[源码]()
JPA
简介
JPA是Java Persistence API的简称,中文名Java持久层API,是JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
Sun引入新的JPA ORM规范出于两个原因:其一,简化现有Java EE和Java SE应用开发工作;其二,Sun希望整合ORM技术,实现天下归一。
回顾JDBC
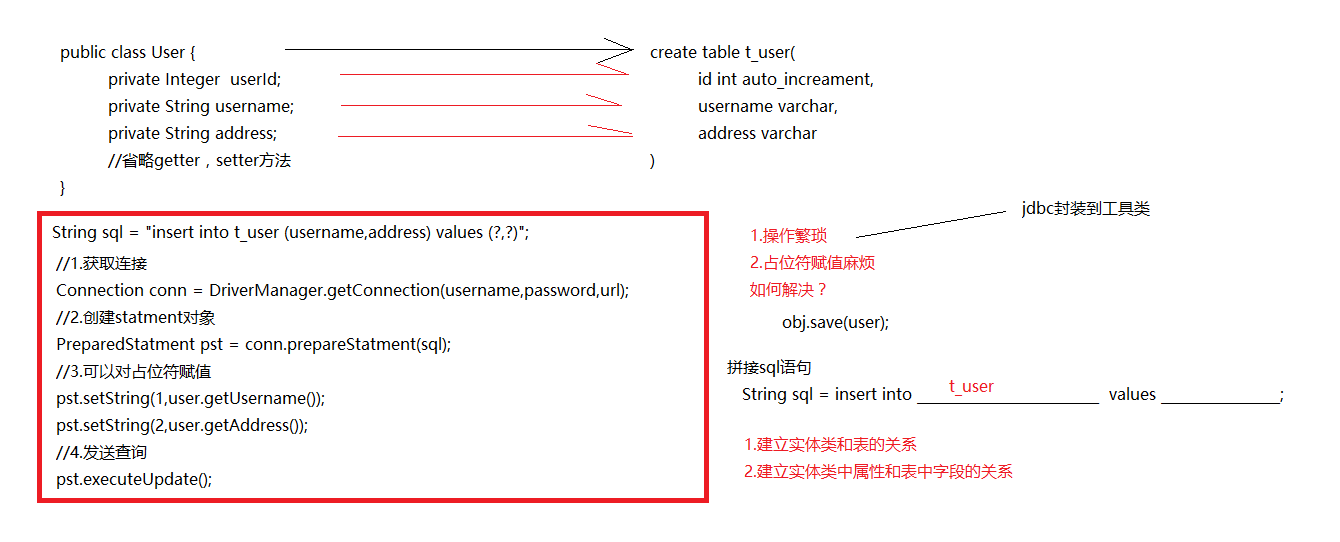
orm思想
主要目的:操作实体类就相当于操作数据库表
建立两个映射关系:
1)、实体类和表的映射关系
1)、实体类中属性和表中字段的映射关系
不再重点关注:sql语句
实现了ORM思想的框架:mybatis,hibernate
hibernate框架介绍
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架
JPA规范
jpa规范,实现jpa规范,内部是由接口和抽象类组成
jpa的基本操作
案例:是客户的相关操作(增删改查)
客户表:
/*创建客户表*/
CREATE TABLE cst_customer (
cust_id bigint(32) NOT NULL AUTO_INCREMENT COMMENT '客户编号(主键)',
cust_name varchar(32) NOT NULL COMMENT '客户名称(公司名称)',
cust_source varchar(32) DEFAULT NULL COMMENT '客户信息来源',
cust_industry varchar(32) DEFAULT NULL COMMENT '客户所属行业',
cust_level varchar(32) DEFAULT NULL COMMENT '客户级别',
cust_address varchar(128) DEFAULT NULL COMMENT '客户联系地址',
cust_phone varchar(64) DEFAULT NULL COMMENT '客户联系电话',
PRIMARY KEY (`cust_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
搭建环境的过程
1)、创建maven工程导入坐标
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itcast</groupId>
<artifactId>jpa-day1</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.hibernate.version>5.0.7.Final</project.hibernate.version>
</properties>
<dependencies>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- hibernate对jpa的支持包 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- c3p0 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- log日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- Mysql and MariaDB -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
</dependencies>
</project>
2)、需要配置jpa的核心配置文件
位置:配置到类路径下的一个叫做 META-INF 的文件夹下
命名:persistence.xml
<?xml version="1.0" encoding="UTF-8"?> <persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0"> <!--需要配置persistence-unit节点 持久化单元: name:持久化单元名称 transaction-type:事务管理的方式 JTA:分布式事务管理 RESOURCE_LOCAL:本地事务管理 --> <persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL"> <!--jpa的实现方式 --> <provider>org.hibernate.jpa.HibernatePersistenceProvider</provider> <!--可选配置:配置jpa实现方的配置信息--> <properties> <!-- 数据库信息 用户名,javax.persistence.jdbc.user 密码, javax.persistence.jdbc.password 驱动, javax.persistence.jdbc.driver 数据库地址 javax.persistence.jdbc.url --> <property name="javax.persistence.jdbc.user" value="root"/> <property name="javax.persistence.jdbc.password" value="root"/> <property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/> <property name="javax.persistence.jdbc.url" value="jdbc:mysql:///jpa"/> <!--配置jpa实现方(hibernate)的配置信息 显示sql : false|true 自动创建数据库表 : hibernate.hbm2ddl.auto create : 程序运行时创建数据库表(如果有表,先删除表再创建) update :程序运行时创建表(如果有表,不会创建表) none :不会创建表 --> <property name="hibernate.show_sql" value="true" /> <property name="hibernate.hbm2ddl.auto" value="update" /> </properties> </persistence-unit> </persistence>
3)、编写客户的实体类
4)、配置实体类和表,类中属性和表中字段的映射关系
/**
* 客户的实体类
* 配置映射关系
* 1.实体类和表的映射关系
* @Entity:声明实体类
* @Table : 配置实体类和表的映射关系
* name : 配置数据库表的名称
* 2.实体类中属性和表中字段的映射关系
*/
@Entity
@Table(name = "cst_customer")
public class Customer {
/**
* @Id:声明主键的配置
* @GeneratedValue:配置主键的生成策略
* strategy
* GenerationType.IDENTITY :自增,mysql
* * 底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增)
* GenerationType.SEQUENCE : 序列,oracle
* * 底层数据库必须支持序列
* GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增
* GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略
* @Column:配置属性和字段的映射关系
* name:数据库表中字段的名称
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cust_id")
private Long custId; //客户的主键
@Column(name = "cust_name")
private String custName;//客户名称
@Column(name="cust_source")
private String custSource;//客户来源
@Column(name="cust_level")
private String custLevel;//客户级别
@Column(name="cust_industry")
private String custIndustry;//客户所属行业
@Column(name="cust_phone")
private String custPhone;//客户的联系方式
@Column(name="cust_address")
private String custAddress;//客户地址
public Long getCustId() {
return custId;
}
public void setCustId(Long custId) {
this.custId = custId;
}
public String getCustName() {
return custName;
}
public void setCustName(String custName) {
this.custName = custName;
}
public String getCustSource() {
return custSource;
}
public void setCustSource(String custSource) {
this.custSource = custSource;
}
public String getCustLevel() {
return custLevel;
}
public void setCustLevel(String custLevel) {
this.custLevel = custLevel;
}
public String getCustIndustry() {
return custIndustry;
}
public void setCustIndustry(String custIndustry) {
this.custIndustry = custIndustry;
}
public String getCustPhone() {
return custPhone;
}
public void setCustPhone(String custPhone) {
this.custPhone = custPhone;
}
public String getCustAddress() {
return custAddress;
}
public void setCustAddress(String custAddress) {
this.custAddress = custAddress;
}
@Override
public String toString() {
return "Customer{" +
"custId=" + custId +
", custName='" + custName + '\'' +
", custSource='" + custSource + '\'' +
", custLevel='" + custLevel + '\'' +
", custIndustry='" + custIndustry + '\'' +
", custPhone='" + custPhone + '\'' +
", custAddress='" + custAddress + '\'' +
'}';
}
}
操作
Jpa的操作步骤
加载配置文件创建工厂(实体管理器工厂)对象
通过实体管理器工厂获取实体管理器
获取事务对象,开启事务
完成增删改查操作
提交事务(回滚事务)
释放资源
增加
/**
* 测试jpa的保存
* 案例:保存一个客户到数据库中
*/
@Test
public void testSave() {
// //1.加载配置文件创建工厂(实体管理器工厂)对象
// EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
// //2.通过实体管理器工厂获取实体管理器
// EntityManager em = factory.createEntityManager();
EntityManager em = JpaUtils.getEntityManager();
//3.获取事务对象,开启事务
EntityTransaction tx = em.getTransaction(); //获取事务对象
tx.begin();//开启事务
