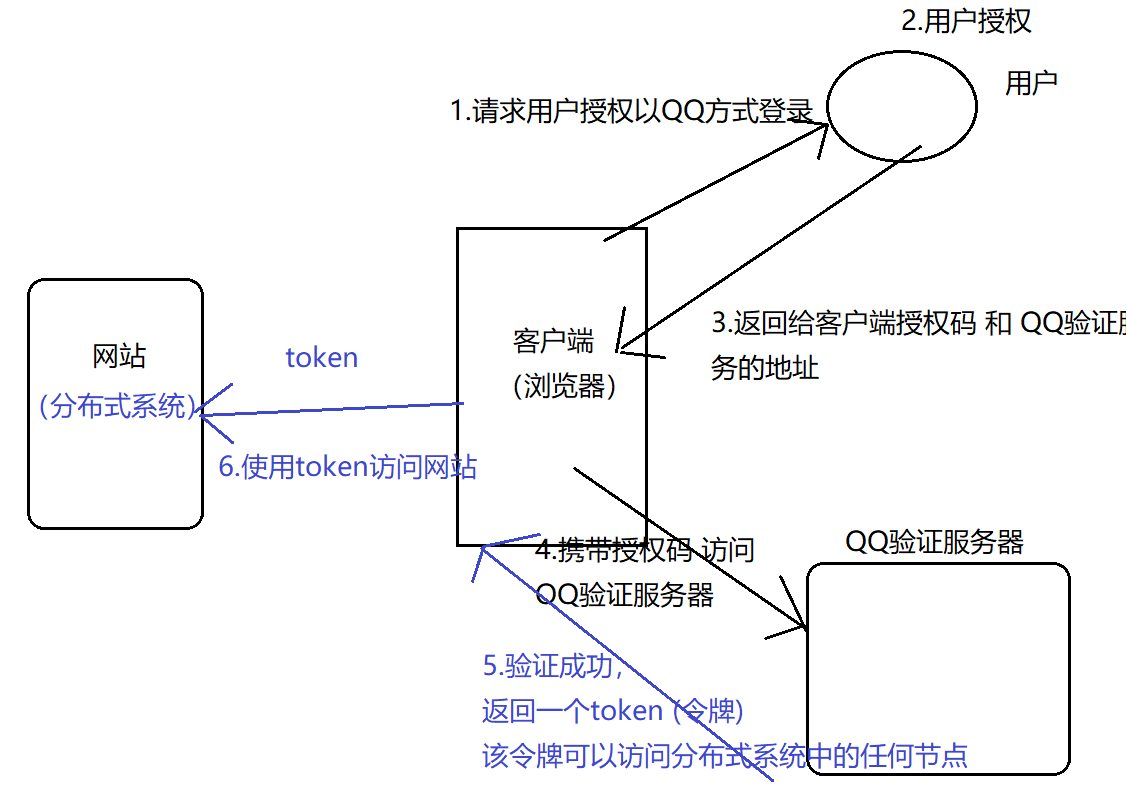
提示:发展史上, OAuth2.0 不兼容 OAuth1.0