//4.完成增删改查操作:保存一个客户到数据库中
Customer customer = new Customer();
customer.setCustName("xxx");
customer.setCustIndustry("zzz");
//保存,
em.persist(customer); //保存操作
//5.提交事务
tx.commit();
//6.释放资源
em.close();
// factory.close();
}
查询
/**
* 根据id查询客户
* 使用find方法查询:
* 1.查询的对象就是当前客户对象本身
* 2.在调用find方法的时候,就会发送sql语句查询数据库
* 立即加载
*/
@Test
public void testFind() {
//1.通过工具类获取entityManager
EntityManager entityManager = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//3.增删改查 -- 根据id查询客户
/**
* find : 根据id查询数据
* class:查询数据的结果需要包装的实体类类型的字节码
* id:查询的主键的取值
*/
Customer customer = entityManager.find(Customer.class, 1l);
// System.out.print(customer);
//4.提交事务
tx.commit();
//5.释放资源
entityManager.close();
}
/**
* 根据id查询客户
* getReference方法
* 1.获取的对象是一个动态代理对象
* 2.调用getReference方法不会立即发送sql语句查询数据库
* * 当调用查询结果对象的时候,才会发送查询的sql语句:什么时候用,什么时候发送sql语句查询数据库
* 延迟加载(懒加载)
* * 得到的是一个动态代理对象
* * 什么时候用,什么使用才会查询
*/
@Test
public void testReference() {
//1.通过工具类获取entityManager
EntityManager entityManager = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//3.增删改查 -- 根据id查询客户
/**
* getReference : 根据id查询数据
* class:查询数据的结果需要包装的实体类类型的字节码
* id:查询的主键的取值
*/
Customer customer = entityManager.getReference(Customer.class, 1l);
System.out.print(customer);
//4.提交事务
tx.commit();
//5.释放资源
entityManager.close();
}
删除
/**
* 删除客户的案例
*/
@Test
public void testRemove() {
//1.通过工具类获取entityManager
EntityManager entityManager = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//3.增删改查 -- 删除客户
//i 根据id查询客户
Customer customer = entityManager.find(Customer.class,1l);
//ii 调用remove方法完成删除操作
entityManager.remove(customer);
//4.提交事务
tx.commit();
//5.释放资源
entityManager.close();
}
更新
/**
* 更新客户的操作
* merge(Object)
*/
@Test
public void testUpdate() {
//1.通过工具类获取entityManager
EntityManager entityManager = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//3.增删改查 -- 更新操作
//i 查询客户
Customer customer = entityManager.find(Customer.class,1l);
//ii 更新客户
customer.setCustIndustry("it教育");
entityManager.merge(customer);
//4.提交事务
tx.commit();
//5.释放资源
entityManager.close();
}
jpa操作的操作步骤
1)、加载配置文件创建实体管理器工厂
Persisitence:静态方法(根据持久化单元名称创建实体管理器工厂)
createEntityMnagerFactory(持久化单元名称)
作用:创建实体管理器工厂
2)、根据实体管理器工厂,创建实体管理器
EntityManagerFactory :获取EntityManager对象
方法:createEntityManager
内部维护的很多的内容
内部维护了数据库信息,
维护了缓存信息
维护了所有的实体管理器对象
再创建EntityManagerFactory的过程中会根据配置创建数据库表
EntityManagerFactory的创建过程比较浪费资源
特点:线程安全的对象
多个线程访问同一个EntityManagerFactory不会有线程安全问题
如何解决EntityManagerFactory的创建过程浪费资源(耗时)的问题?
思路:创建一个公共的EntityManagerFactory的对象
静态代码块的形式创建EntityManagerFactory
3)、创建事务对象,开启事务 EntityManager对象:实体类管理器
beginTransaction : 创建事务对象
presist : 保存
merge : 更新
remove : 删除
find/getRefrence : 根据id查询
Transaction 对象 : 事务
begin:开启事务
commit:提交事务
rollback:回滚
创建一个工具类
/**
* 解决实体管理器工厂的浪费资源和耗时问题
* 通过静态代码块的形式,当程序第一次访问此工具类时,创建一个公共的实体管理器工厂对象
*
* 第一次访问getEntityManager方法:经过静态代码块创建一个factory对象,再调用方法创建一个EntityManager对象
* 第二次方法getEntityManager方法:直接通过一个已经创建好的factory对象,创建EntityManager对象
*/
public class JpaUtils {
private static EntityManagerFactory factory;
static {
//1.加载配置文件,创建entityManagerFactory
factory = Persistence.createEntityManagerFactory("myJpa");
}
/**
* 获取EntityManager对象
*/
public static EntityManager getEntityManager() {
return factory.createEntityManager();
}
}
4)、增删改查操作
5)、提交事务
6)、释放资源
jpql查询
sql:查询的是表和表中的字段
jpql:查询的是实体类和类中的属性
jpql和sql语句的语法相似
- 查询全部
- 分页查询
- 统计查询
- 条件查询
- 排序
查询全部
/**
* 查询全部
* jqpl:from cn.itcast.domain.Customer
* sql:SELECT * FROM cst_customer
*/
@Test
public void testFindAll() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
String jpql = "from Customer ";
Query query = em.createQuery(jpql);//创建Query查询对象,query对象才是执行jqpl的对象
//发送查询,并封装结果集
List list = query.getResultList();
for (Object obj : list) {
System.out.print(obj);
}
//4.提交事务
tx.commit();
//5.释放资源
em.close();
}
排序查询
/**
* 排序查询: 倒序查询全部客户(根据id倒序)
* sql:SELECT * FROM cst_customer ORDER BY cust_id DESC
* jpql:from Customer order by custId desc
*
* 进行jpql查询
* 1.创建query查询对象
* 2.对参数进行赋值
* 3.查询,并得到返回结果
*/
@Test
public void testOrders() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
String jpql = "from Customer order by custId desc";
Query query = em.createQuery(jpql);//创建Query查询对象,query对象才是执行jqpl的对象
//发送查询,并封装结果集
List list = query.getResultList();
for (Object obj : list) {
System.out.println(obj);
}
//4.提交事务
tx.commit();
//5.释放资源
em.close();
}
总数
/**
* 使用jpql查询,统计客户的总数
* sql:SELECT COUNT(cust_id) FROM cst_customer
* jpql:select count(custId) from Customer
*/
@Test
public void testCount() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
//i.根据jpql语句创建Query查询对象
String jpql = "select count(custId) from Customer";
Query query = em.createQuery(jpql);
//ii.对参数赋值
//iii.发送查询,并封装结果
/**
* getResultList : 直接将查询结果封装为list集合
* getSingleResult : 得到唯一的结果集
*/
Object result = query.getSingleResult();
System.out.println(result);
//4.提交事务
tx.commit();
//5.释放资源
em.close();
}
分页查询
/**
* 分页查询
* sql:select * from cst_customer limit 0,2
* jqpl : from Customer
*/
@Test
public void testPaged() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
//i.根据jpql语句创建Query查询对象
String jpql = "from Customer";
Query query = em.createQuery(jpql);
//ii.对参数赋值 -- 分页参数
//起始索引
query.setFirstResult(0);
//每页查询的条数
query.setMaxResults(2);
//iii.发送查询,并封装结果
/**
* getResultList : 直接将查询结果封装为list集合
* getSingleResult : 得到唯一的结果集
*/
List list = query.getResultList();
for(Object obj : list) {
System.out.println(obj);
}
//4.提交事务
tx.commit();
//5.释放资源
em.close();
}
条件查询
/**
* 条件查询
* 案例:查询客户名称以‘xxx’开头的客户
* sql:SELECT * FROM cst_customer WHERE cust_name LIKE ?
* jpql : from Customer where custName like ?
*/
@Test
public void testCondition() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
//i.根据jpql语句创建Query查询对象
String jpql = "from Customer where custName like ? ";
Query query = em.createQuery(jpql);
//ii.对参数赋值 -- 占位符参数
//第一个参数:占位符的索引位置(从1开始),第二个参数:取值
query.setParameter(1,"xxx%");
//iii.发送查询,并封装结果
/**
* getResultList : 直接将查询结果封装为list集合
* getSingleResult : 得到唯一的结果集
*/
List list = query.getResultList();
for(Object obj : list) {
System.out.println(obj);
}
//4.提交事务
tx.commit();
//5.释放资源
em.close();
}
springDataJPA
简介
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
Spring Data JPA 让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦
SpringData Jpa 极大简化了数据库访问层代码。 如何简化的呢? 使用了SpringDataJpa,我们的dao层中只需要写接口,就自动具有了增删改查、分页查询等方法。
springDataJPA和JPA和Hibernate之间的关系
springDataJPA只是将JPA规范的代码给封装起来了,底层使用的还是Hibernate进行操作的。
JPA是一套规范,内部是有接口和抽象类组成的。hibernate是一套成熟的ORM框架,而且Hibernate实现了JPA规范,所以也可以称hibernate为JPA的一种实现方式,我们使用JPA的API编程,意味着站在更高的角度上看待问题(面向接口编程)
Spring Data JPA是Spring提供的一套对JPA操作更加高级的封装,是在JPA规范下的专门用来进行数据持久化的解决方案。
搭建环境
1)、创建工程导入坐标
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itcast</groupId>
<artifactId>jpa-day2</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spring.version>5.0.2.RELEASE</spring.version>
<hibernate.version>5.0.7.Final</hibernate.version>
<slf4j.version>1.6.6</slf4j.version>
<log4j.version>1.2.12</log4j.version>
<c3p0.version>0.9.1.2</c3p0.version>
<mysql.version>5.1.6</mysql.version>
</properties>
<dependencies>
<!-- junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- spring beg -->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.6.8</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- spring对orm框架的支持包-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- spring end -->
<!-- hibernate beg -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.2.1.Final</version>
</dependency>
<!-- hibernate end -->
<!-- c3p0 beg -->
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>${c3p0.version}</version>
</dependency>
<!-- c3p0 end -->
<!-- log end -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- log end -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- spring data jpa 的坐标-->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.9.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- el beg 使用spring data jpa 必须引入 -->
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>javax.el</artifactId>
<version>2.2.4</version>
</dependency>
<!-- el end -->
</dependencies>
</project>
2)、配置spring的配置文件(配置spring Data jpa的整合)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:jpa="http://www.springframework.org/schema/data/jpa" xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<!--spring 和 spring data jpa的配置-->
<!-- 1.创建entityManagerFactory对象交给spring容器管理-->
<bean id="entityManagerFactoty" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<!--配置的扫描的包(实体类所在的包) -->
<property name="packagesToScan" value="cn.itcast.domain" />
<!-- jpa的实现厂家 -->
<property name="persistenceProvider">
<bean class="org.hibernate.jpa.HibernatePersistenceProvider"/>
</property>
<!--jpa的供应商适配器 -->
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<!--配置是否自动创建数据库表 -->
<property name="generateDdl" value="false" />
<!--指定数据库类型 -->
<property name="database" value="MYSQL" />
<!--数据库方言:支持的特有语法 -->
<property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect" />
<!--是否显示sql -->
<property name="showSql" value="true" />
</bean>
</property>
<!--jpa的方言 :高级的特性 -->
<property name="jpaDialect" >
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect" />
</property>
</bean>
<!--2.创建数据库连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="root"></property>
<property name="password" value="111111"></property>
<property name="jdbcUrl" value="jdbc:mysql:///jpa" ></property>
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
</bean>
<!--3.整合spring dataJpa-->
<jpa:repositories base-package="cn.itcast.dao" transaction-manager-ref="transactionManager"
entity-manager-factory-ref="entityManagerFactoty" ></jpa:repositories>
<!--4.配置事务管理器 -->
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactoty"></property>
</bean>
<!-- 4.txAdvice-->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="save*" propagation="REQUIRED"/>
<tx:method name="insert*" propagation="REQUIRED"/>
<tx:method name="update*" propagation="REQUIRED"/>
<tx:method name="delete*" propagation="REQUIRED"/>
<tx:method name="get*" read-only="true"/>
<tx:method name="find*" read-only="true"/>
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- 5.aop-->
<aop:config>
<aop:pointcut id="pointcut" expression="execution(* cn.itcast.service.*.*(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="pointcut" />
</aop:config>
<!--5.声明式事务 -->
<!-- 6. 配置包扫描-->
<context:component-scan base-package="cn.itcast" ></context:component-scan>
</beans>
3)、编写实体类(Customer),使用jpa注解配置映射关系
/**
* 1.实体类和表的映射关系
* @Eitity
* @Table
* 2.类中属性和表中字段的映射关系
* @Id
* @GeneratedValue
* @Column
*/
@Entity
@Table(name="cst_customer")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name="cust_id")
private Long custId;
@Column(name="cust_address")
private String custAddress;
@Column(name="cust_industry")
private String custIndustry;
@Column(name="cust_level")
private String custLevel;
@Column(name="cust_name")
private String custName;
@Column(name="cust_phone")
private String custPhone;
@Column(name="cust_source")
private String custSource;
public Long getCustId() {
return custId;
}
public void setCustId(Long custId) {
this.custId = custId;
}
public String getCustAddress() {
return custAddress;
}
public void setCustAddress(String custAddress) {
this.custAddress = custAddress;
}
public String getCustIndustry() {
return custIndustry;
}
public void setCustIndustry(String custIndustry) {
this.custIndustry = custIndustry;
}
public String getCustLevel() {
return custLevel;
}
public void setCustLevel(String custLevel) {
this.custLevel = custLevel;
}
public String getCustName() {
return custName;
}
public void setCustName(String custName) {
this.custName = custName;
}
public String getCustPhone() {
return custPhone;
}
public void setCustPhone(String custPhone) {
this.custPhone = custPhone;
}
public String getCustSource() {
return custSource;
}
public void setCustSource(String custSource) {
this.custSource = custSource;
}
@Override
public String toString() {
return "Customer{" +
"custId=" + custId +
", custAddress='" + custAddress + '\'' +
", custIndustry='" + custIndustry + '\'' +
", custLevel='" + custLevel + '\'' +
", custName='" + custName + '\'' +
", custPhone='" + custPhone + '\'' +
", custSource='" + custSource + '\'' +
'}';
}
}
操作
dao层接口
编写一个符合springDataJpa的dao层接口
只需要编写dao层接口,不需要编写dao层接口的实现类
dao层接口规范
- 需要继承两个接口(JpaRepository,JpaSpecificationExecutor)
需要提供响应的泛型
/** * 符合SpringDataJpa的dao层接口规范 * JpaRepository<操作的实体类类型,实体类中主键属性的类型> * * 封装了基本CRUD操作 * JpaSpecificationExecutor<操作的实体类类型> * * 封装了复杂查询(分页) */ public interface CustomerDao extends JpaRepository<Customer,Long> ,JpaSpecificationExecutor<Customer> { }
创建测试类
@RunWith(SpringJUnit4ClassRunner.class) //声明spring提供的单元测试环境
@ContextConfiguration(locations = "classpath:applicationContext.xml")//指定spring容器的配置信息
public class CustomerDaoTest {
}
查询
/**
* 根据id查询
*/
@Test
public void testFindOne() {
Customer customer = customerDao.findOne(4l);
System.out.println(customer);
}
/**
* 根据id从数据库查询
* @Transactional : 保证getOne正常运行
*
* findOne:
* em.find() :立即加载
* getOne:
* em.getReference :延迟加载
* * 返回的是一个客户的动态代理对象
* * 什么时候用,什么时候查询
*/
@Test
@Transactional
public void testGetOne() {
Customer customer = customerDao.getOne(4l);
System.out.println(customer);
}
增加
/**
* save : 保存或者更新
* 根据传递的对象是否存在主键id,
* 如果没有id主键属性:保存
* 存在id主键属性,根据id查询数据,更新数据
*/
@Test
public void testSave() {
Customer customer = new Customer();
customer.setCustName("xxx");
customer.setCustLevel("vip");
customer.setCustIndustry("it教育");
customerDao.save(customer);
}
更新
@Test
public void testUpdate() {
Customer customer = new Customer();
customer.setCustId(4l);
customer.setCustName("xxx");
customerDao.save(customer);
}
删除
@Test
public void testDelete () {
customerDao.delete(3l);
}
查询全部
/**
* 查询所有
*/
@Test
public void testFindAll() {
List<Customer> list = customerDao.findAll();
for(Customer customer : list) {
System.out.println(customer);
}
}
查询总数
/**
* 测试统计查询:查询客户的总数量
* count:统计总条数
*/
@Test
public void testCount() {
long count = customerDao.count();//查询全部的客户数量
System.out.println(count);
}
是否存在
/**
* 测试:判断id为4的客户是否存在
* 1. 可以查询以下id为4的客户
* 如果值为空,代表不存在,如果不为空,代表存在
* 2. 判断数据库中id为4的客户的数量
* 如果数量为0,代表不存在,如果大于0,代表存在
*/
@Test
public void testExists() {
boolean exists = customerDao.exists(4l);
System.out.println("id为4的客户 是否存在:"+exists);
}
简单的增删改查dao接口只需要JpaRepository<Customer,Long> ,JpaSpecificationExecutor<Customer> 即可
接口真正发挥作用:接口的实现类
在程序执行的过程中,自动的帮助我们动态的生成了接口的实现类对象
如何动态的生成实现类对象?
动态代理(生成基于接口的实现类对象)
springDataJpa的运行过程和原理剖析

1. 通过JdkDynamicAopProxy的invoke方法创建了一个动态代理对象
2. SimpleJpaRepository当中封装了JPA的操作(借助JPA的api完成数据库的CRUD)
3. 通过hibernate完成数据库操作(封装了jdbc)
复杂查询
借助接口中的定义好的方法完成查询
如上面的增删改查
jpql的查询方式
jpql : jpa query language (jpq查询语言)
特点:语法或关键字和sql语句类似;查询的是类和类中的属性
需要将JPQL语句配置到接口方法上
- 特有的查询:需要在dao接口上配置方法
- 在新添加的方法上,使用注解的形式配置jpql查询语句
- 注解 : @Query
查询
/**
* 案例:根据客户名称查询客户
* 使用jpql的形式查询
* jpql:from Customer where custName = ?
*
* 配置jpql语句,使用的@Query注解
*/
@Query(value="from Customer where custName = ?")
public Customer findJpql(String custName);
@Test
public void testFindJPQL() {
Customer customer = customerDao.findJpql("xxx");
System.out.println(customer);
}
多条件查询
/**
* 案例:根据客户名称和客户id查询客户
* jpql: from Customer where custName = ? and custId = ?
*
* 对于多个占位符参数
* 赋值的时候,默认的情况下,占位符的位置需要和方法参数中的位置保持一致
*
* 可以指定占位符参数的位置
* ? 索引的方式,指定此占位的取值来源
*/
@Query(value = "from Customer where custName = ?2 and custId = ?1")
public Customer findCustNameAndId(Long id,String name);
@Test
public void testFindCustNameAndId() {
// Customer customer = customerDao.findCustNameAndId("xxx",1l);
Customer customer = customerDao.findCustNameAndId(1l,"xxx");
System.out.println(customer);
}
更新
/**
* 使用jpql完成更新操作
* 案例 : 根据id更新,客户的名称
* 更新4号客户的名称,将名称改为“黑马程序员”
*
* sql :update cst_customer set cust_name = ? where cust_id = ?
* jpql : update Customer set custName = ? where custId = ?
*
* @Query : 代表的是进行查询
* * 声明此方法是用来进行更新操作
* @Modifying
* * 当前执行的是一个更新操作
*
*/
@Query(value = " update Customer set custName = ?2 where custId = ?1 ")
@Modifying
public void updateCustomer(long custId,String custName);
/**
* 测试jpql的更新操作
* * springDataJpa中使用jpql完成 更新/删除操作
* * 需要手动添加事务的支持
* * 默认会执行结束之后,回滚事务
* @Rollback : 设置是否自动回滚
* false | true
*/
@Test
@Transactional //添加事务的支持
@Rollback(value = false)
public void testUpdateCustomer() {
customerDao.updateCustomer(4l,"黑马程序员");
}
sql查询
/**
* 使用sql的形式查询:
* 查询全部的客户
* sql : select * from cst_customer;
* Query : 配置sql查询
* value : sql语句
* nativeQuery : 查询方式
* true : sql查询
* false:jpql查询
*
*/
//@Query(value = " select * from cst_customer" ,nativeQuery = true)
@Query(value="select * from cst_customer where cust_name like ?1",nativeQuery = true)
public List<Object [] > findSql(String name);
//测试sql查询
@Test
public void testFindSql() {
List<Object[]> list = customerDao.findSql("xx%");
for(Object [] obj : list) {
System.out.println(Arrays.toString(obj));
}
}
命名规则的查询
/**
* 方法名的约定:
* findBy : 查询
* 对象中的属性名(首字母大写) : 查询的条件
* CustName
* * 默认情况 : 使用 等于的方式查询
* 特殊的查询方式
*
* findByCustName -- 根据客户名称查询
*
* 再springdataJpa的运行阶段
* 会根据方法名称进行解析 findBy from xxx(实体类)
* 属性名称 where custName =
*
* 1.findBy + 属性名称 (根据属性名称进行完成匹配的查询=)
* 2.findBy + 属性名称 + “查询方式(Like | isnull)”
* findByCustNameLike
* 3.多条件查询
* findBy + 属性名 + “查询方式” + “多条件的连接符(and|or)” + 属性名 + “查询方式”
*/
public Customer findByCustName(String custName);
public List<Customer> findByCustNameLike(String custName);
//使用客户名称模糊匹配和客户所属行业精准匹配的查询
public Customer findByCustNameLikeAndCustIndustry(String custName,String custIndustry);
//测试方法命名规则的查询
@Test
public void testNaming() {
Customer customer = customerDao.findByCustName("xxx");
System.out.println(customer);
}
//测试方法命名规则的查询
@Test
public void testFindByCustNameLike() {
List<Customer> list = customerDao.findByCustNameLike("xxx%");
for (Customer customer : list) {
System.out.println(customer);
}
}
//测试方法命名规则的查询
@Test
public void testFindByCustNameLikeAndCustIndustry() {
Customer customer = customerDao.findByCustNameLikeAndCustIndustry("xxx%", "yy");
System.out.println(customer);
}
Specifications动态查询
方法列表
JpaSpecificationExecutor 方法列表
T findOne(Specification<T> spec); //查询单个对象
List<T> findAll(Specification<T> spec); //查询列表
//查询全部,分页
//pageable:分页参数
//返回值:分页pageBean(page:是springdatajpa提供的)
Page<T> findAll(Specification<T> spec, Pageable pageable);
//查询列表
//Sort:排序参数
List<T> findAll(Specification<T> spec, Sort sort);
long count(Specification<T> spec);//统计查询
Specification :查询条件
自定义我们自己的Specification实现类
实现
//root:查询的根对象(查询的任何属性都可以从根对象中获取)
//CriteriaQuery:顶层查询对象,自定义查询方式(了解:一般不用)
//CriteriaBuilder:查询的构造器,封装了很多的查询条件
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb); //封装查询条件
动态查询
查询单个对象
/**
* 根据条件,查询单个对象
*
*/
@Test
public void testSpec() {
//匿名内部类
/**
* 自定义查询条件
* 1.实现Specification接口(提供泛型:查询的对象类型)
* 2.实现toPredicate方法(构造查询条件)
* 3.需要借助方法参数中的两个参数(
* root:获取需要查询的对象属性
* CriteriaBuilder:构造查询条件的,内部封装了很多的查询条件(模糊匹配,精准匹配)
* )
* 案例:根据客户名称查询,查询客户名为xxx的客户
* 查询条件
* 1.查询方式
* cb对象
* 2.比较的属性名称
* root对象
*/
Specification<Customer> spec = new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//1.获取比较的属性
Path<Object> custName = root.get("custId");
//2.构造查询条件 : select * from cst_customer where cust_name = 'xxx'
/**
* 第一个参数:需要比较的属性(path对象)
* 第二个参数:当前需要比较的取值
*/
Predicate predicate = cb.equal(custName, "xxx");//进行精准的匹配 (比较的属性,比较的属性的取值)
return predicate;
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
多条件查询
/**
* 多条件查询
* 案例:根据客户名(xx)和客户所属行业查询(it教育)
*/
@Test
public void testSpec1() {
/**
* root:获取属性
* 客户名
* 所属行业
* cb:构造查询
* 1.构造客户名的精准匹配查询
* 2.构造所属行业的精准匹配查询
* 3.将以上两个查询联系起来
*/
Specification<Customer> spec = new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
Path<Object> custName = root.get("custName");//客户名
Path<Object> custIndustry = root.get("custIndustry");//所属行业
//构造查询
//1.构造客户名的精准匹配查询
Predicate p1 = cb.equal(custName, "xxx");//第一个参数,path(属性),第二个参数,属性的取值
//2..构造所属行业的精准匹配查询
Predicate p2 = cb.equal(custIndustry, "it教育");
//3.将多个查询条件组合到一起:组合(满足条件一并且满足条件二:与关系,满足条件一或满足条件二即可:或关系)
Predicate and = cb.and(p1, p2);//以与的形式拼接多个查询条件
// cb.or();//以或的形式拼接多个查询条件
return and;
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
模糊查询
/**
* 案例:完成根据客户名称的模糊匹配,返回客户列表
* 客户名称以 ’传智播客‘ 开头
*
* equal :直接的到path对象(属性),然后进行比较即可
* gt,lt,ge,le,like : 得到path对象,根据path指定比较的参数类型,再去进行比较
* 指定参数类型:path.as(类型的字节码对象)
*/
@Test
public void testSpec3() {
//构造查询条件
Specification<Customer> spec = new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//查询属性:客户名
Path<Object> custName = root.get("custName");
//查询方式:模糊匹配
Predicate like = cb.like(custName.as(String.class), "传智播客%");
return like;
}
};
// List<Customer> list = customerDao.findAll(spec);
// for (Customer customer : list) {
// System.out.println(customer);
// }
//添加排序
//创建排序对象,需要调用构造方法实例化sort对象
//第一个参数:排序的顺序(倒序,正序)
// Sort.Direction.DESC:倒序
// Sort.Direction.ASC : 升序
//第二个参数:排序的属性名称
Sort sort = new Sort(Sort.Direction.DESC,"custId");
List<Customer> list = customerDao.findAll(spec, sort);
for (Customer customer : list) {
System.out.println(customer);
}
}
分页查询
/**
* 分页查询
* Specification: 查询条件
* Pageable:分页参数
* 分页参数:查询的页码,每页查询的条数
* findAll(Specification,Pageable):带有条件的分页
* findAll(Pageable):没有条件的分页
* 返回:Page(springDataJpa为我们封装好的pageBean对象,数据列表,共条数)
*/
@Test
public void testSpec4() {
Specification spec = null;
//PageRequest对象是Pageable接口的实现类
/**
* 创建PageRequest的过程中,需要调用他的构造方法传入两个参数
* 第一个参数:当前查询的页数(从0开始)
* 第二个参数:每页查询的数量
*/
Pageable pageable = new PageRequest(0,2);
//分页查询
Page<Customer> page = customerDao.findAll(null, pageable);
System.out.println(page.getContent()); //得到数据集合列表
System.out.println(page.getTotalElements());//得到总条数
System.out.println(page.getTotalPages());//得到总页数
}
多表查询
表关系
一对一
一对多:
一的一方:主表
多的一方:从表
外键:需要再从表上新建一列作为外键,他的取值来源于主表的主键
多对多:
- 中间表:中间表中最少应该由两个字段组成,这两个字段做为外键指向两张表的主键,又组成了联合主键
实体类中的关系
包含关系:可以通过实体类中的包含关系描述表关系
继承关系
分析步骤
- 明确表关系
- 确定表关系(描述 外键|中间表)
- 编写实体类,再实体类中描述表关系(包含关系)
- 配置映射关系
一对多
案例:客户和联系人的案例(一对多关系)
客户:一家公司
联系人:这家公司的员工
一个客户可以具有多个联系人
一个联系人从属于一家公司
分析步骤
明确表关系
一对多关系
确定表关系(描述 外键|中间表)
主表:客户表
从表:联系人表
再从表上添加外键
编写实体类,再实体类中描述表关系(包含关系)
客户:再客户的实体类中包含一个联系人的集合
联系人:在联系人的实体类中包含一个客户的对象
配置映射关系
使用jpa注解配置一对多映射关系
创建表
/*创建客户表*/
CREATE TABLE cst_customer (
cust_id bigint(32) NOT NULL AUTO_INCREMENT COMMENT '客户编号(主键)',
cust_name varchar(32) NOT NULL COMMENT '客户名称(公司名称)',
cust_source varchar(32) DEFAULT NULL COMMENT '客户信息来源',
cust_industry varchar(32) DEFAULT NULL COMMENT '客户所属行业',
cust_level varchar(32) DEFAULT NULL COMMENT '客户级别',
cust_address varchar(128) DEFAULT NULL COMMENT '客户联系地址',
cust_phone varchar(64) DEFAULT NULL COMMENT '客户联系电话',
PRIMARY KEY (`cust_id`)
) ENGINE=InnoDB AUTO_INCREMENT=94 DEFAULT CHARSET=utf8;
/*创建联系人表*/
CREATE TABLE cst_linkman (
lkm_id bigint(32) NOT NULL AUTO_INCREMENT COMMENT '联系人编号(主键)',
lkm_name varchar(16) DEFAULT NULL COMMENT '联系人姓名',
lkm_gender char(1) DEFAULT NULL COMMENT '联系人性别',
lkm_phone varchar(16) DEFAULT NULL COMMENT '联系人办公电话',
lkm_mobile varchar(16) DEFAULT NULL COMMENT '联系人手机',
lkm_email varchar(64) DEFAULT NULL COMMENT '联系人邮箱',
lkm_position varchar(16) DEFAULT NULL COMMENT '联系人职位',
lkm_memo varchar(512) DEFAULT NULL COMMENT '联系人备注',
lkm_cust_id bigint(32) NOT NULL COMMENT '客户id(外键)',
PRIMARY KEY (`lkm_id`),
KEY `FK_cst_linkman_lkm_cust_id` (`lkm_cust_id`),
CONSTRAINT `FK_cst_linkman_lkm_cust_id` FOREIGN KEY (`lkm_cust_id`) REFERENCES `cst_customer` (`cust_id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
实体类和Dao
//配置客户和联系人之间的关系(一对多关系)
/**
* 使用注解的形式配置多表关系
* 1.声明关系
* @OneToMany : 配置一对多关系
* targetEntity :对方对象的字节码对象
* 2.配置外键(中间表)
* @JoinColumn : 配置外键
* name:外键字段名称
* referencedColumnName:参照的主表的主键字段名称
* * * 在客户实体类上(一的一方)添加了外键了配置,所以对于客户而言,也具备了维护外键的作用
*/
// @OneToMany(targetEntity = LinkMan.class)
// @JoinColumn(name = "lkm_cust_id",referencedColumnName = "cust_id")
/**
* 放弃外键维护权
* mappedBy:对方配置关系的属性名称\
* cascade : 配置级联(可以配置到设置多表的映射关系的注解上)
* CascadeType.all : 所有
* MERGE :更新
* PERSIST :保存
* REMOVE :删除
* fetch : 配置关联对象的加载方式
* EAGER :立即加载
* LAZY :延迟加载
*/
@OneToMany(mappedBy = "customer",cascade = CascadeType.ALL)
private Set<LinkMan> linkMans = new HashSet<>();
多对一
/**
* 配置联系人到客户的多对一关系
* 使用注解的形式配置多对一关系
* 1.配置表关系
* @ManyToOne : 配置多对一关系
* targetEntity:对方的实体类字节码
* 2.配置外键(中间表)
*
* * 配置外键的过程,配置到了多的一方,就会在多的一方维护外键
*
*/
@ManyToOne(targetEntity = Customer.class,fetch = FetchType.LAZY)
@JoinColumn(name = "lkm_cust_id",referencedColumnName = "cust_id")
private Customer customer;
测试一对多
/**
* 保存一个客户,保存一个联系人
* 效果:客户和联系人作为独立的数据保存到数据库中
* 联系人的外键为空
* 原因?
* 实体类中没有配置关系
*/
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testAdd() {
//创建一个客户,创建一个联系人
Customer customer = new Customer();
customer.setCustName("百度");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小李");
/**
* 配置了客户到联系人的关系
* 从客户的角度上:发送两条insert语句,发送一条更新语句更新数据库(更新外键)
* 由于我们配置了客户到联系人的关系:客户可以对外键进行维护
*/
customer.getLinkMans().add(linkMan);
customerDao.save(customer);
linkManDao.save(linkMan);
}
测试多对一
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testAdd1() {
//创建一个客户,创建一个联系人
Customer customer = new Customer();
customer.setCustName("百度");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小李");
/**
* 配置联系人到客户的关系(多对一)
* 只发送了两条insert语句
* 由于配置了联系人到客户的映射关系(多对一)
*/
linkMan.setCustomer(customer);
customerDao.save(customer);
linkManDao.save(linkMan);
}
/**
* 会有一条多余的update语句
* * 由于一的一方可以维护外键:会发送update语句
* * 解决此问题:只需要在一的一方放弃维护权即可
*/
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testAdd2() {
//创建一个客户,创建一个联系人
Customer customer = new Customer();
customer.setCustName("百度");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小李");
linkMan.setCustomer(customer);//由于配置了多的一方到一的一方的关联关系(当保存的时候,就已经对外键赋值)
customer.getLinkMans().add(linkMan);//由于配置了一的一方到多的一方的关联关系(发送一条update语句)
customerDao.save(customer);
linkManDao.save(linkMan);
}
删除从表数据:可以随时任意删除。
删除主表数据
有从表数据
1、在默认情况下,它会把外键字段置为null,然后删除主表数据。如果在数据库的表 结构上,外键字段有非空约束,默认情况就会报错了。
2、如果配置了放弃维护关联关系的权利,则不能删除(与外键字段是否允许为null, 没有关系)因为在删除时,它根本不会去更新从表的外键字段了。
3、如果还想删除,使用级联删除引用
没有从表数据引用:随便删
在实际开发中,级联删除请慎用!(在一对多的情况下)
级联添加删除
/**
* 级联添加:保存一个客户的同时,保存客户的所有联系人
* 需要在操作主体的实体类上,配置casacde属性
*/
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testCascadeAdd() {
Customer customer = new Customer();
customer.setCustName("百度1");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小李1");
linkMan.setCustomer(customer);
customer.getLinkMans().add(linkMan);
customerDao.save(customer);
}
/**
* 级联删除:
* 删除1号客户的同时,删除1号客户的所有联系人
*/
@Test
@Transactional //配置事务
@Rollback(false) //不自动回滚
public void testCascadeRemove() {
//1.查询1号客户
Customer customer = customerDao.findOne(1l);
//2.删除1号客户
customerDao.delete(customer);
}
多对多
多对多操作
案例:用户和角色(多对多关系)
用户:
角色:
分析步骤
明确表关系
多对多关系
确定表关系(描述 外键|中间表)
中间间表
编写实体类,再实体类中描述表关系(包含关系)
用户:包含角色的集合
角色:包含用户的集合
配置映射关系
类
@Entity
@Table(name = "sys_role")
public class Role {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "role_id")
private Long roleId;
@Column(name = "role_name")
private String roleName;
//配置多对多
@ManyToMany(mappedBy = "roles") //配置多表关系
private Set<User> users = new HashSet<>();
public Long getRoleId() {
return roleId;
}
public void setRoleId(Long roleId) {
this.roleId = roleId;
}
public String getRoleName() {
return roleName;
}
public void setRoleName(String roleName) {
this.roleName = roleName;
}
public Set<User> getUsers() {
return users;
}
public void setUsers(Set<User> users) {
this.users = users;
}
}
@Entity
@Table(name = "sys_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name="user_id")
private Long userId;
@Column(name="user_name")
private String userName;
@Column(name="age")
private Integer age;
/**
* 配置用户到角色的多对多关系
* 配置多对多的映射关系
* 1.声明表关系的配置
* @ManyToMany(targetEntity = Role.class) //多对多
* targetEntity:代表对方的实体类字节码
* 2.配置中间表(包含两个外键)
* @JoinTable
* name : 中间表的名称
* joinColumns:配置当前对象在中间表的外键
* @JoinColumn的数组
* name:外键名
* referencedColumnName:参照的主表的主键名
* inverseJoinColumns:配置对方对象在中间表的外键
*/
@ManyToMany(targetEntity = Role.class,cascade = CascadeType.ALL)
@JoinTable(name = "sys_user_role",
//joinColumns,当前对象在中间表中的外键
joinColumns = {@JoinColumn(name = "sys_user_id",referencedColumnName = "user_id")},
//inverseJoinColumns,对方对象在中间表的外键
inverseJoinColumns = {@JoinColumn(name = "sys_role_id",referencedColumnName = "role_id")}
)
private Set<Role> roles = new HashSet<>();
public Long getUserId() {
return userId;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Set<Role> getRoles() {
return roles;
}
public void setRoles(Set<Role> roles) {
this.roles = roles;
}
}
dao
public interface RoleDao extends JpaRepository<Role,Long> ,JpaSpecificationExecutor<Role> {
}
public interface UserDao extends JpaRepository<User,Long> ,JpaSpecificationExecutor<User> {
}
测试
/**
* 保存一个用户,保存一个角色
*
* 多对多放弃维护权:被动的一方放弃
*/
@Test
@Transactional
@Rollback(false)
public void testAdd() {
User user = new User();
user.setUserName("小李");
Role role = new Role();
role.setRoleName("java程序员");
//配置用户到角色关系,可以对中间表中的数据进行维护 1-1
user.getRoles().add(role);
//配置角色到用户的关系,可以对中间表的数据进行维护 1-1
role.getUsers().add(user);
userDao.save(user);
roleDao.save(role);
}
//测试级联添加(保存一个用户的同时保存用户的关联角色)
@Test
@Transactional
@Rollback(false)
public void testCasCadeAdd() {
User user = new User();
user.setUserName("小李");
Role role = new Role();
role.setRoleName("java程序员");
//配置用户到角色关系,可以对中间表中的数据进行维护 1-1
user.getRoles().add(role);
//配置角色到用户的关系,可以对中间表的数据进行维护 1-1
role.getUsers().add(user);
userDao.save(user);
}
/**
* 案例:删除id为1的用户,同时删除他的关联对象
*/
@Test
@Transactional
@Rollback(false)
public void testCasCadeRemove() {
//查询1号用户
User user = userDao.findOne(1l);
//删除1号用户
userDao.delete(user);
}
对象导航查询
//could not initialize proxy - no Session
//测试对象导航查询(查询一个对象的时候,通过此对象查询所有的关联对象)
@Test
@Transactional // 解决在java代码中的no session问题
public void testQuery1() {
//查询id为1的客户
Customer customer = customerDao.getOne(1l);
//对象导航查询,此客户下的所有联系人
Set<LinkMan> linkMans = customer.getLinkMans();
for (LinkMan linkMan : linkMans) {
System.out.println(linkMan);
}
}
/**
* 对象导航查询:
* 默认使用的是延迟加载的形式查询的
* 调用get方法并不会立即发送查询,而是在使用关联对象的时候才会差和讯
* 延迟加载!
* 修改配置,将延迟加载改为立即加载
* fetch,需要配置到多表映射关系的注解上
*
*/
@Test
@Transactional // 解决在java代码中的no session问题
public void testQuery2() {
//查询id为1的客户
Customer customer = customerDao.findOne(1l);
//对象导航查询,此客户下的所有联系人
Set<LinkMan> linkMans = customer.getLinkMans();
System.out.println(linkMans.size());
}
/**
* 从联系人对象导航查询他的所属客户
* * 默认 : 立即加载
* 延迟加载:
*
*/
@Test
@Transactional // 解决在java代码中的no session问题
public void testQuery3() {
LinkMan linkMan = linkManDao.findOne(2l);
//对象导航查询所属的客户
Customer customer = linkMan.getCustomer();
System.out.println(customer);
}
注意
对象导航查询
查询一个对象的同时,通过此对象查询他的关联对象
案例:客户和联系人
从一方查询多方
- 默认:使用延迟加载()
从多方查询一方
- 默认:使用立即加载
SpringData
简介
Spring Data : Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷。
SpringData 项目所支持 NoSQL 存储:
- MongoDB (文档数据库)
- Neo4j(图形数据库)
- Redis(键/值存储)
- Hbase(列族数据库)
SpringData 项目所支持的关系数据存储技术:
- JDBC
- JPA
JPA Spring Data : 致力于减少数据访问层 (DAO) 的开发量. 开发者唯一要做的,就只是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成!
框架怎么可能代替开发者实现业务逻辑呢?比如:当有一个 UserDao.findUserById() 这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。Spring Data JPA 做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
第一个springdata程序
使用 Spring Data JPA 进行持久层开发需要的四个步骤:
配置 Spring 整合 JPA
在 Spring 配置文件中配置 Spring Data,让 Spring 为声明的接口创建代理对象。配置了
<jpa:repositories>后,Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为 Spring Bean,业务层便可以通过 Spring 自动封装的特性来直接使用该对象。声明持久层的接口,该接口继承 Repository,Repository 是一个标记型接口,它不包含任何方法,如必要,Spring Data 可实现 Repository 其他子接口,其中定义了一些常用的增删改查,以及分页相关的方法。
在接口中声明需要的方法。Spring Data 将根据给定的策略(具体策略稍后讲解)来为其生成实现代码。
jar包
antlr-2.7.7.jar
c3p0-0.9.2.1.jar
com.springsource.net.sf.cglib-2.2.0.jar
com.springsource.org.aopallince....
com.springsource.org.aspectj.weave..
commons-logging-1.1.3.jar
dom4j-1.6.1.jar
hibernate-c3p0-4.2.4.Final.jar
hibernate -commons-annotations-4.0..
hibernate-core- 4.2.4.Final.jar
hibernate-entitymanager-4.2.4.Final.ja
hibernate-jpa-2.0-api-1.0.1.Final.jar
javassist-3.15.0-GA.jar
jboss-logging-3.1.0.GA.jar
jboss-transaction-api 1.1_ spec-1.0.1...
mchange-commons-java-0.2.3.4.jar
mysql-connectorjava-5.1.7-bin.jar
slf4j-api-1.6.1jar
spring-aop-4.0.0.RELEASEjar
spring-aspects-4.0.0.RELEASE.jar
spring-beans-4.0.0.RELEASE.jar
spring-context-4.0.0.RELEASE.jar
spring-core-4.0.0.RELEASE.jar
spring-data-commons-1.6.2.RELEASE..
spring-data-jpa-1 .4.2.RELEASE.jar
spring-expression-4.0.0.RELEASEjar
spring-jdbc-4.0.0.RELEASE.jar
spring-orm-4.0.0.RELEASE.jar
spring-tx-4.0.0.RELEASE.jar
spring-web-4.0.0.RELEASE.jar
spring-webmvc-4.0.0.RELEASE.jar
spring配置文件
<!-- 配置自动扫描的包 -->
<context:component-scan base-package="com.atguigu.springdata"></context:component-scan>
<!-- 1. 配置数据源 -->
<context:property-placeholder location="classpath:db.properties"/>
<bean id="dataSource"
class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="${jdbc.user}"></property>
<property name="password" value="${jdbc.password}"></property>
<property name="driverClass" value="${jdbc.driverClass}"></property>
<property name="jdbcUrl" value="${jdbc.jdbcUrl}"></property>
<!-- 配置其他属性 -->
</bean>
<!-- 2. 配置 JPA 的 EntityManagerFactory -->
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource"></property>
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"></bean>
</property>
<property name="packagesToScan" value="com.atguigu.springdata"></property>
<property name="jpaProperties">
<props>
<!-- 二级缓存相关 -->
<!--
<prop key="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</prop>
<prop key="net.sf.ehcache.configurationResourceName">ehcache-hibernate.xml</prop>
-->
<!-- 生成的数据表的列的映射策略 -->
<prop key="hibernate.ejb.naming_strategy">org.hibernate.cfg.ImprovedNamingStrategy</prop>
<!-- hibernate 基本属性 -->
<prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop>
<prop key="hibernate.show_sql">true</prop>
<prop key="hibernate.format_sql">true</prop>
<prop key="hibernate.hbm2ddl.auto">update</prop>
</props>
</property>
</bean>
<!-- 3. 配置事务管理器 -->
<bean id="transactionManager"
class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory"></property>
</bean>
<!-- 4. 配置支持注解的事务 -->
<tx:annotation-driven transaction-manager="transactionManager"/>
<!-- 5. 配置 SpringData -->
<!-- 加入 jpa 的命名空间 -->
<!-- base-package: 扫描 Repository Bean 所在的 package -->
<jpa:repositories base-package="com.atguigu.springdata"
entity-manager-factory-ref="entityManagerFactory"></jpa:repositories>
jdbc.user=root
jdbc.password=root
jdbc.driverClass=com.mysql.jdbc.Driver
jdbc.jdbcUrl=jdbc:mysql:///jpa
实体类
@Table(name="JPA_PERSONS")
@Entity
public class Person {
private Integer id;
private String lastName;
private String email;
private Date birth;
private Address address;
private Integer addressId;
@GeneratedValue
@Id
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Date getBirth() {
return birth;
}
public void setBirth(Date birth) {
this.birth = birth;
}
@Column(name="ADD_ID")
public Integer getAddressId() {
return addressId;
}
public void setAddressId(Integer addressId) {
this.addressId = addressId;
}
@JoinColumn(name="ADDRESS_ID")
@ManyToOne
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
@Override
public String toString() {
return "Person [id=" + id + ", lastName=" + lastName + ", email="
+ email + ", brith=" + birth + "]";
}
}
@Table(name="JPA_ADDRESSES")
@Entity
public class Address {
private Integer id;
private String province;
private String city;
@GeneratedValue
@Id
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
}
/**
* 1. Repository 是一个空接口. 即是一个标记接口
* 2. 若我们定义的接口继承了 Repository, 则该接口会被 IOC 容器识别为一个 Repository Bean.
* 纳入到 IOC 容器中. 进而可以在该接口中定义满足一定规范的方法.
*
* 3. 实际上, 也可以通过 @RepositoryDefinition 注解来替代继承 Repository 接口
*/
//@RepositoryDefinition(domainClass=Person.class,idClass=Integer.class)
public interface PersonRepsotory extends Repository<Person, Integer>{
//根据 lastName 来获取对应的 Person
Person getByLastName(String lastName);
}
Repository 接口概述
Repository 接口是 Spring Data 的一个核心接口,它不提供任何方法,开发者需要在自己定义的接口中声明需要的方法
public interface Repository<T, ID extends Serializable> { }
Spring Data可以让我们只定义接口,只要遵循 Spring Data的规范,就无需写实现类。
与继承 Repository 等价的一种方式,就是在持久层接口上使用 @RepositoryDefinition 注解,并为其指定 domainClass 和 idClass 属性。如下两种方式是完全等价的
Repository 的子接口
基础的 Repository 提供了最基本的数据访问功能,其几个子接口则扩展了一些功能。它们的继承关系如下:
Repository: 仅仅是一个标识,表明任何继承它的均为仓库接口类
CrudRepository: 继承 Repository,实现了一组 CRUD 相关的方法
PagingAndSortingRepository: 继承 CrudRepository,实现了一组分页排序相关的方法
JpaRepository: 继承 PagingAndSortingRepository,实现一组 JPA 规范相关的方法
自定义的 XxxxRepository 需要继承 JpaRepository,这样的 XxxxRepository 接口就具备了通用的数据访问控制层的能力。
JpaSpecificationExecutor: 不属于Repository体系,实现一组 JPA Criteria 查询相关的方法
SpringData 方法定义规范
在 Repository 子接口中声明方法
- 不是随便声明的. 而需要符合一定的规范
- 查询方法以 find | read | get 开头
- 涉及条件查询时,条件的属性用条件关键字连接
- 要注意的是:条件属性以首字母大写。
- 支持属性的级联查询. 若当前类有符合条件的属性, 则优先使用, 而不使用级联属性.
- 若需要使用级联属性, 则属性之间使用 _ 进行连接.
直接在接口中定义查询方法,如果是符合规范的,可以不用写实现,目前支持的关键字写法如下:
关键字

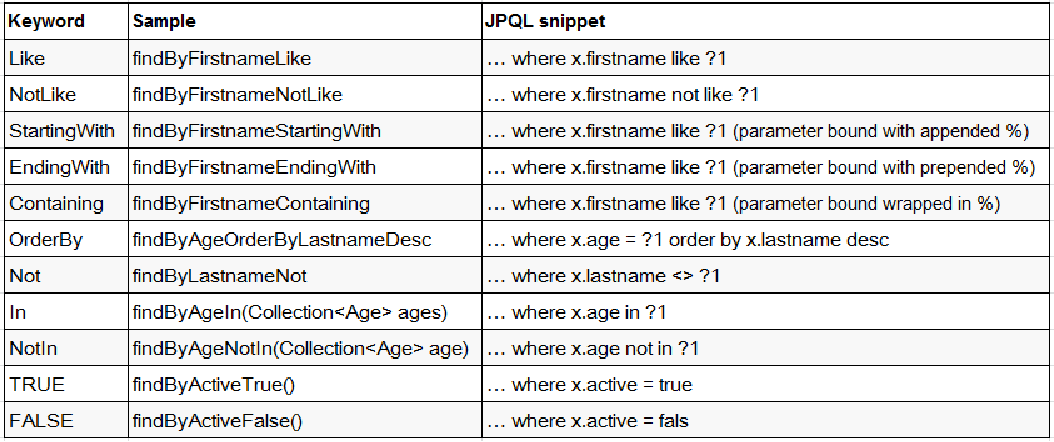
//WHERE lastName LIKE ?% AND id < ?
List<Person> getByLastNameStartingWithAndIdLessThan(String lastName, Integer id);
//WHERE lastName LIKE %? AND id < ?
List<Person> getByLastNameEndingWithAndIdLessThan(String lastName, Integer id);
//WHERE email IN (?, ?, ?) And birth < ?
List<Person> getByEmailInAndBirthLessThan(List<String> emails, Date birth);
@Test
public void testKeyWords(){
List<Person> persons = personRepsotory.getByLastNameStartingWithAndIdLessThan("X", 10);
System.out.println(persons);
persons = personRepsotory.getByLastNameEndingWithAndIdLessThan("X", 10);
System.out.println(persons);
persons = personRepsotory.getByEmailInAndBirthLessThan(Arrays.asList("AA@atguigu.com", "FF@atguigu.com",
"SS@atguigu.com"), new Date());
System.out.println(persons.size());
}
级联
//WHERE a.id > ?
List<Person> getByAddressIdGreaterThan(Integer id);
//WHERE a.id > ?
List<Person> getByAddress_IdGreaterThan(Integer id);
List<Person> persons = personRepsotory.getByAddressIdGreaterThan(1);
System.out.println(persons);
List<Person> persons = personRepsotory.getByAddress_IdGreaterThan(1);
System.out.println(persons);
若Person类中含有属性addressId,而他的属性address含有属性id,则会使用Person类中addressId的属性进行查询。要想使用address对象中的属性id进行查询的时候需要使用_下划线进行分割
流程解析
假如创建如下的查询:findByUserDepUuid(),框架在解析该方法时,首先剔除 findBy,然后对剩下的属性进行解析,假设查询实体为Doc
先判断 userDepUuid (根据 POJO 规范,首字母变为小写)是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步;
从右往左截取第一个大写字母开头的字符串(此处为Uuid),然后检查剩下的字符串是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复第二步,继续从右往左截取;最后假设 user 为查询实体的一个属性;
接着处理剩下部分(DepUuid),先判断 user 所对应的类型是否有depUuid属性,如果有,则表示该方法最终是根据 “ Doc.user.depUuid” 的取值进行查询;否则继续按照步骤 2 的规则从右往左截取,最终表示根据 “Doc.user.dep.uuid” 的值进行查询。
可能会存在一种特殊情况,比如 Doc包含一个 user 的属性,也有一个 userDep 属性,此时会存在混淆。可以明确在属性之间加上 “_” 以显式表达意图,比如 “findByUser_DepUuid()” 或者 “findByUserDep_uuid()”
特殊的参数: 还可以直接在方法的参数上加入分页或排序的参数,比如:
Page<UserModel> findByName(String name, Pageable pageable);
List<UserModel> findByName(String name, Sort sort);
@Query注解
这种查询可以声明在 Repository 方法中,摆脱像命名查询那样的约束,将查询直接在相应的接口方法中声明,结构更为清晰,这是 Spring data 的特有实现。
//查询 id 值最大的那个 Person
//使用 @Query 注解可以自定义 JPQL 语句以实现更灵活的查询
@Query("SELECT p FROM Person p WHERE p.id = (SELECT max(p2.id) FROM Person p2)")
Person getMaxIdPerson();
Person person = personRepsotory.getMaxIdPerson();
System.out.println(person);
传参方式一
//为 @Query 注解传递参数的方式1: 使用占位符.
@Query("SELECT p FROM Person p WHERE p.lastName = ?1 AND p.email = ?2")
List<Person> testQueryAnnotationParams1(String lastName, String email);
传参方式二
//为 @Query 注解传递参数的方式2: 命名参数的方式.
@Query("SELECT p FROM Person p WHERE p.lastName = :lastName AND p.email = :email")
List<Person> testQueryAnnotationParams2(@Param("email") String email, @Param("lastName") String lastName);
List<Person> persons = personRepsotory.testQueryAnnotationParams2("aa@atguigu.com", "AA");
System.out.println(persons);
List<Person> persons = personRepsotory.testQueryAnnotationParams1("AA", "aa@atguigu.com");
System.out.println(persons);
允许占位符添加%%
//like
@Query("SELECT p FROM Person p WHERE p.lastName LIKE ?1 OR p.email LIKE ?2")
List<Person> testQueryAnnotationLikeParam(String lastName, String email);
//SpringData 允许在占位符上添加 %%.
@Query("SELECT p FROM Person p WHERE p.lastName LIKE %?1% OR p.email LIKE %?2%")
List<Person> testQueryAnnotationLikeParam(String lastName, String email);
//SpringData 也可以写成命名参数
@Query("SELECT p FROM Person p WHERE p.lastName LIKE %:lastName% OR p.email LIKE %:email%")
List<Person> testQueryAnnotationLikeParam2(@Param("email") String email, @Param("lastName") String lastName);
List<Person> persons = personRepsotory.testQueryAnnotationLikeParam("%A%", "%bb%");
System.out.println(persons.size());
List<Person> persons = personRepsotory.testQueryAnnotationLikeParam("A", "bb");
System.out.println(persons.size());
List<Person> persons = personRepsotory.testQueryAnnotationLikeParam2("bb", "A");
System.out.println(persons.size());
查询总数
//设置 nativeQuery=true 即可以使用原生的 SQL 查询
@Query(value="SELECT count(id) FROM jpa_persons", nativeQuery=true)
long getTotalCount();
long count = personRepsotory.getTotalCount();
System.out.println(count);
@Modifying 注解和事务
更新
//可以通过自定义的 JPQL 完成 UPDATE 和 DELETE 操作. 注意: JPQL 不支持使用 INSERT
//在 @Query 注解中编写 JPQL 语句, 但必须使用 @Modifying 进行修饰. 以通知 SpringData, 这是一个 UPDATE 或 DELETE 操作
//UPDATE 或 DELETE 操作需要使用事务, 此时需要定义 Service 层. 在 Service 层的方法上添加事务操作.
//默认情况下, SpringData 的每个方法上有事务, 但都是一个只读事务. 他们不能完成修改操作!
@Modifying
@Query("UPDATE Person p SET p.email = :email WHERE id = :id")
void updatePersonEmail(@Param("id") Integer id, @Param("email") String email);
@Transactional
public void updatePersonEmail(String email, Integer id){
personRepsotory.updatePersonEmail(id, email);
}
personService.updatePersonEmail("mmmm@atguigu.com", 1);
注意:
- 方法的返回值应该是 int,表示更新语句所影响的行数
- 在调用的地方必须加事务,没有事务不能正常执行
Spring Data 提供了默认的事务处理方式,即所有的查询均声明为只读事务。
对于自定义的方法,如需改变 Spring Data 提供的事务默认方式,可以在方法上注解 @Transactional 声明
进行多个 Repository 操作时,也应该使它们在同一个事务中处理,按照分层架构的思想,这部分属于业务逻辑层,因此,需要在 Service 层实现对多个 Repository 的调用,并在相应的方法上声明事务。
CrudRepository 接口
CrudRepository 接口提供了最基本的对实体类的添删改查操作
T save(T entity);//保存单个实体
Iterable<T> save(Iterable<? extends T> entities);//保存集合
T findOne(ID id);//根据id查找实体
boolean exists(ID id);//根据id判断实体是否存在
Iterable<T> findAll();//查询所有实体,不用或慎用!
long count();//查询实体数量
void delete(ID id);//根据Id删除实体
void delete(T entity);//删除一个实体
void delete(Iterable<? extends T> entities);//删除一个实体的集合
void deleteAll();//删除所有实体,不用或慎用!
public interface PersonRepsotory extends CrudRepository<Persion,Integer>{}
@Transactional
public void savePersons(List<Person> persons){
personRepsotory.save(persons);
}
@Test
public void testCrudReposiory(){
List<Person> persons = new ArrayList<>();
for(int i = 'a'; i <= 'z'; i++){
Person person = new Person();
person.setAddressId(i + 1);
person.setBirth(new Date());
person.setEmail((char)i + "" + (char)i + "@atguigu.com");
person.setLastName((char)i + "" + (char)i);
persons.add(person);
}
personService.savePersons(persons);
}
PagingAndSortingRepository接口
该接口提供了分页与排序功能
Iterable<T> findAll(Sort sort); //排序
Page<T> findAll(Pageable pageable); //分页查询(含排序功能)
分页与排序
public interface PersonRepsotory extends PagingAndSortingRepository<Person, Integer>{}
@Test
public void testPagingAndSortingRespository(){
//pageNo 从 0 开始.
int pageNo = 6 - 1;
int pageSize = 5;
//Pageable 接口通常使用的其 PageRequest 实现类. 其中封装了需要分页的信息
//排序相关的. Sort 封装了排序的信息
//Order 是具体针对于某一个属性进行升序还是降序.
Order order1 = new Order(Direction.DESC, "id");
Order order2 = new Order(Direction.ASC, "email");
Sort sort = new Sort(order1, order2);
PageRequest pageable = new PageRequest(pageNo, pageSize, sort);
Page<Person> page = personRepsotory.findAll(pageable);
System.out.println("总记录数: " + page.getTotalElements());
System.out.println("当前第几页: " + (page.getNumber() + 1));
System.out.println("总页数: " + page.getTotalPages());
System.out.println("当前页面的 List: " + page.getContent());
System.out.println("当前页面的记录数: " + page.getNumberOfElements());
}
JpaRepository接口
该接口提供了JPA的相关功能
List<T> findAll(); //查找所有实体
List<T> findAll(Sort sort); //排序、查找所有实体
List<T> save(Iterable<? extends T> entities);//保存集合
void flush();//执行缓存与数据库同步
T saveAndFlush(T entity);//强制执行持久化
void deleteInBatch(Iterable<T> entities);//删除一个实体集合
@Test
public void testJpaRepository(){
Person person = new Person();
person.setBirth(new Date());
person.setEmail("xy@atguigu.com");
person.setLastName("xyz");
person.setId(28);
Person person2 = personRepsotory.saveAndFlush(person);
System.out.println(person == person2);
}
JpaSpecificationExecutor接口
不属于Repository体系,实现一组 JPA Criteria 查询相关的方法
/**
* 目标: 实现带查询条件的分页. id > 5 的条件
*
* 调用 JpaSpecificationExecutor 的 Page<T> findAll(Specification<T> spec, Pageable pageable);
* Specification: 封装了 JPA Criteria 查询的查询条件
* Pageable: 封装了请求分页的信息: 例如 pageNo, pageSize, Sort
*/
@Test
public void testJpaSpecificationExecutor(){
int pageNo = 3 - 1;
int pageSize = 5;
PageRequest pageable = new PageRequest(pageNo, pageSize);
//通常使用 Specification 的匿名内部类
Specification<Person> specification = new Specification<Person>() {
/**
* @param *root: 代表查询的实体类.
* @param query: 可以从中可到 Root 对象, 即告知 JPA Criteria 查询要查询哪一个实体类. 还可以
* 来添加查询条件, 还可以结合 EntityManager 对象得到最终查询的 TypedQuery 对象.
* @param *cb: CriteriaBuilder 对象. 用于创建 Criteria 相关对象的工厂. 当然可以从中获取到 Predicate 对象
* @return: *Predicate 类型, 代表一个查询条件.
*/
@Override
public Predicate toPredicate(Root<Person> root,
CriteriaQuery<?> query, CriteriaBuilder cb) {
Path path = root.get("id");
Predicate predicate = cb.gt(path, 5);
return predicate;
}
};
Page<Person> page = personRepsotory.findAll(specification, pageable);
System.out.println("总记录数: " + page.getTotalElements());
System.out.println("当前第几页: " + (page.getNumber() + 1));
System.out.println("总页数: " + page.getTotalPages());
System.out.println("当前页面的 List: " + page.getContent());
System.out.println("当前页面的记录数: " + page.getNumberOfElements());
}
Specification:封装 JPA Criteria 查询条件。通常使用匿名内部类的方式来创建该接口的对象
自定义 Repository 方法
为某一个 Repository 上添加自定义方法
为所有的 Repository 都添加自实现的方法
为某一个 Repository 上添加自定义方法
步骤:
- 定义一个接口: 声明要添加的, 并自实现的方法
- 提供该接口的实现类: 类名需在要声明的 Repository 后添加 Impl, 并实现方法
- 声明 Repository 接口, 并继承 1) 声明的接口
- 使用.
注意: 默认情况下, Spring Data 会在 base-package 中查找 “接口名Impl” 作为实现类. 也可以通过 repository-impl-postfix 声明后缀.
public interface PersonDao {
void test();
}
public interface PersonRepsotory extends PersonDao{}
public class PersonRepsotoryImpl implements PersonDao {
@PersistenceContext
private EntityManager entityManager;
@Override
public void test() {
Person person = entityManager.find(Person.class, 11);
System.out.println("-->" + person);
}
}
public void testCustomRepositoryMethod(){
personRepsotory.test();
}
为所有的 Repository 都添加自实现的方法
步骤:
声明一个接口, 在该接口中声明需要自定义的方法, 且该接口需要继承 Spring Data 的 Repository.
提供 1) 所声明的接口的实现类. 且继承 SimpleJpaRepository, 并提供方法的实现
定义 JpaRepositoryFactoryBean 的实现类, 使其生成 1) 定义的接口实现类的对象
修改
注意: 全局的扩展实现类不要用 Imp 作为后缀名, 或为全局扩展接口添加 @NoRepositoryBean 注解告知 Spring Data: Spring Data 不把其作为 Repository

